SCUMM(Severalnines ClusterControl Unified Monitoring&Management)は、データベースノードにエージェントがインストールされたエージェントベースのソリューションです。一連の監視ダッシュボードを提供します。このダッシュボードには、弾力性のあるクエリ言語と多次元データモデルを備えたデータストアとしてPrometheusがあります。 Prometheusは、データベースホストで実行されているエクスポーターからメトリックデータを取得します。
ClusterControl SCUMMアーキテクチャは、MySQL、Galera Cluster、PostgreSQL、およびProxySQLの監視機能を拡張するバージョン1.7.0で導入されました。
新しいClusterControl1.7.1は、MongoDBシステムの高解像度モニタリングを追加します。
 ClusterControlMongoDBダッシュボードリスト
ClusterControlMongoDBダッシュボードリスト この記事では、MongoDB環境の2つの主要なダッシュボードについて説明します。 MongoDBサーバーとMongoDBレプリカセット。
ダッシュボードとメトリックのリスト
ダッシュボードとその指標のリスト:
| MongoDBサーバー | |
|---|---|
| 名前 ReplSet名 サーバーの稼働時間 OpsCounters 接続 WT-同時チケット(読み取り) WT-同時チケット(書き込み) WT-キャッシュ グローバルロック アサート |
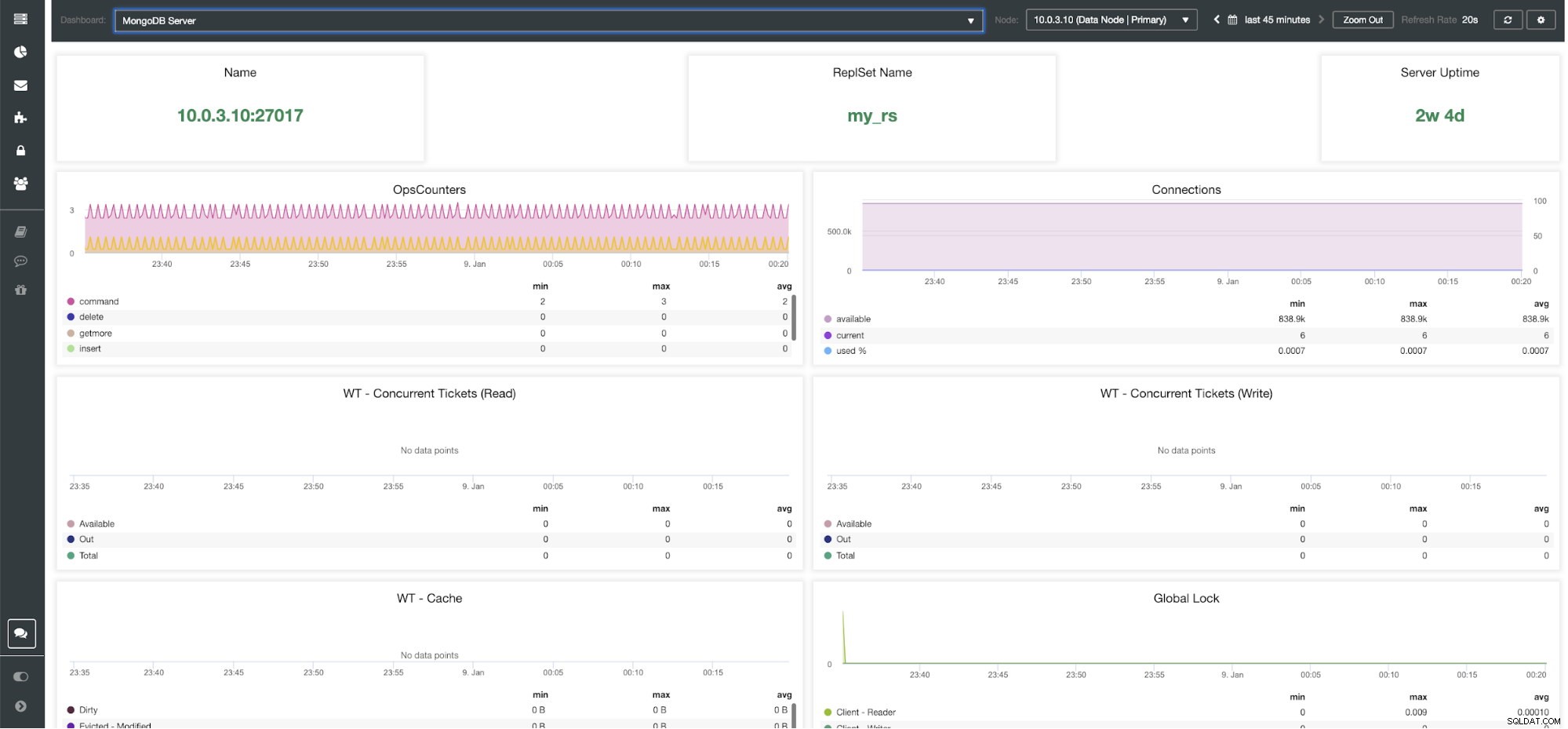 ClusterControlMongoDBサーバーダッシュボード
ClusterControlMongoDBサーバーダッシュボード| MongoDB ReplicaSet | |
|---|---|
| ReplSetサイズ ReplSet名 PRIMARY サーバーバージョン レプリカセットとメンバー ReplSetごとのOplogウィンドウ レプリケーションヘッドルーム 合計ReplSetごとにオンラインでプライマリ/セカンダリ ReplSetごとにカーソルを開く ReplSet-セットごとにタイムアウトしたカーソル ReplSetごとの最大レプリケーションラグ Oplogサイズ OpsCounters PRIMARY(s)からセットメンバーをレプリカするためのping時間 |
 ClusterControlMongoDBレプリカセットダッシュボード
ClusterControlMongoDBレプリカセットダッシュボード データベースシステムはOSリソースに大きく依存しているため、MongoDB環境のシステム概要とクラスター概要用の2つの追加ダッシュボードもあります。
| システムの概要 | |
|---|---|
| サーバーの稼働時間 CPUコア 合計RAM 平均負荷 CPU使用率 RAM使用率 ディスクスペース使用量 ネットワーク使用量 ディスクIOPS ディスクIO使用率% ディスクスループット |
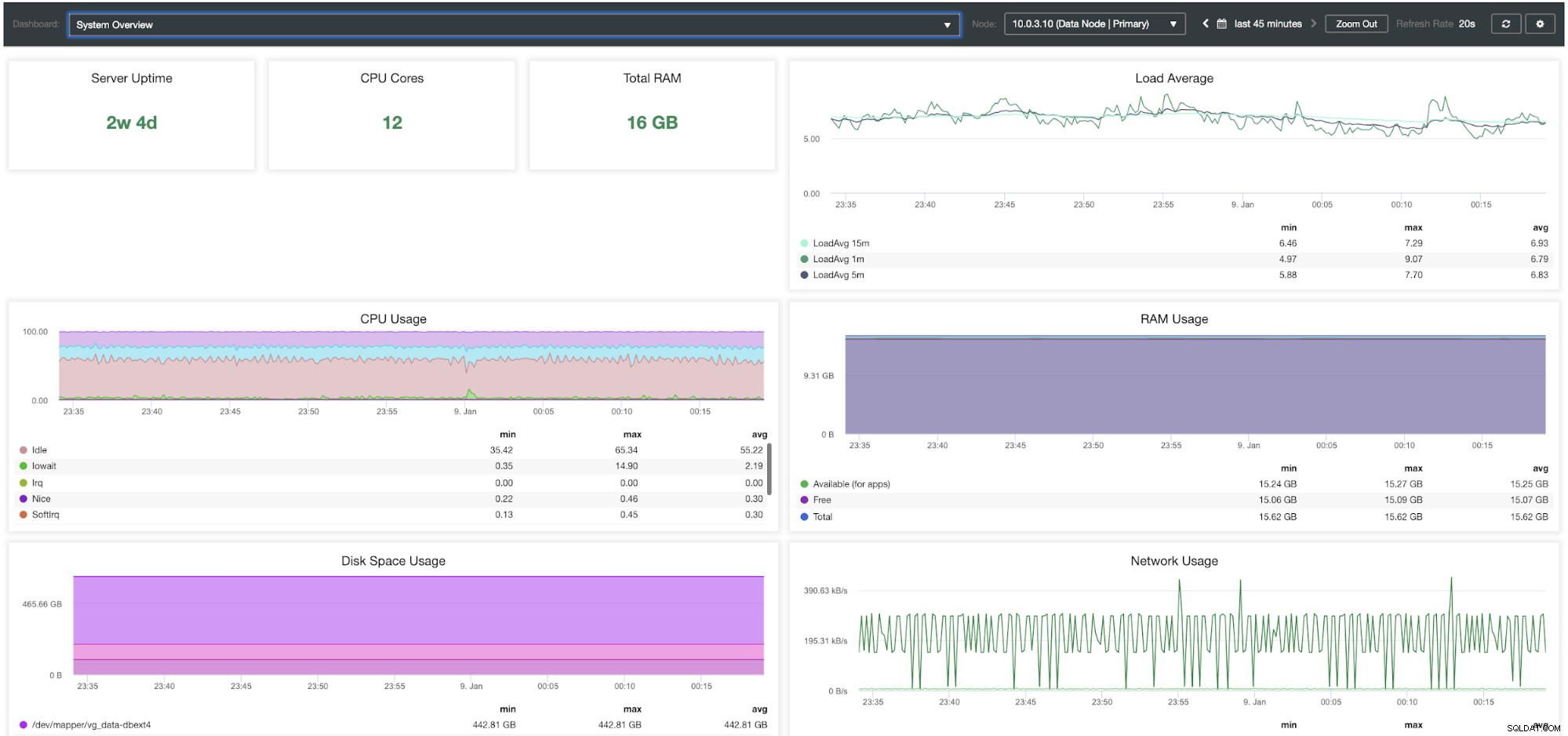 ClusterControlシステム概要ダッシュボード
ClusterControlシステム概要ダッシュボード| クラスター概要 | |
|---|---|
| 負荷平均1m 負荷平均5m 負荷平均15m アプリケーションで使用可能なメモリ ネットワークTX ネットワークRX ディスク読み取りIOPS ディスク書き込みIOPS ディスク書き込み+読み取りIOPS |
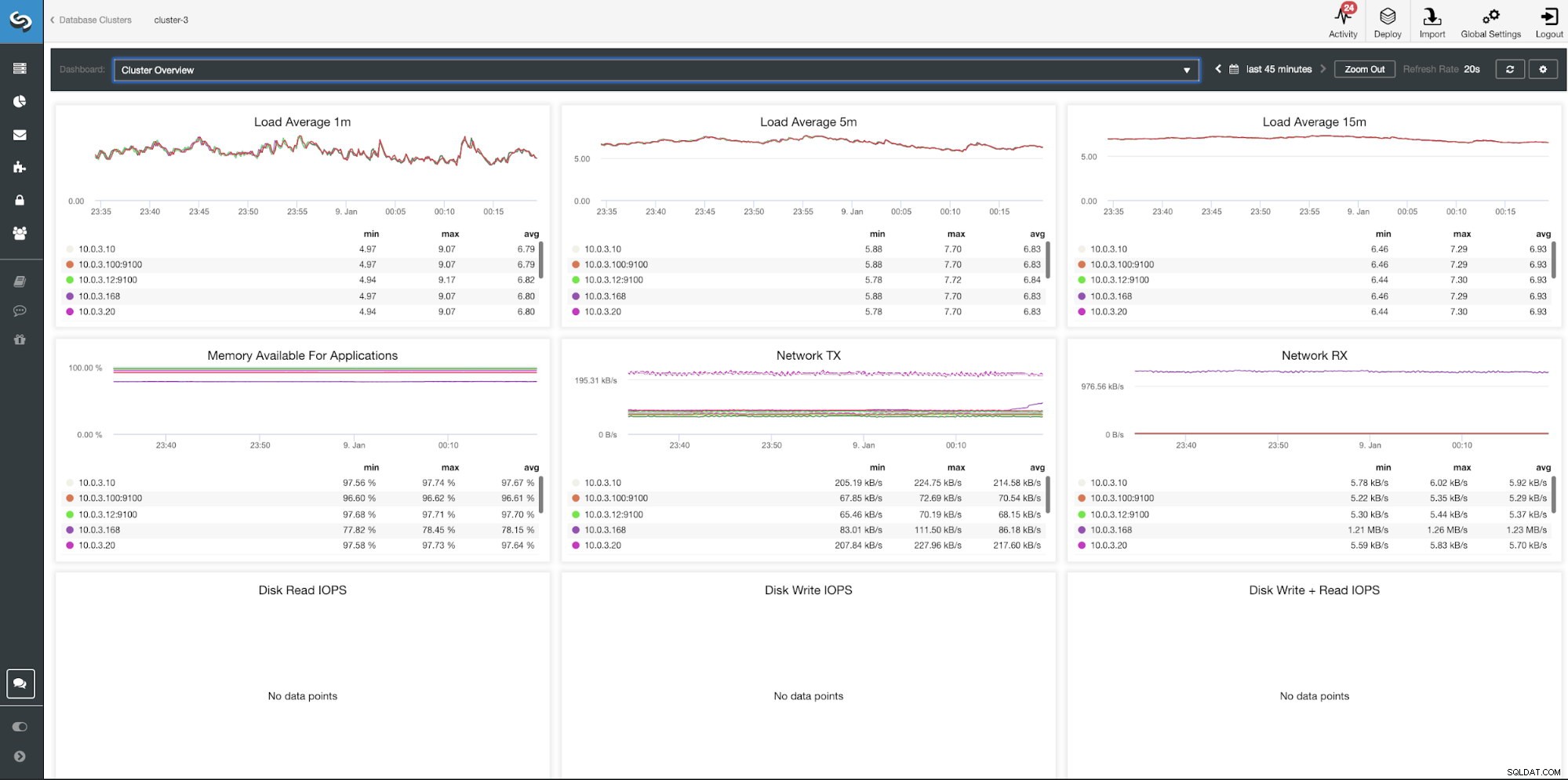 ClusterControlクラスターの概要ダッシュボード
ClusterControlクラスターの概要ダッシュボード MongoDBサーバーダッシュボード
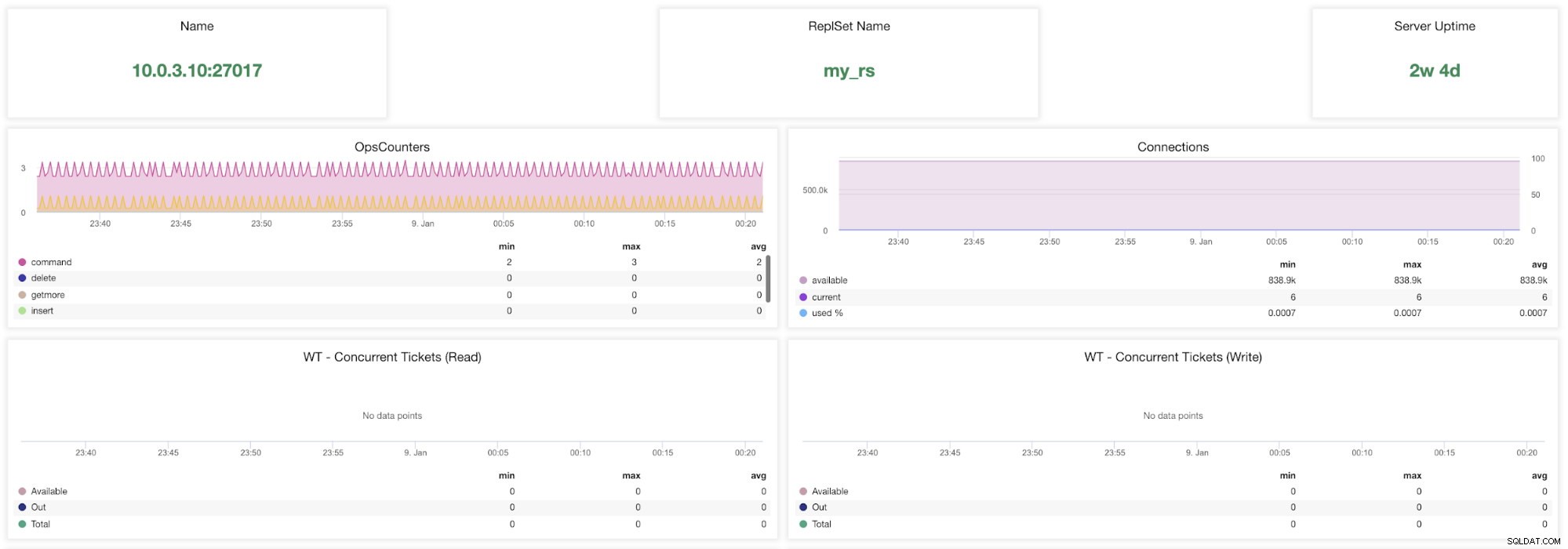 ClusterControlMongoDBメトリック
ClusterControlMongoDBメトリック 名前 -サーバーアドレスとポート。
ReplsSet名 -サーバーが属するレプリカセットの名前を示します。
サーバーの稼働時間 -最後にサーバーを再起動してからの時間。
Ops Couters -選択した期間中に受信したリクエストの数を、操作のタイプ別に分類します。これらのカウントには、成功しなかった操作を含む、受信したすべての操作が含まれます。
接続 -このグラフは、監視する最も重要なメトリックの1つを示しています-失敗した要求を含む、選択した期間中に受信した接続の数。異常なトラフィック負荷は、パフォーマンスの問題につながる可能性があります。 MongoDBの接続が少なくなると、着信リクエストをタイムリーに処理できない可能性があります。
WT-同時チケット(読み取り)/ WT-同時チケット(書き込み) これらの2つのグラフは、WiredTiger(WT)の同時実行性を制御する読み取りおよび書き込みチケットを示しています。 WTチケットは、ストレージエンジンで同時に実行できる読み取りおよび書き込み操作の数を制御します。使用可能な読み取りおよび書き込みチケットがゼロに低下すると、同時に実行される操作の数は、構成された読み取り/書き込み値と等しくなります。つまり、他の操作は、実行中のスレッドの1つがストレージエンジンでの作業を終了するまで待機してから実行する必要があります。
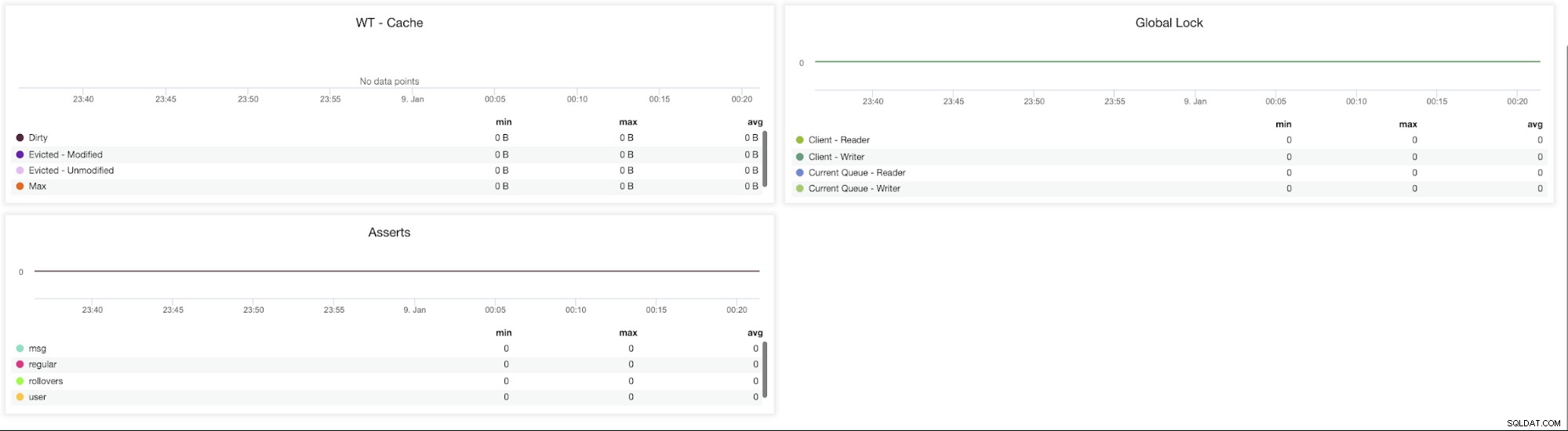 ClusterControlMongoDBメトリック
ClusterControlMongoDBメトリック WT-キャッシュ (ダーティ、削除済み-変更済み、削除済み-変更なし、最大)-キャッシュのサイズは、WiredTigerにとって最も重要な単一のノブです。デフォルトでは、MongoDB 3.xは使用可能なメモリの50%(3.2では60%)をデータキャッシュ用に予約します。
グローバルロック (クライアント-読み取り、クライアント-書き込み、現在のキュー-リーダー、現在のキュー-ライター)-スキーマデザインパターンが不十分であるか、多くのクライアントからの読み取りおよび書き込み要求が多いと、大規模なロックが発生する可能性があります。これが発生した場合、一貫性を維持し、書き込みの競合を回避する必要があります。
これを実現するために、MongoDBはマルチ粒度ロックを使用して、グローバル、データベース、コレクションレベルなどのさまざまなレベルでロック操作を実行できるようにします。 。
アサート (msg、regular、rollovers、user)-このグラフは、1秒ごとに発生するアサートの数を示しています。高い値と傾向からの逸脱を確認する必要があります。
MongoDBReplicaSetダッシュボード
このダッシュボードに表示される指標は、レプリカセットを使用する場合にのみ重要です。
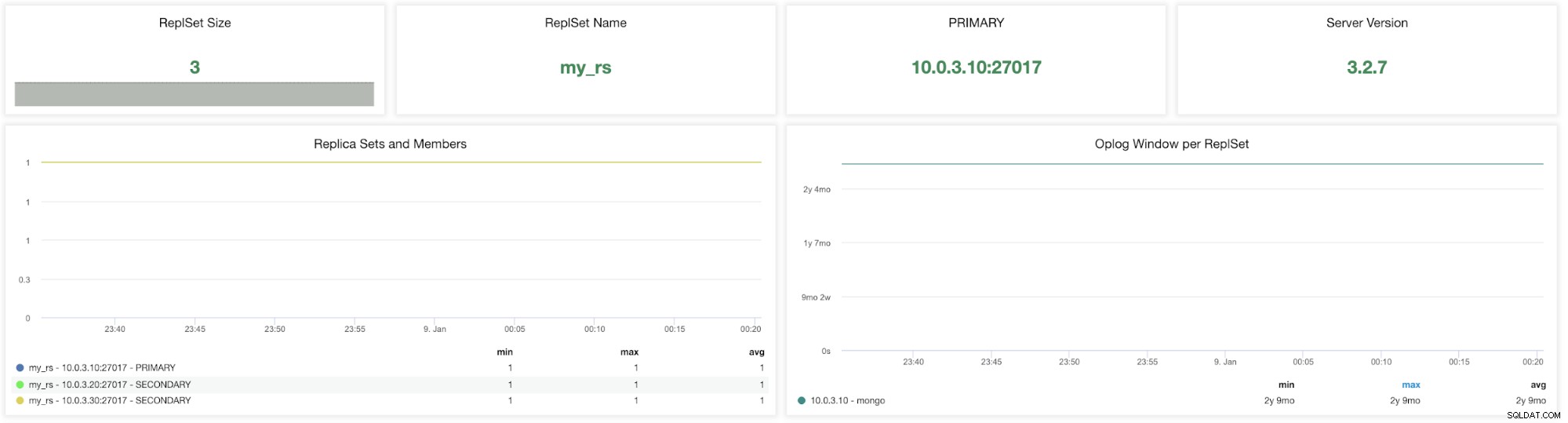 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics ReplicaSetサイズ -レプリカセット内のメンバーの数。実動システムの標準レプリカ・セットのデプロイメントは、3メンバーのレプリカ・セットです。一般的に、レプリカセットには奇数の投票メンバーを含めることをお勧めします。レプリカセットのフォールトトレランスは、使用できなくなり、プライマリを選択するのに十分な数のメンバーをセットに残すことができるメンバーの数です。 3つのメンバーのフォールトトレランスは1つ、5つは2つなどです。
ReplSet名 -これは、MongoDB構成ファイルで割り当てられた名前です。名前は/etc/mongod.confreplSet値を参照しています。
プライマリ -プライマリノードはすべての書き込み操作を受け取り、データセットに対する他のすべての変更を操作ログに記録します。値は、MongoDBレプリカセットクラスター内のプライマリノードのIPとポートを識別することです。
サーバーバージョン -サーバーのバージョンを特定します。 ClusterControlバージョン1.7.1は、MongoDBバージョン3.2 / 3.4 / 3.6/4.0をサポートしています。
レプリカセットとメンバー (最小、最大、平均)-このグラフは、期間中のアクティブなメンバーを識別するのに役立ちます。プライマリノードとセカンダリノードの最小数、最大数、平均数、およびこれらの数が時間の経過とともにどのように変化したかを追跡できます。逸脱すると、フォールトトレランスとクラスターの可用性に影響を与える可能性があります。
ReplSetごとのOplogウィンドウ -レプリケーションウィンドウは、監視する必要のある重要な指標です。 MongoDB oplogは、(プリセット)サイズが制限されている単一のコレクションです。これは、oplog.rsの最初と最後のタイムスタンプの違いとして説明できます。これは、インスタンスを同期するために初期同期が必要になる前に、セカンダリがオフラインになることができる時間です。これらの指標は、次のトランザクションがoplogから削除されるまでの残り時間を示します。
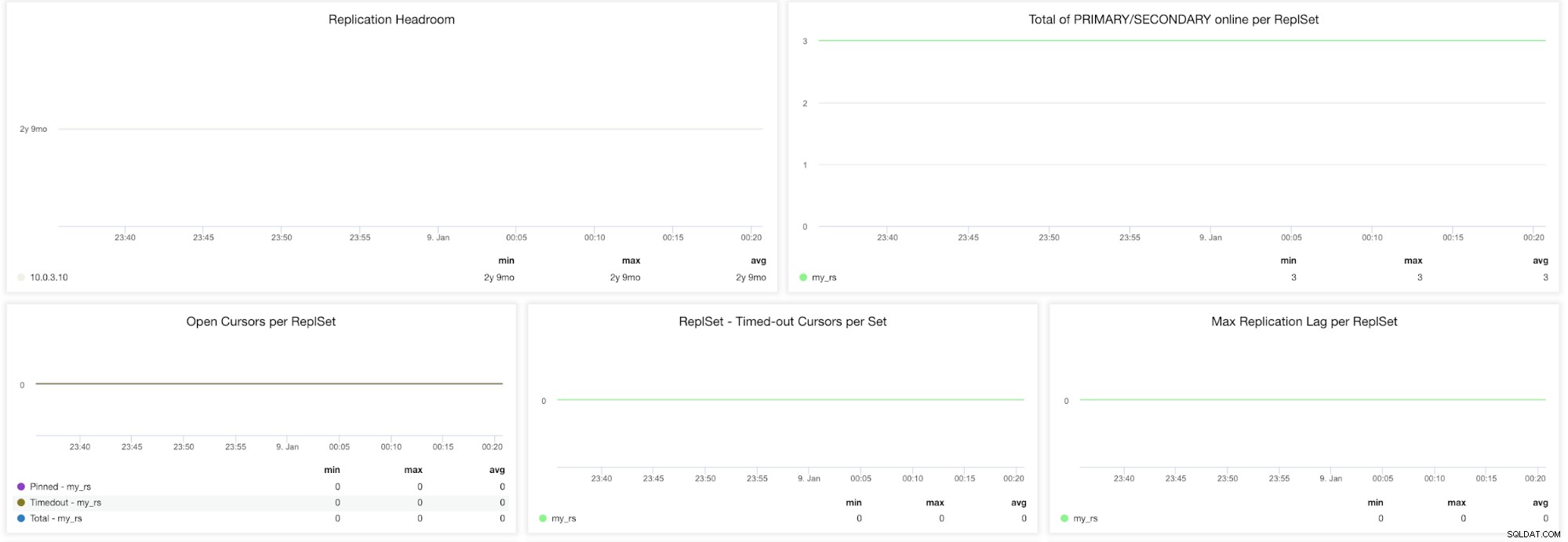 ClusterControl MongoDB ReplicaSet Metrics
ClusterControl MongoDB ReplicaSet Metrics レプリケーションヘッドルーム -このグラフは、プライマリのoplogウィンドウとセカンダリノードのレプリケーションラグの違いを示しています。 MongoDB oplogのサイズには制限があり、ノードの遅延が大きすぎると、追いつくことができません。これが発生した場合、完全同期が発行されます。これはコストのかかる操作であり、常に回避する必要があります。
ReplSetごとのオンラインのPRIMARY/SECONDARYの合計 -期間中のクラスターノードの総数。
ReplSetごとにカーソルを開く(ピン留め、タイムアウト、合計) -読み取り要求には、結果のデータセットへのポインターであるカーソルが付属しています。サーバー上で開いたままになるため、デフォルトのMongoDB設定で終了しない限り、メモリを消費します。非アクティブなカーソルを識別し、それらを切り取ってメモリを節約する必要があります。
ReplSet -SetsあたりのタイムアウトカーソルReplSetあたりの最大レプリケーションラグ-セカンダリを追加して読み取りをスケールアウトする場合は、レプリケーションラグを監視することが非常に重要です。 MongoDBは、これらのセカンダリがそれほど遅れていない場合にのみ、これらのセカンダリを使用します。セカンダリにレプリケーションの遅延がある場合、プライマリですでに上書きされている古いデータを提供するリスクがあります。
OplogSize -特定のワークロードでは、より大きなoplogサイズが必要になる場合があります。一度に複数のドキュメントを更新します。削除は、挿入と同じ量のデータ、またはインプレース更新のかなりの数に相当します。
OpsConters -このグラフは、クエリの実行回数を示しています。
プライマリからレプリカセットメンバーへのping時間 -これにより、プライマリノードからダウンしているか到達できないレプリカセットメンバーを検出できます。
閉会の辞
新しいClusterControl1.7.1MongoDBダッシュボード機能は、CommunityEditionで無料で利用できます。データベース運用チームは、特に根本原因分析やキャパシティプランニングとして日常業務を実行する場合に、高解像度のグラフを使用することで利益を得ることができます。
ワンクリックで新しい監視エージェントを導入できます。 ClusterControlは、Prometheusエージェントをインストールし、メトリックを構成し、GUIを介してPrometheusエクスポーター構成へのアクセスを維持するため、エクスポーター(Prometheus)のコレクターフラグなどのパラメーター構成をより適切に管理できます。
読み取りおよび書き込み要求の数を適切に監視することで、リソースの過負荷を防ぎ、潜在的な過負荷の原因をすばやく見つけ、いつスケールアップするかを知ることができます。