データベースの効率は、最も重要なパラメーターの微調整に依存するだけでなく、関連するコレクションでの適切なデータ表示にも依存します。最近、ソーシャルチャットアプリケーションを開発するプロジェクトに取り組みましたが、数日間のテストの後、データベースからデータを取得するときに多少の遅れが見られました。ユーザーがそれほど多くなかったため、データベースパラメータの調整を除外し、クエリに焦点を合わせて根本的な原因を突き止めました。
驚いたことに、特定の情報を取得するための読み取りリクエストが1つ以上あるという点で、データ構造が完全に適切ではないことに気付きました。
アプリケーションセクションを配置する方法の概念モデルは、データベースコレクションの構造に大きく依存します。たとえば、ソーシャルアプリにログインすると、データベースプレゼンテーションから示されるように、アプリケーションの設計に従ってデータがさまざまなセクションに送られます。
一言で言えば、適切に設計されたデータベースの場合、次のセクションで説明するように、スキーマ構造とコレクションの関係は、データベースの速度と整合性を向上させるための重要な要素です。
データをモデル化する際に考慮すべき要素について説明します。
データモデリングとは
データモデリングは通常、データベース内のデータアイテムの分析であり、それらがそのデータベース内の他のオブジェクトとどのように関連しているかを分析します。
たとえば、MongoDBでは、ユーザーコレクションとプロファイルコレクションを作成できます。ユーザーコレクションには特定のアプリケーションのユーザー名が一覧表示されますが、プロファイルコレクションには各ユーザーのプロファイル設定がキャプチャされます。
データモデリングでは、各ユーザーを対応するプロファイルに接続するための関係を設計する必要があります。一言で言えば、データモデリングは、オブジェクト指向プログラミングのアーキテクチャ基盤を形成するだけでなく、データベース設計の基本的なステップです。また、開発の進行中に物理アプリケーションがどのように見えるかについての手がかりも提供します。アプリケーションとデータベースの統合アーキテクチャは、次のように説明できます。
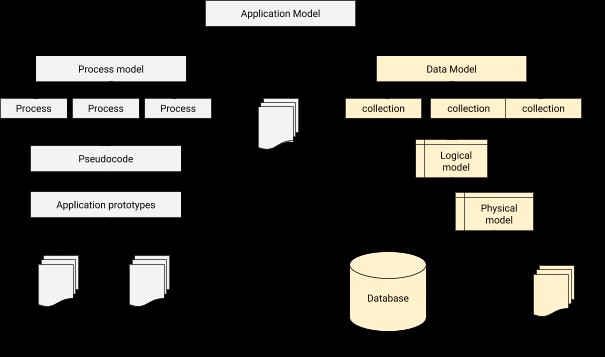
MongoDBでのデータモデリングのプロセス
データモデリングにはデータベースのパフォーマンスが向上していますが、次のような考慮事項があります。
- データ取得パターン
- クエリ、更新、データ処理など、アプリケーションのニーズのバランスをとる
- 選択したデータベースエンジンのパフォーマンス機能
- データ自体の固有の構造
MongoDBドキュメント構造
MongoDBのドキュメントは、特定のデータセットに適用する手法を決定する際に主要な役割を果たします。データ間には通常、次の2つの関係があります。
- 埋め込みデータ
- 参照データ
埋め込みデータ
この場合、関連データは、フィールド値またはドキュメント自体内の配列として単一のドキュメント内に格納されます。このアプローチの主な利点は、データが非正規化されるため、単一のデータベース操作で関連データを操作する機会が提供されることです。その結果、これによりCRUD操作の実行速度が向上し、必要なクエリが少なくなります。以下のドキュメントの例を考えてみましょう:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}この一連のデータには、名前とその他の追加情報を持つ学生がいます。 Settingsフィールドにはオブジェクトが埋め込まれており、さらにplaceLocationフィールドにも緯度と経度の構成を持つオブジェクトが埋め込まれています。この学生のすべてのデータは、1つのドキュメントに含まれています。この学生のすべての情報を取得する必要がある場合は、次のコマンドを実行します:
db.students.findOne({StudentName : "George Beckonn"})埋め込みの強み
- データアクセス速度の向上:データへのアクセス速度を向上させるには、1回のクエリ操作で指定されたドキュメント内のデータを1回のデータベース検索で操作できるため、埋め込みが最適なオプションです。
- データの不整合の低減:操作中に問題が発生した場合(ネットワークの切断や電源障害など)、基準によって1つのドキュメントが選択されることが多いため、影響を受けるドキュメントの数はわずかです。
- CRUD操作を削減しました。つまり、読み取り操作は実際には書き込みよりも多くなります。また、1回のアトミック書き込みで関連データを更新することができます。つまり、上記のデータの場合、電話番号を更新し、次の1つの操作で距離を増やすこともできます:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
埋め込みの弱点
- 制限されたドキュメントサイズ。 MongoDBのすべてのドキュメントは、16メガバイトのBSONサイズに制限されています。したがって、全体的なドキュメントサイズと埋め込みデータはこの制限を超えてはなりません。そうしないと、MMAPv1などの一部のストレージエンジンでは、書き込みパフォーマンスが低下した結果、データが大きくなり、データが断片化する可能性があります。
- データの重複:同じデータの複数のコピーを使用すると、複製されたデータのクエリが難しくなり、埋め込まれたドキュメントのフィルタリングに時間がかかる可能性があるため、埋め込みの主な利点を上回ります。
ドット表記
ドット表記は、プログラミング部分に埋め込まれたデータの識別機能です。埋め込みフィールドまたは配列の要素にアクセスするために使用されます。上記のサンプルデータでは、ドット表記を使用したこのクエリで、場所が「大使館」である学生の情報を返すことができます。
db.users.find({'Settings.location': 'Embassy'})参照データ
この場合のデータ関係は、関連データが異なるドキュメント内に格納されていることですが、これらの関連ドキュメントへの参照リンクが発行されます。上記のサンプルデータの場合、次のように再構築できます。
ユーザードキュメント
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}設定ドキュメント
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}2つの異なるドキュメントがありますが、それらは_idフィールドとidフィールドの同じ値によってリンクされています。したがって、データモデルは正規化されます。ただし、関連ドキュメントの情報にアクセスするには、追加のクエリを発行する必要があるため、実行時間が長くなります。たとえば、ParentPhoneと関連する距離設定を更新する場合、少なくとも3つのクエリがあります。
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})参照の強み
- データの一貫性。すべてのドキュメントについて、標準形が維持されているため、データの不整合が発生する可能性はかなり低くなります。
- データの整合性が向上しました。正規化により、操作期間の長さに関係なくデータを簡単に更新できるため、混乱を招くことなく、すべてのドキュメントの正しいデータを確保できます。
- キャッシュ使用率の向上。頻繁にアクセスされる正規のドキュメントは、数回アクセスされる埋め込みドキュメントではなく、キャッシュに保存されます。
- 効率的なハードウェア使用率。ドキュメントの拡張につながる可能性のある埋め込みとは異なり、参照はドキュメントの拡張を促進しないため、ディスクとRAMの使用量が削減されます。
- 特に大量のサブドキュメントで柔軟性が向上しました。
- 書き込みが速くなります。
参照の弱点
- 複数のルックアップ:基準に一致する多数のドキュメントをルックアップする必要があるため、ディスクから取得する際の読み取り時間が長くなります。さらに、これによりキャッシュミスが発生する可能性があります。
- いくつかの操作を実行するために多くのクエリが発行されるため、正規化されたデータモデルでは、特定の操作を完了するためにサーバーへのラウンドトリップがさらに必要になります。
データの正規化
データの正規化とは、データの整合性を向上させ、データの冗長性のイベントを減らすために、いくつかの通常の形式に従ってデータベースを再構築することを指します。
データモデリングは、次の2つの主要な正規化手法を中心に展開します。
-
正規化されたデータモデル
参照データに適用されるように、正規化はデータを複数のコレクションに分割し、新しいコレクション間の参照を使用します。単一のドキュメント更新が他のコレクションに発行され、それに応じて一致するドキュメントに適用されます。これにより、効率的なデータ更新表現が提供され、頻繁に変更されるデータに一般的に使用されます。
-
非正規化データモデル
データには埋め込みドキュメントが含まれているため、読み取り操作が非常に効率的になります。ただし、ディスクスペースの使用量が増え、同期を維持するのが困難になります。非正規化の概念は、データがあまり頻繁に変更されないサブドキュメントにうまく適用できます。
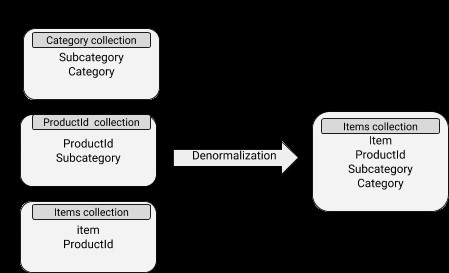
MongoDBスキーマ
スキーマは基本的に、フィールドの輪郭が描かれたスケルトンであり、各フィールドが特定のデータセットに対して保持する必要のあるデータ型です。 SQLの観点を考慮すると、すべての行は同じ列を持つように設計されており、各列は定義されたデータ型を保持する必要があります。ただし、MongoDBには、デフォルトで柔軟なスキーマがあり、すべてのドキュメントで同じ適合性を保持しているわけではありません。
柔軟なスキーマ
MongoDBの柔軟なスキーマでは、コレクション内のドキュメント間でフィールドが異なる可能性があるため、ドキュメントが必ずしも同じフィールドまたはデータ型である必要はないことを定義しています。この概念の主な利点は、新しいフィールドを追加したり、既存のフィールドを削除したり、フィールド値を新しいタイプに変更したりして、ドキュメントを新しい構造に更新できることです。
たとえば、次の2つのドキュメントを同じコレクションに含めることができます。
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}最初のドキュメントには年齢フィールドがありますが、2番目のドキュメントには年齢フィールドがありません。さらに、ParentPhoneフィールドのデータ型は数値ですが、2番目のドキュメントではブール型であるfalseに設定されています。
スキーマの柔軟性により、ドキュメントのオブジェクトへのマッピングが容易になり、各ドキュメントは、表現されたエンティティのデータフィールドと一致する可能性があります。
リジッドスキーマ
これらのドキュメントは互いに異なる可能性があると述べたように、厳密なスキーマを作成することを決定する場合があります。厳密なスキーマは、コレクション内のすべてのドキュメントが同じ構造を共有することを定義します。これにより、挿入および更新操作中のデータの整合性を向上させる方法として、いくつかのドキュメント検証ルールを設定する機会が増えます。
スキーマデータ型
mongooseなどのMongoDB用のサーバードライバーを使用する場合、データ検証を実行できるデータ型がいくつか提供されています。基本的なデータ型は次のとおりです。
- 文字列
- 番号
- ブール値
- 日付
- バッファ
- ObjectId
- 配列
- 混合
- Decimal128
- 地図
以下のサンプルスキーマをご覧ください
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});ユースケースの例
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);スキーマ検証
アプリケーション側からデータ検証を実行できる限り、サーバー側からも検証を実行することをお勧めします。これは、スキーマ検証ルールを採用することで実現しています。
これらのルールは、挿入および更新操作中に適用されます。これらは通常、作成プロセス中にコレクションベースで宣言されます。ただし、バリデーターオプションを指定したcollModコマンドを使用して、既存のコレクションにドキュメント検証ルールを追加することもできますが、これらのルールは、更新が適用されるまで既存のドキュメントに適用されません。
同様に、コマンドdb.createCollection()を使用して新しいコレクションを作成する場合、バリデーター・オプションを発行できます。学生向けのコレクションを作成するときは、この例を見てください。バージョン3.6以降、MongoDBはJSONスキーマ検証をサポートしているため、必要なのは$jsonSchema演算子を使用することだけです。
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})このスキーマ設計では、次のような新しいドキュメントを挿入しようとすると、次のようになります。
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})指定された年の値が指定された制限内にないなど、検証ルールに違反しているため、コールバック関数は以下のエラーを返します。
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})さらに、$ where、$ text、near、$ nearSphere以外のクエリ演算子を使用して、検証オプションにクエリ式を追加できます。つまり、
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )スキーマ検証レベル
前述のように、通常、検証は書き込み操作に対して発行されます。
ただし、検証は既存のドキュメントにも適用できます。
検証には3つのレベルがあります:
- 厳密:これはデフォルトのMongoDB検証レベルであり、すべての挿入と更新に検証ルールを適用します。
- 中程度:検証ルールは、挿入、更新、および検証基準を満たす既存のドキュメントにのみ適用されます。
- オフ:このレベルでは、特定のスキーマの検証ルールがnullに設定されるため、ドキュメントに対して検証は行われません。
例:
以下のデータをクライアントコレクションに挿入しましょう。
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]次を使用して中程度の検証レベルを適用する場合:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )検証ルールは、すべての基準に一致するため、_idが1のドキュメントにのみ適用されます。
2番目のドキュメントでは、検証ルールが発行された基準を満たしていないため、ドキュメントは検証されません。
スキーマ検証アクション
ドキュメントの検証を行った後、検証ルールに違反する可能性があるものがあるかもしれません。これが発生した場合は、常にアクションを提供する必要があります。
MongoDBは、検証ルールに失敗したドキュメントに発行できる2つのアクションを提供します。
- エラー:これはデフォルトのMongoDBアクションであり、検証基準に違反した場合に挿入または更新を拒否します。
-
警告:このアクションは違反をMongoDBログに記録しますが、挿入または更新操作を完了できます。例:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })このようなドキュメントを挿入しようとすると:
db.students.insert( { name: "Amanda", status: "Updated" } );gpaは、スキーマデザインの必須フィールドであるにもかかわらず欠落していますが、検証アクションが警告に設定されているため、ドキュメントが保存され、エラーメッセージがMongoDBログに記録されます。
>