1つのクエリで複数のJOINS
通常、複数のJOINは複数のコレクションに関連付けられていますが、INNER JOINがどのように機能するかについての基本的な理解が必要です(このトピックに関する以前の投稿を参照してください)。以前に持っていた2つのコレクションに加えて;ユニットと学生の場合、3つ目のコレクションを追加して、スポーツというラベルを付けましょう。スポーツコレクションに以下のデータを入力します:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}たとえば、_idフィールド値が1の学生のすべてのデータを返したいと考えています。通常、学生コレクションから_idフィールド値をフェッチするクエリを作成し、その戻り値を使用してクエリを実行します。他の2つのコレクションのデータ。したがって、特に大量のドキュメントが含まれる場合、これは最良のオプションではありません。より良いアプローチは、Studio3TプログラムのSQL機能を使用することです。通常のSQLの概念を使用してMongoDBにクエリを実行し、結果のMongoシェルコードを仕様に合わせて粗調整することができます。たとえば、すべてのコレクションから_idが1に等しいすべてのデータをフェッチしましょう:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;結果のドキュメントは次のようになります:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}[クエリコード]タブから、対応するMongoDBコードは次のようになります。
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);返されたドキュメントを調べてみると、個人的には、特に埋め込みドキュメントのデータ構造にはあまり満足していません。ご覧のとおり、返される_idフィールドがあり、ユニットの場合、成績フィールドをユニット内に埋め込む必要がない場合があります。
他のフィールドではなく、ユニットが埋め込まれたユニットフィールドが必要です。これは、粗調整部分につながります。以前の投稿と同様に、提供されたコピーアイコンを使用してコードをコピーし、集計ペインに移動し、貼り付けアイコンを使用してコンテンツを貼り付けます。
まず最初に、$ match演算子を最初のステージにする必要があるため、最初の位置に移動して、次のようにします。
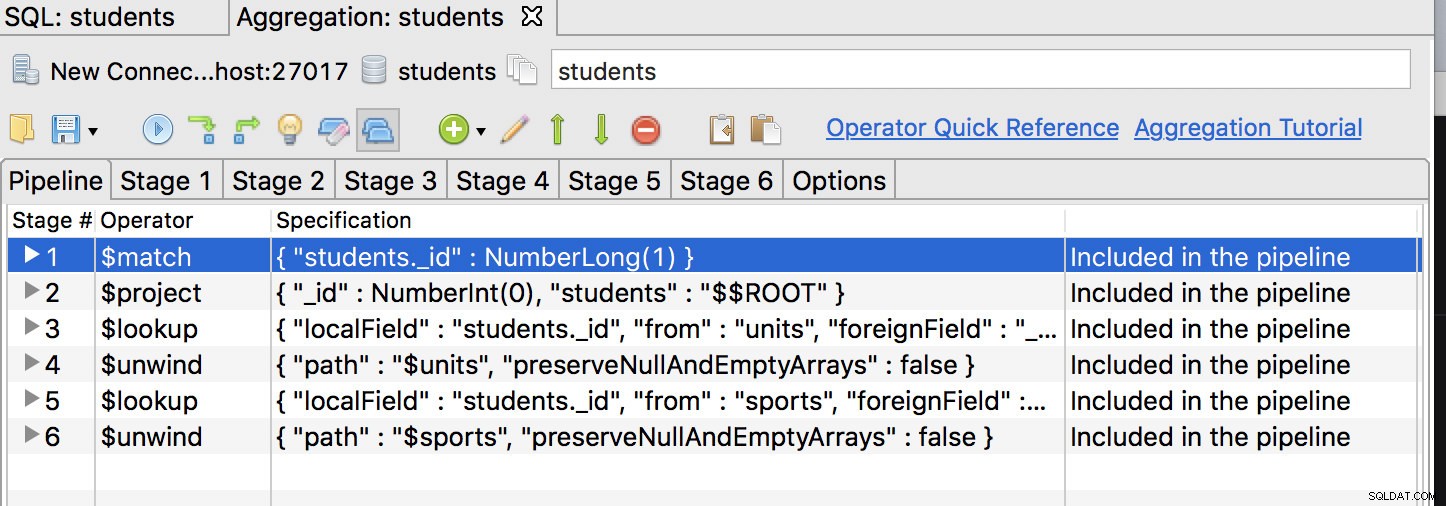
[最初のステージ]タブをクリックして、クエリを次のように変更します。
{
"_id" : NumberLong(1)
}次に、クエリをさらに変更して、データの多くの埋め込み段階を削除する必要があります。そのために、削除するフィールドのデータをキャプチャするための新しいフィールドを追加します。例:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);ご覧のとおり、微調整プロセスでは、以前の集計パイプラインの内容を埋め込みフィールドとしてのグレードで上書きする新しいフィールドユニットを導入しました。さらに、_idフィールドを作成して、データがコレクション内の同じ値のドキュメントに関連していることを示しています。 $ projectの最後の段階では、スポーツドキュメントの_idフィールドを削除して、以下のようにデータを適切に表示できるようにします。
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}SQLの観点から返されるフィールドを制限することもできます。たとえば、以下のコードを使用して、学生の名前、この学生が行っているユニット、複数のJOINSを使用してプレイされたトーナメントの数を返すことができます。
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;これは私たちに最も適切な結果を与えません。したがって、通常どおり、コピーして集計ペインに貼り付けます。適切な結果を得るために、以下のコードで微調整します。
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);SQL JOINの概念によるこの集計結果により、以下に示すすっきりとした見栄えのするデータ構造が得られます。
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}とても簡単ですよね?データは、単一のドキュメントとして単一のコレクションに保存されているかのように、非常に見栄えがします。
左外側の結合
LEFT OUTER JOINは通常、最も描写されている関係に準拠していないドキュメントを表示するために使用されます。結果として得られるLEFTOUTER結合のセットには、INNER JOIN結果セットと同じように、WHERE句の条件を満たす両方のコレクションのすべての行が含まれます。さらに、右側のコレクションに一致するドキュメントがない左側のコレクションのドキュメントも結果セットに含まれます。右側のテーブルから選択されているフィールドは、NULL値を返します。ただし、左側のコレクションの一致基準がない右側のコレクションのドキュメントは返されません。
これらの2つのコレクションを見てください:
学生
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}ユニット
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}学生コレクションでは、_idフィールド値を3に設定していませんが、ユニットコレクションでは設定しています。同様に、unitsコレクションには_idフィールド値4はありません。以下のクエリを使用して、JOINアプローチの左側のオプションとしてstudentsコレクションを使用する場合:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idこのコードを使用すると、次の結果が得られます。
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}ユニットコレクションに一致するドキュメントがなかったため、2番目のドキュメントにはユニットフィールドがありません。このSQLクエリの場合、対応するMongoコードは
になります。db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);もちろん、微調整について学習したので、先に進んで集計パイプラインを再構築し、希望する最終結果に合わせることができます。 SQLは、データベース管理に関する限り、非常に強力なツールです。それ自体は幅広いテーマです。IN句とGROUPBY句を使用して、MongoDBの対応するコードを取得し、それがどのように機能するかを確認することもできます。
結論
慣れ親しんだテクノロジーに加えて、新しい(データベース)テクノロジーに慣れるには、かなりの時間がかかる場合があります。リレーショナルデータベースは、非リレーショナルデータベースよりもまだ一般的です。それにもかかわらず、MongoDBの導入により、状況は変化し、関連する強力なパフォーマンスのために、人々はできるだけ早くMongoDBを学びたいと考えています。
MongoDBを最初から学ぶのは少し面倒ですが、SQLの知識を使用して、MongoDBのデータを操作し、相対的なMongoDBコードを取得し、それを微調整して最も適切な結果を得ることができます。これを強化するために利用できるツールの1つは、Studio3Tです。複雑なデータの操作を容易にする2つの重要な機能、つまりSQLクエリ機能と集約エディターを提供します。クエリを微調整すると、最良の結果が得られるだけでなく、時間の節約という点でパフォーマンスが向上します。