このストレージエンジンはMongoDBバージョン4.0まで廃止されましたが、いくつかの重要な機能があります。 MMAPv1は、MongoDBの元のストレージエンジンであり、マップされたファイルに基づいています。このストレージエンジンをサポートしているのは、64ビットのIntelアーキテクチャ(x86_64)のみです。
MMAPv1は、次のようなワークロードで優れたパフォーマンスを実現します...
- 大規模な更新
- 大量の読み取り
- 大量インサート
- システムメモリの使用率が高い
MMAPv1アーキテクチャ
MMAPv1はBツリーベースのシステムであり、ストレージの相互作用やメモリ管理などの多くの機能をオペレーティングシステムに提供します。
これは、WiredTigerストレージエンジンが導入されるまで、3.2より前のバージョンのMongoDBのデフォルトデータベースでした。その名前は、メモリマップトファイルを使用してデータにアクセスするという事実に由来しています。これは、mmap()システムコール手法を介して仮想メモリ内にあるファイルの内容を直接ロードおよび変更することによって行われます。
すべてのレコードはディスク上に連続して配置され、ドキュメントが割り当てられたレコードサイズよりも大きくなった場合、MongoDBは新しいレコードを割り当てます。 MMAPv1の場合、これはシーケンシャルデータアクセスには有利ですが、同時に、すべてのドキュメントインデックスを更新する必要があり、ストレージの断片化が発生する可能性があるため、時間コストがかかるという制限があります。
MMAPv1ストレージエンジンの基本的なアーキテクチャを以下に示します。
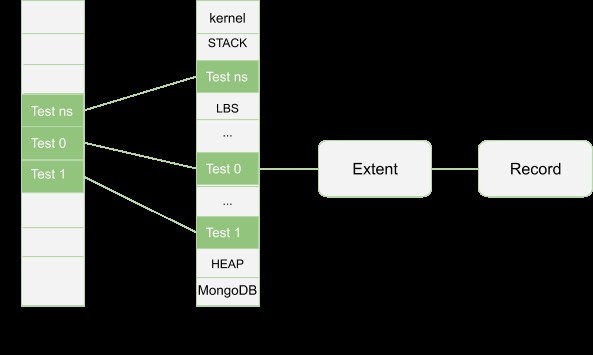
前述のように、ドキュメントサイズが割り当てられたレコードサイズを超えると、再割り当てが発生しますが、これは適切ではありません。これを回避するために、MMAPv1エンジンはPower of 2 Sized Allocationを利用して、すべてのドキュメントがドキュメント自体を含むレコードに格納されるようにします(パディングと呼ばれる余分なスペースを含む)。次に、パディングを使用して、再割り当ての可能性を減らしながら、更新によって発生する可能性のあるドキュメントの増加を考慮します。そうしないと、再割り当てが発生した場合に、ストレージが断片化する可能性があります。パディングは、効率を向上させるために追加のスペースを交換し、それによって断片化を減らします。挿入、更新、または削除の量が多いワークロードの場合、2の累乗の割り当てが最も優先されますが、正確にフィットする割り当ては、更新または削除のワークロードを含まないコレクションにとって理想的です。
2つのサイズの割り当てのパワー
ドキュメントをスムーズに拡張するために、この戦略はMMAPv1ストレージエンジンで採用されています。すべてのレコードのサイズはバイト単位で、2の累乗、つまり(32、64、128、256、512 ... 2MB)です。 2MBは、これを超えるすべてのドキュメントのデフォルトの大きい制限であり、そのメモリは2MBの最も近い倍数に丸められます。たとえば、ドキュメントが200MBの場合、このサイズは256MBに丸められ、56MBのスペースの交換が追加の拡張に利用できるようになります。これにより、ドキュメントがドキュメントに到達したときにシステムが再割り当てをトリガーする代わりに、ドキュメントを拡張できます。利用可能なスペースの制限。
パワー2サイズの割り当てのメリット
- 断片化を減らすために解放されたレコードを再利用する: この概念では、レコードはメモリで量子化され、以前のドキュメントの削除または再配置によって作成された割り当てられたスペースに収まる新しいドキュメントを収容するのに十分な大きさの固定サイズになります。
- ドキュメントの移動を減らします: 前述のように、デフォルトでは、ドキュメントサイズを設定されたレコードサイズよりも大きくするMongoDBの挿入と更新により、インデックスも更新されます。これは単にドキュメントが移動されたことを意味します。ただし、ドキュメント内に拡張するための十分なスペースがある場合、ドキュメントは移動されないため、インデックスの更新が少なくなります。
メモリ使用量
MMAPv1ストレージエンジンのマシン上のすべての空きメモリがキャッシュとして使用されます。正しいサイズのワーキングセットと最適なパフォーマンスは、メモリに収まるワーキングセットによって実現されます。さらに、60秒ごとに、MMAPv1はデータへの変更をディスクにフラッシュするため、キャッシュメモリを節約できます。この値は、フラッシュが頻繁に実行されるように変更できます。すべての空きメモリがキャッシュとして使用されるため、この使用量は動的であるため、システムリソース監視ツールがMongoDBが大量のメモリを使用していることを示すことに驚かないでください。
MMAPv1ストレージエンジンのメリット
- 事前割り当て戦略を使用すると、ディスク上の断片化が減少します。
- ワーキングセットがメモリに収まるように構成されている場合、非常に効率的な読み取り。
- インプレース更新、つまり個々のフィールドの更新により、より多くのデータが保存されるため、最小限の同時ライターで大規模なドキュメントの更新が改善されます。
- 同時ライターの数が少ない場合、ディスクへのデータフラッシュを頻繁に行うというコンセプトにより、書き込みパフォーマンスを向上させることができます。
- コレクションレベルのロックにより、書き込み操作が容易になります。ロックスキームは、データベースのパフォーマンスにおいて最も重要な要素の1つです。この場合、一度に1つのクライアントのみがデータベースにアクセスできます。これにより、ストレージエンジンによってシリアル方式で提示される場合よりも、操作がより迅速に流れるようなシナリオが作成されます。
MMAPv1ストレージエンジンの制限
- 反復を行うときのスペース使用率が高い。 MMAPv1にはファイルシステムの圧縮戦略がないため、レコードスペースが過剰に割り当てられます。
- 書き込み操作を行うときの多くのクライアントのコレクションアクセス制限。 MMAPv1はコレクションレベルのロック戦略を使用します。つまり、2つ以上のクライアントが同時に同じコレクションにアクセスできないため、書き込みによってこのコレクションへのすべての読み取りがブロックされます。これにより、同時実行性が粗くなり、MMAPv1エンジンをスケーリングできなくなります。
- ジャーナリングオプションが有効になっていない場合、システムクラッシュによりデータが失われる可能性があります。ただし、そうである場合でも、ウィンドウは小さすぎますが、少なくとも大規模なデータ損失のシナリオからあなたを守ることができます。
- 非効率的なストレージ使用率。事前割り当て戦略を使用する場合、一部のドキュメントはデータ自体よりもディスク上のスペースを占有します。
- ワーキングセットのサイズが割り当てられたメモリを超えると、パフォーマンスが大幅に低下します。さらに、初期ストレージ後のドキュメントの大幅な増加は、追加のI / Oをトリガーする可能性があるため、パフォーマンスの問題を引き起こす可能性があります。
MMAPv1とWiredTigerストレージエンジンの比較
| 主な機能 | MMAPv1 | WiredTiger |
|---|---|---|
| CPUパフォーマンス | 残念ながら、CPUコアを追加してもパフォーマンスは向上しません | マルチコアシステムでパフォーマンスが向上 |
| 暗号化 | メモリマップトファイルが使用されているため、暗号化はサポートされていません | 転送中のデータと残りのデータの両方の暗号化は、MongoDBエンタープライズとベータインストールの両方で利用できます |
| スケーラビリティ | コレクションレベルのロックの結果として生じる同時書き込みにより、スケールアウトが不可能になります。 | ロックレベルが最も低いのはドキュメント自体であるため、スケールアウトする可能性が高くなります。 |
| 調整 | このストレージエンジンを調整する可能性はほとんどありません | キャッシュサイズ、チェックポイント間隔、読み取り/書き込みチケットなどの変数を中心に、さまざまな調整を行うことができます |
| データ圧縮 | データ圧縮がないため、より多くのスペースが使用される可能性があります | Snappyおよびzlib圧縮方式が利用できるため、ドキュメントがMMAPv1よりも占有するスペースが少なくなる可能性があります |
| アトミックトランザクション | 単一のドキュメントにのみ適用可能 | バージョン4.0以降、マルチドキュメントでのアトミックトランザクションがサポートされています。 |
| メモリ | マシン上のすべての空きメモリがキャッシュとして使用されます | ファイルシステムキャッシュと内部キャッシュが利用されます |
| 更新 | インプレース更新をサポートしているため、大量の挿入、読み取り、インプレース更新を伴うワークロードに優れています | インプレース更新はサポートされていません。ドキュメント全体を書き直す必要があります。 |
結論
データベースのストレージエンジンの選択に関しては、多くの人がどちらを選択すればよいかわかりません。選択は通常、受けるワークロードに依存します。一般的なゲージでは、MMAPv1は適切な選択を行わないため、MongoDBはWiredTigerオプションに多くの進歩を遂げました。ただし、ユースケースによっては、他のストレージエンジンよりも優れている場合があります。たとえば、読み取りワークロードのみを実行する必要がある場合や、1つまたは2つのフィールドが頻繁に更新される大きなドキュメントを含む多数の個別のコレクションを保存する必要がある場合などです。