TL; DR:mongoengineは、返されたすべての配列をdictに変換するのに何年も費やしています
これをテストするために、DictFieldを含むドキュメントを使用してコレクションを作成しました。 ネストされた大きなdict 。ドキュメントはおおよそ5〜10MBの範囲です。
その後、 timeit.timeitを使用できます。
pymongoとmongoengineを使用して読み取りの違いを確認します。
その後、pycallgraph
を使用できます。 および
完全なコードは次のとおりです:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
そして、出力は、mongoengineがpymongoと比較して非常に遅いことを証明しています:
pymongo took 0.87s
mongoengine took 25.81118331072267
結果のコールグラフは、ボトルネックがどこにあるかを非常に明確に示しています。
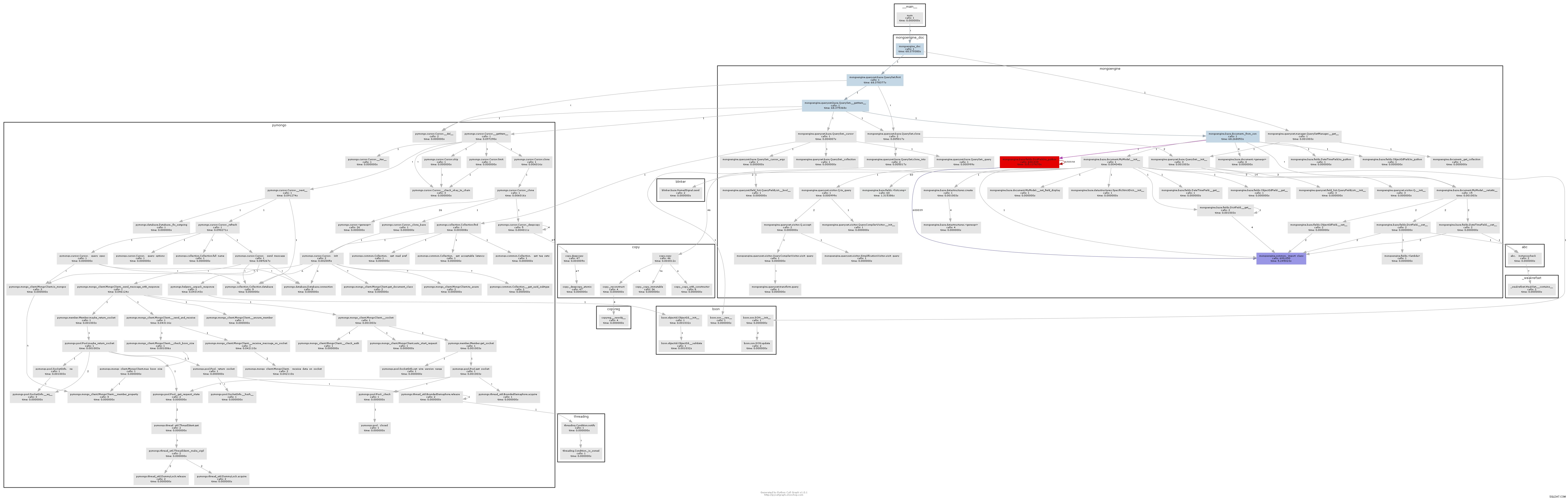
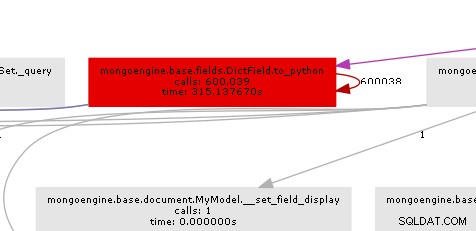
基本的に、mongoengineはすべてのDictFieldでto_pythonメソッドを呼び出します それがデータベースから戻ってくること。 to_python かなり遅く、この例では非常識な回数と呼ばれています。
Mongoengineは、ドキュメント構造をPythonオブジェクトにエレガントにマッピングするために使用されます。非常に大きな非構造化ドキュメント(mongodbが最適)がある場合、mongoengineは実際には適切なツールではないため、pymongoを使用する必要があります。
ただし、構造がわかっている場合は、EmbeddedDocumentを使用できます。 mongoengineからわずかに優れたパフォーマンスを得るためのフィールド。似ているが同等ではないテスト
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
したがって、mongoengineを高速化できますが、pymongoはさらに高速です。
更新
ここでのpymongoインターフェースへの良い近道は、集約フレームワークを使用することです:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]