Apache HBaseスナップショットに関するこのシリーズのパート1では、新しいスナップショット機能の使用方法と、実装の背後にある理論について学びました。それでは、技術的な詳細をもう少し深く掘り下げてみましょう。
テーブルとは何ですか?
HBaseテーブルは、メタデータ情報のセットとキーと値のペアのセットで構成されます。
- テーブル情報 :列ファミリー、圧縮およびエンコードコーデック、ブルームフィルタータイプなど、テーブルの「設定」を説明するマニフェストファイル。
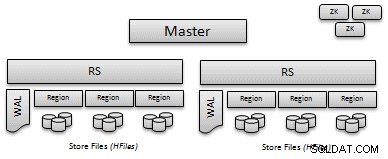
- 地域 :テーブル「パーティション」はリージョンと呼ばれます。各リージョンは、連続するキー/値のセットを処理する責任があり、開始キーと終了キーによって定義されます。
- WALs / MemStore :ディスクにデータを書き込む前に、プットは先行書き込みログ(WAL)に書き込まれ、メモリ不足によってディスクへのフラッシュがトリガーされるまでメモリに保存されます。 WALは、障害時にディスクにフラッシュされなかったプットを回復する簡単な方法を提供します。
- HFiles :ある時点で、すべてのデータがディスクにフラッシュされます。 HFileは、保存されたキー/値を含むHBase形式です。 HFilesは不変ですが、圧縮または領域の削除時に削除できます。
(注:HBase書き込みパスの詳細については、HBase書き込みパスのブログ投稿を参照してください。)
スナップショットとは何ですか?
スナップショットは、管理者が取得したテーブルの以前の状態に戻ることができるようにするメタデータ情報のセットです。スナップショットはテーブルのコピーではありません。これを考える最も簡単な方法は、メタデータ(テーブル情報とリージョン)とデータ(HFiles、memstore、WAL)を追跡する一連の操作です。スナップショット操作中にデータのコピーは含まれません。
- オフラインスナップショット :スナップショットを作成する最も簡単なケースは、テーブルが無効になっている場合です。テーブルを無効にすると、すべてのデータがディスク上でフラッシュされ、書き込みまたは読み取りは受け入れられなくなります。この場合、スナップショットを作成するには、テーブルのメタデータとディスク上のHFileを調べて、それらへの参照を保持するだけです。マスターがこの操作を実行します。必要な時間は、主にHDFSネームノードがファイルのリストを提供するために必要な時間によって決まります。
- オンラインスナップショット :ただし、ほとんどの場合、テーブルが有効になっており、各リージョンサーバーがputおよびgetリクエストを処理しています。この場合、マスターはスナップショット要求を受信し、各リージョンサーバーに、担当するリージョンのスナップショットを取得するように要求します。
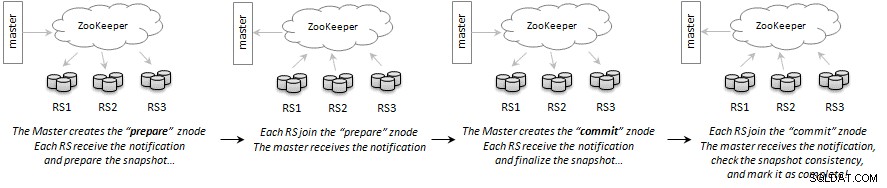
マスターサーバーとリージョンサーバー間の通信は、2フェーズコミットのようなトランザクションを使用してApache ZooKeeperを介して行われます。マスターは、「スナップショットの準備」を意味するznodeを作成します。各リージョンサーバーはリクエストを処理し、担当するテーブルからリージョンのスナップショットを準備します。完了すると、「完了しました」という意味のサブノードをprepare-requestznodeに追加します。
すべてのリージョンサーバーがステータスを報告すると、マスターは「スナップショットのコミット」を意味する別のznodeを作成します。各リージョンサーバーはスナップショットを完成させ、ノードに参加する前と同じようにステータスを報告します。すべてのリージョンサーバーがレポートを返すと、マスターはスナップショットを完成させ、操作を完了としてマークします。リージョンサーバーが障害を報告した場合、マスターは中止メッセージのブロードキャストに使用される新しいznodeを作成します。
リージョンサーバーは新しいリクエストを継続的に処理しているため、ユースケースごとに異なる整合性モデルが必要になる場合があります。たとえば、MemStoreに新しいデータがない、ずさんなスナップショットに興味がある人や、書き込みをしばらくロックする必要がある完全に一貫性のあるスナップショットが必要な人などがあります。
このため、リージョンサーバーでスナップショットを作成する手順はプラグイン可能です。現在、存在する唯一の実装は「フラッシュスナップショット」です。これは、スナップショットを作成する前にフラッシュを実行し、行の整合性のみを保証します。異なる整合性ポリシーを持つ他の手順が将来実装される可能性があります。
オンラインの場合、スナップショットの作成に必要な時間は、最も遅いリージョンサーバーがスナップショット操作を実行し、成功をマスターに報告するために必要な時間によって制限されます。この操作は通常、数秒程度です。
アーカイブ
前に見たように、HFilesは不変です。これにより、スナップショットまたはクローン操作中にデータをコピーすることを回避できますが、圧縮中にデータが削除され、圧縮されたバージョンに置き換えられます。この場合、それらのファイルの1つを参照しているスナップショットまたはクローンテーブルがある場合、それらを削除するのではなく、「アーカイブ」の場所に移動します。スナップショットを削除し、スナップショットによって参照されているファイルを他の誰も参照していない場合、それらのファイルは削除されます。
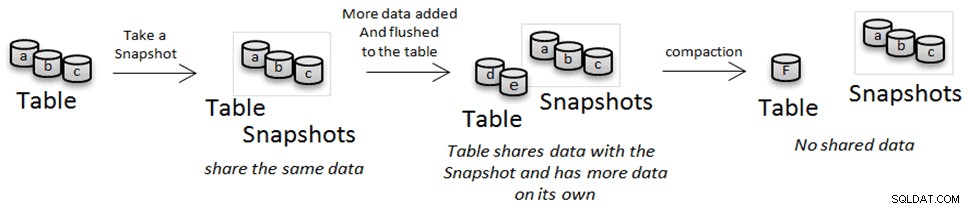
テーブルの複製と復元
スナップショットは、ユーザーまたはアプリケーションのエラー後にテーブルを復元/回復するために使用できるバックアップソリューションと見なすことができますが、スナップショット機能を使用すると、単純なバックアップと復元以上のものを使用できます。スナップショットからテーブルのクローンを作成した後、MapReduceジョブまたは単純なアプリケーションを作成して、相違点、または重要と思われるものを本番環境に選択的にマージできます。もう1つの使用例は、テーブルのコピーを何時間も待たずに、またディスク上に大量のデータが複製されることなく、データのスキーマ変更または更新をテストできることです。
スナップショットからテーブルを複製する
管理者がクローン操作を実行すると、スナップショットに存在するテーブルスキーマを含む新しいテーブルが、スナップショット領域情報の開始/終了キーを使用して事前に分割されて作成されます。テーブルのメタデータが作成されると、データをコピーする代わりに、スナップショットの場合と同じトリックが使用されます。 HFilesは不変であるため、ソースファイルへの参照のみが作成されます。これにより、操作でデータコピーを回避し、ソーステーブルまたはスナップショットに影響を与えることなくクローンを編集できます。クローン操作はマスターによって実行されます。
スナップショットからテーブルを復元する
復元操作はクローン操作に似ています。テーブルを削除し、スナップショットからクローンを作成することと考えることができます。復元操作により、スナップショットに存在する古いデータが復元され、スナップショットにも含まれていないデータがテーブルから削除されます。また、テーブルのスキーマがスナップショットのスキーマに戻されます。内部的には、テーブルの状態とスナップショットを比較し、スナップショットに存在しないファイルを削除し、スナップショットに存在するが現在の状態には存在しないファイルへの参照を追加することで、復元を実装します。また、テーブル記述子は、スナップショットの時点でのテーブル「スキーマ」を反映するように変更されます。復元操作はマスターによって実行され、テーブルを無効にする必要があります。
将来
現在、スナップショットの実装には、必要なすべての基本機能が含まれています。これまで見てきたように、オンラインスナップショットの新しいスナップショット整合性ポリシーにより、柔軟性、整合性、またはパフォーマンスが向上します。より良いファイル管理は、HDFSネームノードの負荷を減らし、ディスクスペース管理を改善することができます。さらに、メトリック、Web UI(色相)などがやることリストに含まれています。
結論
HBaseスナップショットは、オンラインスナップショット、またはコピーオンライトスナップショット、復元、クローンで使用される「手順の調整」などの新しい機能を追加します。
スナップショットは、distcpまたはCopyTableに基づく手作りの「バックアップ」および「クローン作成」ソリューションに代わる、より高速で優れたソリューションを提供します。すべてのスナップショット操作(スナップショット、復元、クローン)にはデータのコピーが含まれないため、テーブルのスナップショットが高速になり、ディスク容量を節約できます。
スナップショットを有効にして使用する方法の詳細については、HBase運用管理ドキュメントを参照してください。
Matteo Bertozziは、プラットフォームチームのソフトウェアエンジニアであり、HBaseコミッターです。