これは私の新しいYouTube動画の書かれたバージョンです ✍️🙂
このRedisチュートリアルでは、Redisと、Redisを複雑なアプリケーションのプライマリデータベースとして使用する方法について学習します。 複数の形式でデータを保存する必要があります。
概要📝
- Redisとは何かとその使用法 なぜそれが現代の複雑なマイクロサービスアプリケーションに適しているのか?
- Redisがモジュールを介してさまざまな目的で複数のデータ形式を保存することをサポートする方法 ?
- インメモリデータベースとしてのRedisがデータを永続化し、データ損失から回復する方法 ?
- Redisをスケーリングして複製する方法 ?
- 最後に、マイクロサービスを実行するための最も人気のあるプラットフォームの1つはKubernetesであり、Kubernetesでステートフルアプリケーションを実行するのは少し難しいため、KubernetesでRedisを簡単に実行する方法を説明します
Redisとは何ですか?
Redisはreの略です モテdic s erver
Redisはインメモリデータベースです 。そのため、多くの人が他のデータベースの上にキャッシュとして使用しています アプリケーションのパフォーマンスを向上させるため。 🤓
ただし、多くの人が知らないのは、Redisが本格的なプライマリデータベースであるということです。 これは、複雑なアプリケーションの複数のデータ形式を保存および永続化するために使用できます。 😎
それでは、そのユースケースを見てみましょう。
なぜマルチモデルデータベースなのか
マイクロサービスアプリケーションの一般的な設定を見てみましょう。
数百万人のユーザーがいる複雑なソーシャルメディアアプリケーションがあるとしましょう。このため、さまざまなデータベースにさまざまなデータ形式を保存する必要がある場合があります。
- リレーショナルデータベース 、Mysqlのように、データを保存します
- ElasticSearch 高速検索とフィルタリングのために
- グラフデータベース ユーザーのつながりを表すために
- ドキュメントデータベース 、ユーザーが毎日共有するメディアコンテンツを保存するMongoDBのように
- キャッシュサービス アプリケーションのパフォーマンスを向上させるために
これがかなり複雑な設定であることは明らかです。
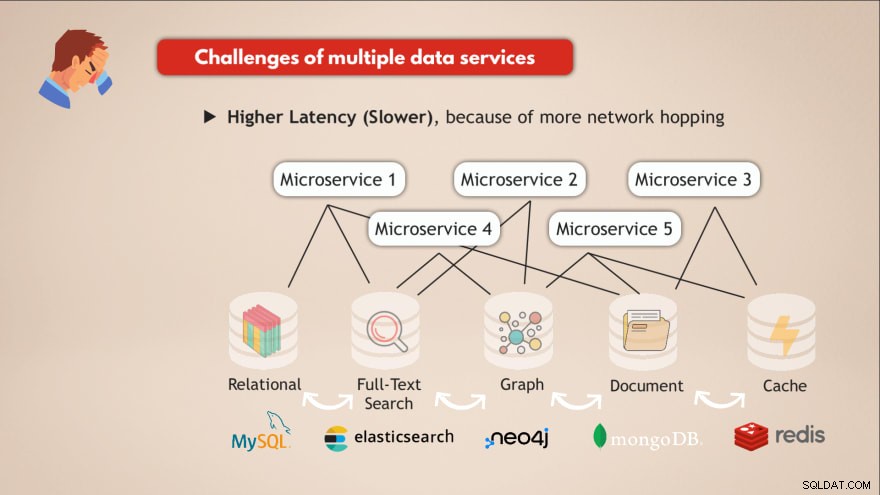
複数のデータサービスを持つことの課題
- ❌各データサービスを展開して維持する必要があります
- ❌各データサービスに必要なノウハウ
- ❌さまざまなスケーリングとインフラストラクチャの要件
- ❌これらすべての異なるDBと対話するためのより複雑なアプリケーションコード
- ❌ネットワークホッピングが多いため、遅延が長くなります(遅くなります)
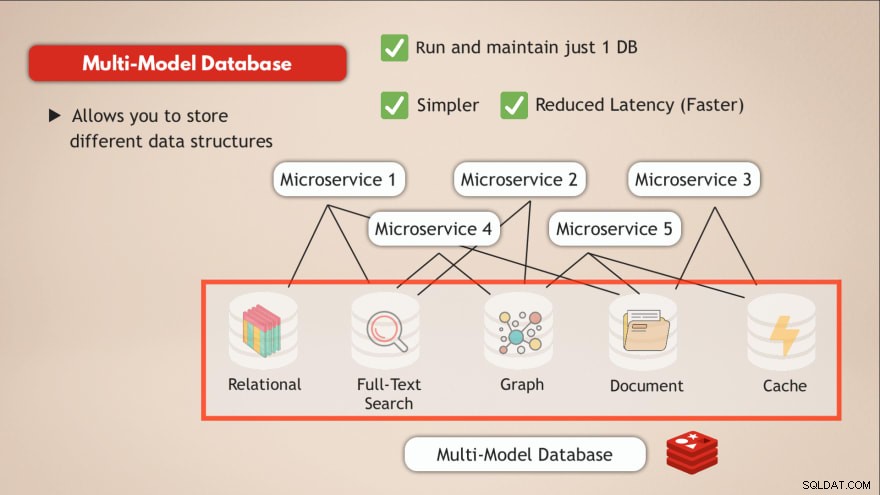
マルチモデルデータベースを持つ
マルチモデルデータベースと比較すると、これらの課題のほとんどを解決できます。まず、1つのデータサービスのみを実行および維持します 。したがって、アプリケーションも単一のデータストアと通信する必要があり、そのデータサービスに必要なプログラムインターフェイスは1つだけです。
さらに、単一のデータエンドポイントに移動し、複数の内部ネットワークハブを排除することで、遅延が削減されます。
したがって、Redisのように1つのデータベースを使用すると、さまざまな種類のデータを保存したり、基本的に複数の種類のデータベースを1つにまとめたり、キャッシュとして機能させたりして、このような課題を解決できます。
- ✅データベースを1つだけ実行して維持する
- ✅シンプル
- ✅レイテンシの短縮(高速)
Redisの仕組みは?
Redisモジュール 📦
それが機能する方法は、キーバリューストアであるRedisCoreがあることです。 すでに複数のタイプのデータの保存をサポートしており、さまざまなデータタイプのモジュールと呼ばれるものでそのコアを拡張できます。 、アプリケーションがさまざまな目的で必要とするもの。たとえば、ElasticSearchやグラフデータストレージ用のRedisGraphなどの検索機能用のRediSearchは次のようになります。

そして、これの素晴らしいところは、モジュラーであるということです。 。したがって、これらのさまざまなタイプのデータベース機能は1つのデータベースに緊密に統合されていませんが、アプリケーションに必要なデータサービス機能を正確に選択して選択し、基本的にそのモジュールを追加できます。
すぐに使えるキャッシュ ⚡️
もちろん、Redisをプライマリデータベースとして使用する場合、追加のキャッシュは必要ありません。これは、Redisですぐに使用できるキャッシュがあるためです。これは、キャッシュの投入と無効化を管理するためのロジックを実装する必要がないため、アプリケーションの複雑さが軽減されることを意味します。
Redisは高速です 🚀
インメモリ(データはRAMに保存される)データベースとして、Redisは超高速でパフォーマンスが高く、もちろんアプリケーション自体も高速になります。
しかし、この時点であなたは疑問に思うかもしれません:
インメモリデータベースはどのようにしてデータを永続化できますか? 🤔
Redisはどのようにしてデータを永続化し、データ損失から回復できますか? 🧐
RedisプロセスまたはRedisを実行しているサーバーに障害が発生した場合、メモリ内のすべてのデータが正しく失われていますか?では、データはどのように保持され、基本的にデータが安全であるとどのように確信できるでしょうか。 👀
Redisを複製しますか?
データをバックアップする最も簡単な方法は、Redisを複製することです 。したがって、Redisマスターインスタンスがダウンしても、レプリカは引き続き実行され、すべてのデータが含まれます。したがって、Redisを複製した場合、レプリカにはデータが含まれます。
ただし、もちろん、すべてのRedisインスタンスがダウンすると、レプリカが残っていないため、データが失われます。 🤯だから本当の永続性が必要 。
スナップショットとAOF
Redisには、データを永続化し、データを安全に保つための複数のメカニズムがあります。
スナップショット
1つ目:スナップショット。時間やリクエスト数などに基づいて構成できます。したがって、データのスナップショットはディスクに保存されます 、Redisデータベース全体がなくなった場合にデータを回復するために使用できます。
ただし、最後の数分間のデータが失われることに注意してください 、通常、ニーズに応じて5分または1時間ごとにスナップショットを作成するためです。 😐
AOF
そのため、代わりにRedisは AOFと呼ばれるものを使用します 、 Aの略です ppend O nly F ile。
この場合、すべての変更は継続的に永続化するためにディスクに保存されます 。また、Redisを再起動するとき、または停止後に、RedisはAppendOnlyFileログを再生して状態を再構築します。
したがって、AOFの方が耐久性があります 、ただし、スナップショットよりも遅くなる可能性があります。
最適なオプション 💡:AOFとスナップショットの両方を組み合わせて使用します。この場合、AOFはデータをメモリからディスクに継続的に保持し、データの状態を回復する必要がある場合に備えて、データの状態を保存するために定期的なスナップショットを間に置きます。

Redisデータベースをスケーリングする方法は?
1つのRedisインスタンスのメモリが不足しているため、データが大きくなりすぎてメモリ内に保持できないか、Redisがボトルネックになり、それ以上のリクエストを処理できなくなったとします。このような場合、容量とメモリサイズを増やすにはどうすればよいですか。 私のRedisデータベースのために? 🤔
そのためのいくつかのオプションがあります:
1.クラスタリング
まず、Redisはクラスタリングをサポートしています 。これは、データの読み取りと書き込みに使用できるプライマリまたはマスターRedisインスタンスを作成でき、データの読み取りにそのプライマリインスタンスの複数のレプリカを作成できることを意味します :
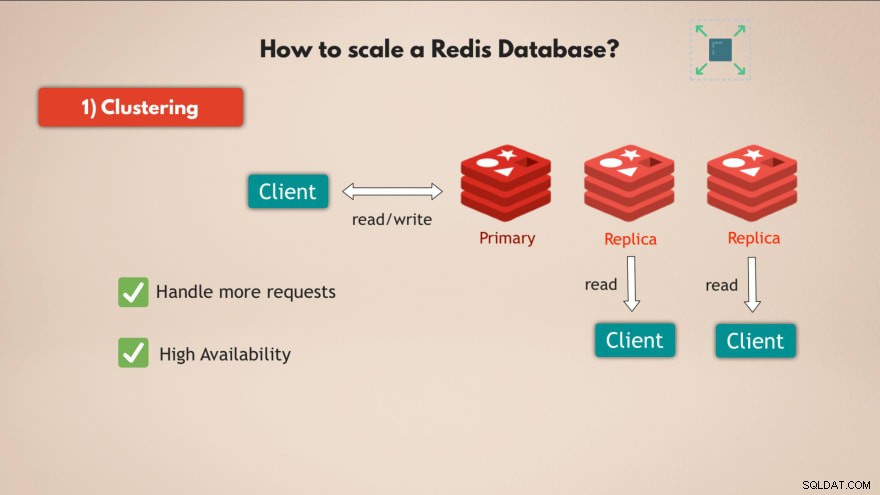
このようにして、Redisをスケーリングしてより多くのリクエストを処理し、さらに高可用性を向上させる マスターに障害が発生した場合、レプリカの1つが引き継ぐことができ、Redisデータベースは基本的に問題なく機能し続けることができるためです。
2.シャーディング
それで十分なようですが、
- データセットが大きくなりすぎて、単一サーバーのメモリに収まらない 。
- さらに、データベースの読み取りをスケーリングしたため、基本的にデータをクエリするだけのすべてのリクエスト。ただし、マスターインスタンスはまだ単独であり、すべての書き込みを処理する必要があります 。
では、ここでの解決策は何ですか? 🤔
そのために、シャーディングの概念を使用します 、これはデータベースの一般的な概念であり、Redisもサポートしています。
したがって、シャーディング 基本的には、完全なデータセットを取得して、データの小さなチャンクまたはサブセットに分割することを意味します。 、各シャードが独自のデータサブセットを担当します。
つまり、完全なデータセットへのすべての書き込みを処理する1つのマスターインスタンスを使用する代わりに、たとえば4つのシャードに分割して、それぞれがデータのサブセットへの読み取りと書き込みを担当することができます。 。 💡
また、各シャードには少ないメモリ容量が必要です。 、データの4分の1しかないためです。これは、シャードをより小さなノードに分散して実行し、基本的にクラスターを水平方向にスケーリングできることを意味します。
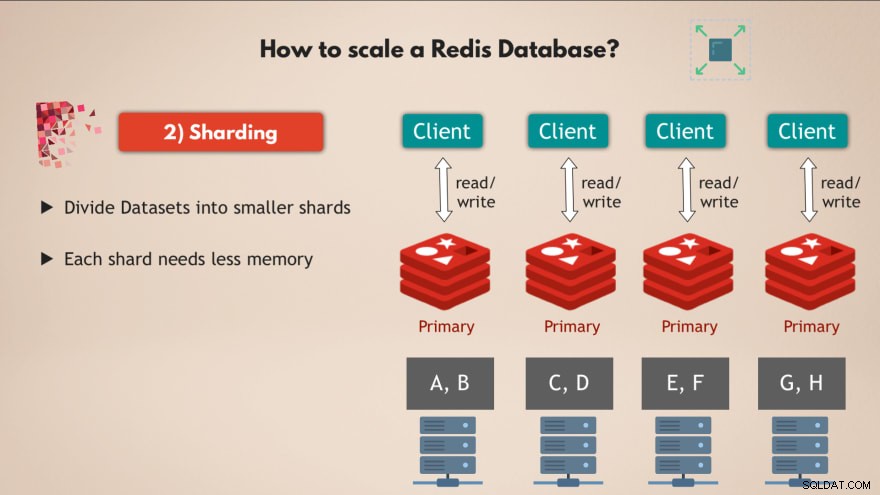
したがって、複数のノード 、複数のレプリカを実行します すべてシャーディングされたRedisの ボトルネックを作成することなく、はるかに多くのリクエストを処理できる、非常にパフォーマンスの高い高可用性Redisデータベースを提供します👍
その他のトピック...
最後の2つのトピックとシナリオについては、以下の私のビデオをチェックしてください。
- さらに高い可用性とパフォーマンスを複数の地理的な場所で必要とするアプリケーション
- マイクロサービスを実行するための新しい標準はKubernetesプラットフォームであるため、KubernetesでRedisを実行する 非常に興味深く、一般的なユースケースです
完全なビデオはここから入手できます:🤓
これがあなたの何人かにとって有益で興味深いものであったことを願っています! 😊
いいね、共有、フォローしてください 😍その他のコンテンツ:
- Instagram-舞台裏のものをたくさん投稿する
- プライベートFBグループ