遅かれ早かれコードで正規表現を頻繁に使用するOracle開発者は、実際に神秘的な現象に直面する可能性があります。問題の根本を長期的に調査すると、体重減少、食欲、さまざまな種類の心身症を引き起こす可能性があります。これはすべて、regexp_replace関数を使用して防ぐことができます。最大6つの引数を持つことができます:
REGEXP_REPLACE(
- source_string、
- テンプレート
- substituting_string、
- テンプレートを使用した一致検索の開始位置(デフォルトは1)
- ソース文字列内のテンプレートの出現位置(デフォルトでは0はすべての出現に等しい)
- 修飾子(これまでのところ、ダークホースです)
)
テンプレートのすべての出現箇所がsubstituting_stringパラメーターで渡された値に置き換えられた変更されたsource_stringを返します。多くの場合、関数の短いバージョンが使用され、最初の3つの引数が指定されます。これは、多くの問題を解決するのに十分です。私も同じことをします。 「MASK:小文字」文字列のすべての文字列文字をアスタリスクでマスクする必要があるとします。小文字の範囲を指定するには、「[a-z]」パターンが適している必要があります。
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual 期待
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
現実
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
このイベントがデータベースに再現されていない場合は、これまでのところ幸運です。しかし、多くの場合、コードを掘り下げ、文字列をある文字セットから別の文字セットに変換すると、最終的には絶望が生じます。
問題の定義
疑問が生じます。文字「A」の何が特別なので、残りの大文字も置き換えられるはずがなかったため、置き換えられませんでした。たぶん、これ以外の正しい文字があります。大文字のアルファベット全体を見る必要があります。
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ ただし
関数の6番目の引数が明示的に指定されていない場合、たとえば、ソース文字列をテンプレートと比較するときに、「i」は大文字と小文字を区別しないか、「c」は大文字と小文字を区別します。正規表現では、デフォルトでセッション/データベースのNLS_SORTパラメータが使用されます。例:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
このパラメーターは、ORDERBYのソート方法を指定します。単純な個々の文字の並べ替えについて説明すると、特定の2進数(NLSSORTコード)がそれぞれに対応し、実際にはこれらの数字の値によって並べ替えが行われます。
これを説明するために、アルファベットの最初と最後の数文字(小文字と大文字の両方)を条件付きで順序付けされていないテーブルセットに入れて、ABCと呼びましょう。次に、このセットをSYMBOLフィールドで並べ替えて、そのNLSSORTコードを各シンボルの横にHEX形式で表示します。
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
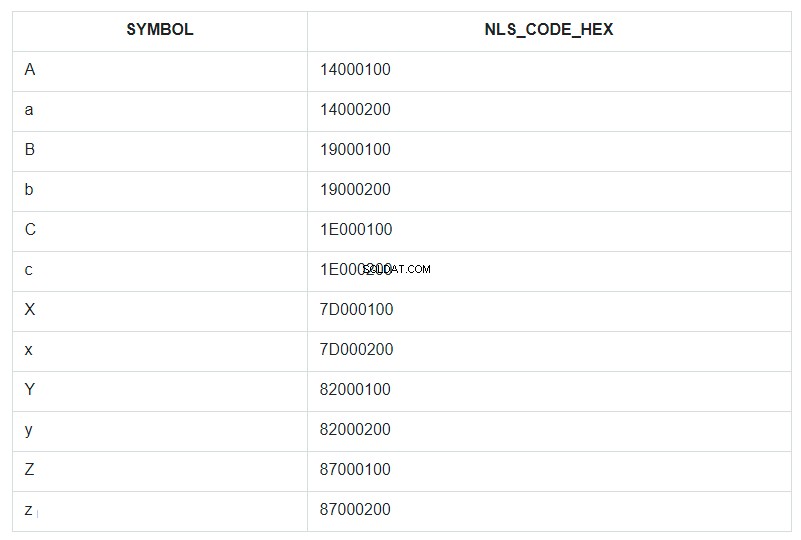
クエリでは、SYMBOLフィールドにORDER BYが指定されていますが、実際には、データベースでは、フィールドNLS_CODE_HEXの値によって並べ替えが行われました。
次に、テンプレートの範囲に戻り、表を確認します。記号「a」(コード14000200)と「z」(コード87000200)の間の垂直方向は何ですか。大文字の「A」を除くすべて。アスタリスクに置き換えられたのはそれだけです。また、文字「A」のコード14000100は、14000200から87000200までの置換範囲には含まれていません。
治療
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
一部の情報源によると、修飾子「c」はデフォルトで設定されていますが、これは完全に正しくないことがわかりました。そして、誰かがそれを見なかった場合、そのセッション/データベースのNLS_SORTパラメータはおそらくBINARYに設定され、ソートは実際の文字コードに対応して実行されます。実際、セッションパラメータを変更すると、問題は解決します。
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ テストはOracle12cで実行されました。
コメントを残して、気を付けてください。