これは非常に一般的な問題です。
プレーンなB-Tree インデックスは次のようなクエリには適していません:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
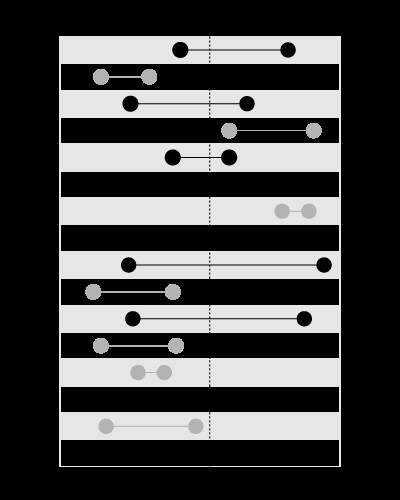
インデックスは、次のように、指定された範囲内の値を検索するのに適しています。
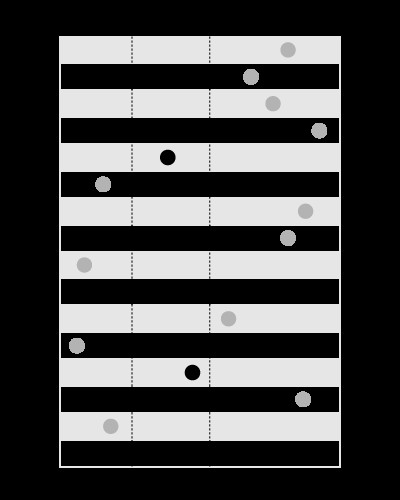
、ただし、次のように、指定された値を含む境界を検索するためのものではありません:
私のブログのこの記事では、問題について詳しく説明しています。
(入れ子集合モデルは、同様のタイプの述語を扱います。)
timeでインデックスを作成できます 、このようにintervals 結合の先頭になり、ネストされたループ内で範囲時間が使用されます。これには、timeでの並べ替えが必要になります 。
intervalsで空間インデックスを作成できます (MySQLで利用可能 MyISAMを使用する ストレージ)startが含まれます およびend 1つのジオメトリ列に。このように、measures 結合につながる可能性があり、並べ替えは必要ありません。
ただし、空間インデックスはより低速であるため、これは、メジャーが少なく、間隔が多い場合にのみ効率的です。
間隔は少ないがメジャーが多いため、measures.timeにインデックスがあることを確認してください。 :
CREATE INDEX ix_measures_time ON measures (time)
更新:
テストするサンプルスクリプトは次のとおりです。
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
このクエリ:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
NESTED LOOPSを使用します 1.7で返されます 秒。
このクエリ:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
MERGE JOINを使用します 5の後で停止しなければなりませんでした 分。
更新2:
ほとんどの場合、次のようなヒントを使用して、結合で正しいテーブル順序を使用するようにエンジンを強制する必要があります。
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle のオプティマイザは、間隔が交差しないことを確認するのに十分なほど賢くありません。そのため、おそらくmeasuresを使用します 主要なテーブルとして(間隔が交差する場合は賢明な決定になります)。
更新3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
このクエリは、時間軸を範囲に分割し、HASH JOINを使用します 範囲値のメジャーとタイムスタンプを結合し、後で細かくフィルタリングします。
それがどのように機能するかについてのより詳細な説明については、私のブログのこの記事を参照してください: