多くのマイクロサービスで構成されるプロジェクトで作業している場合、複数のデータベースも含まれる可能性があります。
たとえば、MySQLデータベースとPostgreSQLデータベースがあり、どちらも別々のサーバーで実行されているとします。
通常、2つのデータベースのデータを結合するには、データを結合する新しいマイクロサービスを導入する必要があります。ただし、これによりシステムが複雑になります。
このチュートリアルでは、マテリアライズを使用して、ライブのマテリアライズドビューでMySQLとPostgresを結合します。その後、それを直接クエリし、標準SQLを使用して両方のデータベースからリアルタイムで結果を取得できるようになります。
マテリアライズは、Rustで記述されたソース利用可能なストリーミングデータベースであり、データの変更時にSQLクエリ(マテリアライズドビュー)の結果をメモリに保持します。
チュートリアルには、docker-composeの使用を開始できるデモプロジェクトが含まれています 。
使用するデモプロジェクトでは、模擬Webサイトで注文を監視します。後でカートが長期間放棄されたときに通知を送信するために使用できるイベントを生成します。
デモプロジェクトのアーキテクチャは次のとおりです。
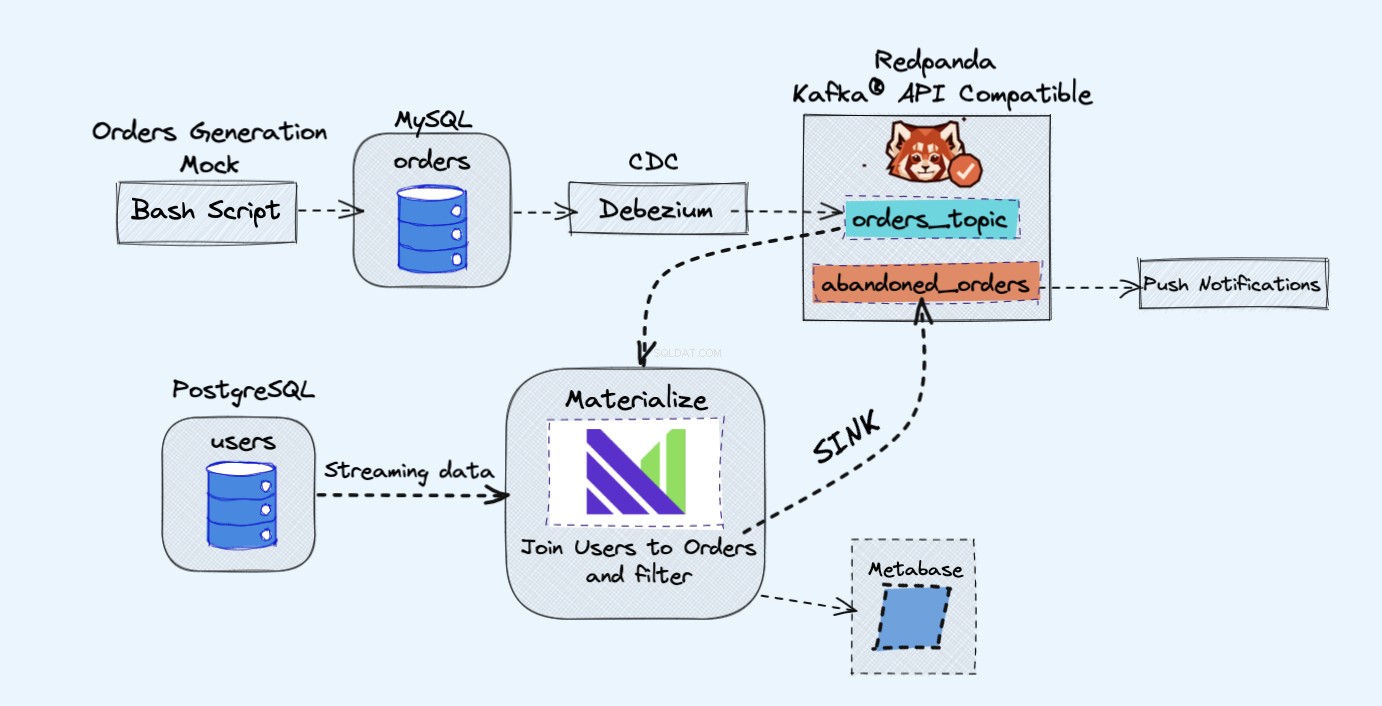
デモで使用するすべてのサービスはDockerコンテナー内で実行されるため、DockerとDockerComposeではなくラップトップやサーバーに追加のサービスをインストールする必要はありません。
DockerとDockerComposeがまだインストールされていない場合は、ここでその方法に関する公式の指示に従うことができます:
- Dockerをインストールする
- DockerComposeをインストールする
上の図に示すように、次のコンポーネントがあります。
- 継続的に注文を生成するための模擬サービス。
- 注文はMySQLデータベースに保存されます 。
- データベースへの書き込みが発生すると、 Debezium MySQLからレッサーパンダに変更をストリーミングします トピック。
- Postgresもあります ユーザーを取得できるデータベース。
- 次に、このレッサーパンダのトピックをマテリアライズに取り込みます。 Postgresデータベースのユーザーと直接一緒に。
- マテリアライズでは、注文とユーザーを結合し、フィルタリングを実行して、放棄されたカート情報を表示するマテリアライズドビューを作成します。
- 次に、放棄されたカートデータを新しいレッサーパンダトピックに送信するためのシンクを作成します。
- 最後に、メタベースを使用します データを視覚化する。
- 後で、その新しいトピックの情報を使用して、ユーザーに通知を送信し、カートが放棄されたことをユーザーに通知することができます。
ここでの補足として、レッサーパンダの代わりにカフカを使用してもまったく問題ありません。すべてのKafkaコンポーネントの代わりに単一のRedpandaインスタンスを実行できるので、Redpandaがテーブルにもたらすシンプルさが気に入っています。
まず、リポジトリのクローンを作成することから始めます。
git clone https://github.com/bobbyiliev/materialize-tutorials.git
その後、ディレクトリにアクセスできます:
cd materialize-tutorials/mz-join-mysql-and-postgresql
最初にRedpandaコンテナを実行することから始めましょう:
docker-compose up -d redpanda
画像を作成する:
docker-compose build
最後に、すべてのサービスを開始します。
docker-compose up -d
マテリアライズCLIを起動するには、次のコマンドを実行できます。
docker-compose run mzcli
これは、postgres-clientを使用したDockerコンテナへのショートカットにすぎません。 プリインストールされています。すでにpsqlをお持ちの場合 psql -U materialize -h localhost -p 6875 materializeを実行できます 代わりに。
マテリアライズCLIを使用しているので、ordersを定義しましょう。 mysql.shopのテーブル レッサーパンダのソースとしてのデータベース:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
ordersから利用可能な列を確認する場合 次のステートメントを実行してソースを作成します:
SHOW COLUMNS FROM orders;
MaterializeがRedpandaレジストリからメッセージスキーマデータを取得しているため、各属性に使用する列タイプを認識していることがわかります。
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
次に、最初のマテリアライズドビューを作成して、ordersからすべてのデータを取得します。 レッサーパンダの出典:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
SELECT * FROM abandoned_orders;を使用できるようになりました 結果を確認するには:
SELECT * FROM abandoned_orders;
マテリアライズド・ビューの作成の詳細については、マテリアライズ・ドキュメンテーションの「マテリアライズド・ビュー」セクションを確認してください。
MaterializeでPostgresソースを作成する方法は2つあります。
- MySQLソースで行ったのと同じようにDebeziumを使用します。
- Postgres Materialize Sourceを使用します。これにより、MaterializeをPostgresに直接接続できるため、Debeziumを使用する必要がありません。
このデモでは、Postgres Materialize Sourceを使用方法のデモンストレーションとして使用しますが、代わりにDebeziumを自由に使用してください。
Postgres Materialize Sourceを作成するには、次のステートメントを実行します。
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
上記のステートメントの簡単な要約:
-
MATERIALIZED:PostgreSQLソースのデータを具体化します。すべてのデータはメモリに保持され、ソースを直接選択できるようになります。 -
mz_source:PostgreSQLソースの名前。 CONNECTION:PostgreSQL接続パラメータ。PUBLICATION:マテリアライズにストリーミングされるテーブルを含むPostgreSQLパブリケーション。
PostgreSQLソースを作成したら、PostgreSQLテーブルをクエリできるようにするために、アップストリームパブリケーションの元のテーブルを表すビューを作成する必要があります。
この例では、usersというテーブルが1つだけあります。 したがって、実行する必要があるステートメントは次のとおりです。
CREATE VIEWS FROM SOURCE mz_source (users);
使用可能なビューを確認するには、次のステートメントを実行します。
SHOW FULL VIEWS;
それが完了したら、新しいビューを直接クエリできます:
SELECT * FROM users;
次に、先に進んで、さらにいくつかのビューを作成しましょう。
シンクを使用すると、Materializeから外部ソースにデータを送信できます。
このデモでは、レッサーパンダを使用します。
RedpandaはKafkaAPIと互換性があり、MaterializeはKafkaソースからのデータを処理するのと同じようにRedpandaからのデータを処理できます。
大量の未払いの注文をすべて保持するマテリアライズドビューを作成しましょう:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
ご覧のとおり、ここでは実際にusersに参加しています Postgresソースから直接データを取り込んでいるビューとabandond_orders レッサーパンダのトピックからのデータを一緒に取り込んでいるビュー。
上記のマテリアライズドビューのデータを送信するシンクを作成しましょう:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
ここで、Redpandaコンテナに接続して、rpk topic consumeを使用する場合 コマンドを実行すると、トピックからレコードを読み取ることができます。
ただし、現時点では、rpkで結果をプレビューすることはできません。 AVRO形式だからです。レッサーパンダは将来これを実装する可能性が高いですが、現時点では、トピックをマテリアライズにストリーミングしてフォーマットを確認することができます。
まず、自動的に生成されたトピックの名前を取得します。
SELECT topic FROM mz_kafka_sinks;
出力:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
トピック名の生成方法の詳細については、こちらのドキュメントをご覧ください。
次に、このレッサーパンダのトピックから新しいマテリアライズドソースを作成します:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
それに応じてトピック名を変更してください!
最後に、この新しいマテリアライズドビューをクエリします。
SELECT * FROM high_volume_orders_test LIMIT 2;
トピックにデータが含まれるようになったので、他のサービスを接続してデータを利用し、たとえばメールやアラートをトリガーすることができます。
Metabaseインスタンスにアクセスするには、https://localhost:3030にアクセスしてください。 デモをローカルで実行している場合、またはhttps://your_server_ip:3030 サーバーでデモを実行している場合。次に、手順に従ってメタベースのセットアップを完了します。
データのソースとして必ずマテリアライズを選択してください。
準備ができたら、標準のPostgreSQLデータベースの場合と同じようにデータを視覚化できます。
すべてのサービスを停止するには、次のコマンドを実行します。
docker-compose down
ご覧のとおり、これはマテリアライズの使用方法の非常に簡単な例です。マテリアライズを使用して、さまざまなソースからデータを取り込み、それをさまざまな宛先にストリーミングできます。
役立つリソース:
-
CREATE SOURCE: PostgreSQL CREATE SOURCECREATE VIEWS-
SELECT