私はAIの研究者なので、私が扱う主なものの1つはデータです。 たくさん それの。
2.5エクサバイトを超えるデータが毎日生成されます 、このデータを必要なときにアクセスできる場所に保存する必要があるのは当然のことです。
この記事では、ハッキング可能なチートシートを使用して、SQLをすばやく起動して実行できるようにします。
SQLとは何ですか?
SQLはStructuredQueryLanguageの略です。これは、リレーショナルデータベース管理システム用の言語です。 SQLは現在、リレーショナルデータベース内のデータを保存、取得、操作するために使用されています。
基本的なリレーショナルデータベースは次のようになります。
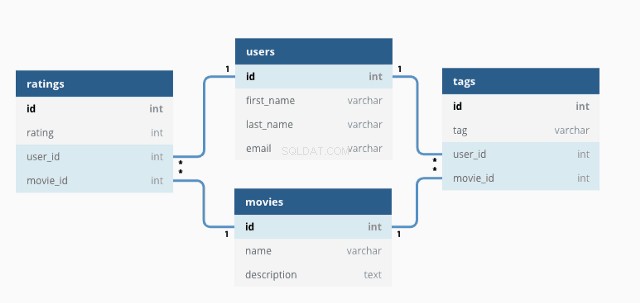
SQLを使用すると、クエリを記述してデータベースを操作できます。
クエリの例は次のようになります。
SELECT * FROM customers;
このSELECTを使用する ステートメントの場合、クエリはすべてを選択します 顧客のテーブルのすべての列からのデータであり、次のようなデータを返します。
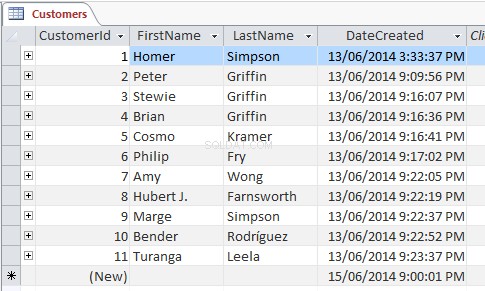
アスタリスクのワイルドカード文字(*)は、「すべて」を示します。 」を選択し、すべてを選択します 行と列。代わりに特定の列名に置き換えることができます—ここでは、それらの列のみがクエリによって返されます
SELECT FirstName, LastName FROM customers;
WHEREを追加する 句を使用すると、返されるものをフィルタリングできます:
SELECT * FROM customers WHERE age >= 30 ORDER BY age ASC;このクエリは、年齢の商品テーブルからすべてのデータを返します 30より大きい値。
ORDER BYの使用 キーワードは、結果が年齢列を使用して最小値から最大値の順に並べられることを意味します
INSERT INTOの使用 ステートメント、テーブルに新しいデータを追加できます。これは、customersテーブルに新しいユーザーを追加する基本的な例です。
INSERT INTO customers(FirstName, LastName, address, email)
VALUES ('Jason', 'Dsouza', 'McLaren Vale, South Australia', 'test@fakeGmail.com');もちろん、これらの例は、SQL言語で実行できることのごく一部を示しています。詳細については、このガイドをご覧ください。
私たちはビッグデータの時代に生きています。ビッグデータでは、データを使用して洞察を見つけ、戦略、マーケティング、広告、その他の多数の業務に情報を提供しています。
Google、Amazon、AirBnbなどの大企業は、顧客体験を向上させるための基盤として、大規模なリレーショナルデータベースを利用しています。 SQLを理解することは、データサイエンティストやアナリストだけでなく、すべての人にとって優れたスキルです。
ほんの数分前、お気に入りの靴をグーグルで検索していたときに、突然YouTubeの広告が靴に表示されたと思いますか。それがSQL(またはSQLの形式)の機能です!
SQLとMySQL
先に進む前に、よく混乱するトピック、つまりSQLとMySQLの違いを明確にしておきたいと思います。結局のところ、彼らはそうではありません 同じことです!
SQLは言語ですが、MySQLはSQLを実装するためのシステムです。
SQL リレーショナルデータベースを管理するクエリを記述できる構文の概要を説明します。
MySQL データベースシステムです サーバー上で実行されます。 SQL構文を使用してクエリを記述し、MySQLデータベースを管理できます。
MySQLに加えて、SQLを実装する他のシステムがあります。最も人気のあるものには次のものがあります:
- SQLite
- Oracleデータベース
- PostgreSQL
- Microsoft SQL Server
ほとんどの場合、データベース管理システムにはMySQLが推奨されます。多くの一般的なコンテンツ管理システム(Wordpressなど)はデフォルトでMySQLを使用するため、MySQLを使用してこれらのアプリケーションを管理することをお勧めします。
MySQLを使用するには、MySQLをシステムにインストールする必要があります:
WindowsにMySQLをインストールするための推奨される方法は、MySQLWebサイトのMSIインストーラーを使用することです。
このリソースは、インストールプロセスをガイドします。
macOSにMySQLをインストールする
macOSでは、MySQLのインストールにはインストーラーのダウンロードも含まれます。
このリソースは、インストールプロセスをガイドします。
MySQLがシステムにインストールされたので、ある種のSQL管理アプリケーションを使用することをお勧めします。 データベースの管理をはるかに簡単にするため。
主に同じ仕事をするアプリはたくさんあるので、どれを使用するかはあなた自身の個人的な好み次第です:
- Oracleによって開発されたMySQLWorkbench
- phpMyAdmin(Webブラウザで動作)
- HeidiSQL (Windowsに推奨)
- Sequel Pro (macOSに推奨)
独自のSQLクエリの作成を開始する準備ができたら、独自のデータベースを作成するのではなく、ダミーデータをインポートすることを検討してください。
無料でダウンロードできるダミーデータベースをいくつか紹介します。
SQLチートシート–ケーキの上のアイシング
SQLキーワード
ここでは、SQLステートメントで使用されるキーワードのコレクション、説明、および必要に応じて例を見つけることができます。より高度なキーワードの中には、専用のセクションがあるものもあります。
例の横にMySQLが記載されている場合、これは、この例がMySQLデータベースにのみ適用可能であることを意味します(他のデータベースシステムとは対照的です)。
ADD -- Adds a new column to an existing table
ADD CONSTRAINT -- Creates a new constraint on an existing table, which is used to specify rules for any data in the table.
ALTER TABLE -- Adds, deletes or edits columns in a table. It can also be used to add and delete constraints in a table, as per the above.
ALTER COLUMN -- Changes the data type of a table’s column.
ALL -- Returns true if all of the subquery values meet the passed condition.
AND -- Used to join separate conditions within a WHERE clause.
ANY -- Returns true if any of the subquery values meet the given condition.
AS -- Renames a table or column with an alias value which only exists for the duration of the query.
ASC -- Used with ORDER BY to return the data in ascending order.
BETWEEN -- Selects values within the given range.
CASE -- Changes query output depending on conditions.
CHECK -- Adds a constraint that limits the value which can be added to a column.
CREATE DATABASE -- Creates a new database.
CREATE TABLE -- Creates a new table.
DEFAULT -- Sets a default value for a column
DELETE -- Delete data from a table.
DESC -- Used with ORDER BY to return the data in descending order.
DROP COLUMN -- Deletes a column from a table.
DROP DATABASE -- Deletes the entire database.
DROP DEAFULT -- Removes a default value for a column.
DROP TABLE -- Deletes a table from a database.
EXISTS -- Checks for the existence of any record within the subquery, returning true if one or more records are returned.
FROM -- Specifies which table to select or delete data from.
IN -- Used alongside a WHERE clause as a shorthand for multiple OR conditions.
INSERT INTO -- Adds new rows to a table.
IS NULL -- Tests for empty (NULL) values.
IS NOT NULL -- The reverse of NULL. Tests for values that aren’t empty / NULL.
LIKE -- Returns true if the operand value matches a pattern.
NOT -- Returns true if a record DOESN’T meet the condition.
OR -- Used alongside WHERE to include data when either condition is true.
ORDER BY -- Used to sort the result data in ascending (default) or descending order through the use of ASC or DESC keywords.
ROWNUM -- Returns results where the row number meets the passed condition.
SELECT -- Used to select data from a database, which is then returned in a results set.
SELECT DISTINCT -- Sames as SELECT, except duplicate values are excluded.
SELECT INTO -- Copies data from one table and inserts it into another.
SELECT TOP -- Allows you to return a set number of records to return from a table.
SET -- Used alongside UPDATE to update existing data in a table.
SOME -- Identical to ANY.
TOP -- Used alongside SELECT to return a set number of records from a table.
TRUNCATE TABLE -- Similar to DROP, but instead of deleting the table and its data, this deletes only the data.
UNION -- Combines the results from 2 or more SELECT statements and returns only distinct values.
UNION ALL -- The same as UNION, but includes duplicate values.
UNIQUE -- This constraint ensures all values in a column are unique.
UPDATE -- Updates existing data in a table.
VALUES -- Used alongside the INSERT INTO keyword to add new values to a table.
WHERE -- Filters results to only include data which meets the given condition.
コメントを使用すると、直接実行せずにSQLステートメントのセクションを説明できます。
SQLには、1行と複数行の2種類のコメントがあります。
SQLの単一行コメント
1行のコメントは「--」で始まります。これらの2文字から行末までのテキストはすべて無視されます。
-- This part is ignored
SELECT * FROM customers;SQLの複数行コメント
複数行のコメントは/*で始まり、*/で終わります。終了文字が見つかるまで、複数の行にまたがって伸びます。
/*
This is a multiline comment.
It can span across multiple lines.
*/
SELECT * FROM customers;
/*
This is another comment.
You can even put code within a comment to prevent its execution
SELECT * FROM icecreams;
*/MySQLのデータ型
新しいテーブルを作成するとき、または既存のテーブルを編集するときは、各列が受け入れるデータのタイプを指定する必要があります。
この例では、idに渡されるデータ 列はint(整数)である必要がありますが、FirstName 列にVARCHARがあります 最大255文字のデータ型。
CREATE TABLE customers(
id int,
FirstName varchar(255)
);1。文字列データ型
CHAR(size) -- Fixed length string which can contain letters, numbers and special characters. The size parameter sets the maximum string length, from 0 – 255 with a default of 1.
VARCHAR(size) -- Variable length string similar to CHAR(), but with a maximum string length range from 0 to 65535.
BINARY(size) -- Similar to CHAR() but stores binary byte strings.
VARBINARY(size) -- Similar to VARCHAR() but for binary byte strings.
TINYBLOB -- Holds Binary Large Objects (BLOBs) with a max length of 255 bytes.
TINYTEXT -- Holds a string with a maximum length of 255 characters. Use VARCHAR() instead, as it’s fetched much faster.
TEXT(size) -- Holds a string with a maximum length of 65535 bytes. Again, better to use VARCHAR().
BLOB(size) -- Holds Binary Large Objects (BLOBs) with a max length of 65535 bytes.
MEDIUMTEXT -- Holds a string with a maximum length of 16,777,215 characters.
MEDIUMBLOB -- Holds Binary Large Objects (BLOBs) with a max length of 16,777,215 bytes.
LONGTEXT -- Holds a string with a maximum length of 4,294,967,295 characters.
LONGBLOB -- Holds Binary Large Objects (BLOBs) with a max length of 4,294,967,295 bytes.
ENUM(a, b, c, etc…) -- A string object that only has one value, which is chosen from a list of values which you define, up to a maximum of 65535 values. If a value is added which isn’t on this list, it’s replaced with a blank value instead.
SET(a, b, c, etc…) -- A string object that can have 0 or more values, which is chosen from a list of values which you define, up to a maximum of 64 values.
2。数値データ型
BIT(size) -- A bit-value type with a default of 1. The allowed number of bits in a value is set via the size parameter, which can hold values from 1 to 64.
TINYINT(size) -- A very small integer with a signed range of -128 to 127, and an unsigned range of 0 to 255. Here, the size parameter specifies the maximum allowed display width, which is 255.
BOOL -- Essentially a quick way of setting the column to TINYINT with a size of 1. 0 is considered false, whilst 1 is considered true.
BOOLEAN -- Same as BOOL.
SMALLINT(size) -- A small integer with a signed range of -32768 to 32767, and an unsigned range from 0 to 65535. Here, the size parameter specifies the maximum allowed display width, which is 255.
MEDIUMINT(size) -- A medium integer with a signed range of -8388608 to 8388607, and an unsigned range from 0 to 16777215. Here, the size parameter specifies the maximum allowed display width, which is 255.
INT(size) -- A medium integer with a signed range of -2147483648 to 2147483647, and an unsigned range from 0 to 4294967295. Here, the size parameter specifies the maximum allowed display width, which is 255.
INTEGER(size) -- Same as INT.
BIGINT(size) -- A medium integer with a signed range of -9223372036854775808 to 9223372036854775807, and an unsigned range from 0 to 18446744073709551615. Here, the size parameter specifies the maximum allowed display width, which is 255.
FLOAT(p) -- A floating point number value. If the precision (p) parameter is between 0 to 24, then the data type is set to FLOAT(), whilst if it's from 25 to 53, the data type is set to DOUBLE(). This behaviour is to make the storage of values more efficient.
DOUBLE(size, d) -- A floating point number value where the total digits are set by the size parameter, and the number of digits after the decimal point is set by the d parameter.
DECIMAL(size, d) -- An exact fixed point number where the total number of digits is set by the size parameters, and the total number of digits after the decimal point is set by the d parameter.
DEC(size, d) -- Same as DECIMAL.3。日付/時刻データ型
DATE -- A simple date in YYYY-MM–DD format, with a supported range from ‘1000-01-01’ to ‘9999-12-31’.
DATETIME(fsp) -- A date time in YYYY-MM-DD hh:mm:ss format, with a supported range from ‘1000-01-01 00:00:00’ to ‘9999-12-31 23:59:59’. By adding DEFAULT and ON UPDATE to the column definition, it automatically sets to the current date/time.
TIMESTAMP(fsp) -- A Unix Timestamp, which is a value relative to the number of seconds since the Unix epoch (‘1970-01-01 00:00:00’ UTC). This has a supported range from ‘1970-01-01 00:00:01’ UTC to ‘2038-01-09 03:14:07’ UTC.
By adding DEFAULT CURRENT_TIMESTAMP and ON UPDATE CURRENT TIMESTAMP to the column definition, it automatically sets to current date/time.
TIME(fsp) -- A time in hh:mm:ss format, with a supported range from ‘-838:59:59’ to ‘838:59:59’.
YEAR -- A year, with a supported range of ‘1901’ to ‘2155’.SQLオペレーター
1。 SQLの算術演算子
+ -- Add
– -- Subtract
* -- Multiply
/ -- Divide
% -- Modulus2。 SQLのビット演算子
& -- Bitwise AND
| -- Bitwise OR
^-- Bitwise XOR3。 SQLの比較演算子
= -- Equal to
> -- Greater than
< -- Less than
>= -- Greater than or equal to
<= -- Less than or equal to
<> -- Not equal to4。 SQLの複合演算子
+= -- Add equals
-= -- Subtract equals
*= -- Multiply equals
/= -- Divide equals
%= -- Modulo equals
&= -- Bitwise AND equals
^-= -- Bitwise exclusive equals
|*= -- Bitwise OR equalsSQL関数
1。 SQLの文字列関数
ASCII -- Returns the equivalent ASCII value for a specific character.
CHAR_LENGTH -- Returns the character length of a string.
CHARACTER_LENGTH -- Same as CHAR_LENGTH.
CONCAT -- Adds expressions together, with a minimum of 2.
CONCAT_WS -- Adds expressions together, but with a separator between each value.
FIELD -- Returns an index value relative to the position of a value within a list of values.
FIND IN SET -- Returns the position of a string in a list of strings.
FORMAT -- When passed a number, returns that number formatted to include commas (eg 3,400,000).
INSERT -- Allows you to insert one string into another at a certain point, for a certain number of characters.
INSTR -- Returns the position of the first time one string appears within another.
LCASE -- Converts a string to lowercase.
LEFT -- Starting from the left, extracts the given number of characters from a string and returns them as another.
LENGTH -- Returns the length of a string, but in bytes.
LOCATE -- Returns the first occurrence of one string within another,
LOWER -- Same as LCASE.
LPAD -- Left pads one string with another, to a specific length.
LTRIM -- Removes any leading spaces from the given string.
MID -- Extracts one string from another, starting from any position.
POSITION -- Returns the position of the first time one substring appears within another.
REPEAT -- Allows you to repeat a string
REPLACE -- Allows you to replace any instances of a substring within a string, with a new substring.
REVERSE -- Reverses the string.
RIGHT -- Starting from the right, extracts the given number of characters from a string and returns them as another.
RPAD -- Right pads one string with another, to a specific length.
RTRIM -- Removes any trailing spaces from the given string.
SPACE -- Returns a string full of spaces equal to the amount you pass it.
STRCMP -- Compares 2 strings for differences
SUBSTR -- Extracts one substring from another, starting from any position.
SUBSTRING -- Same as SUBSTR
SUBSTRING_INDEX -- Returns a substring from a string before the passed substring is found the number of times equals to the passed number.
TRIM -- Removes trailing and leading spaces from the given string. Same as if you were to run LTRIM and RTRIM together.
UCASE -- Converts a string to uppercase.
UPPER -- Same as UCASE.2。 SQLの数値関数
ABS -- Returns the absolute value of the given number.
ACOS -- Returns the arc cosine of the given number.
ASIN -- Returns the arc sine of the given number.
ATAN -- Returns the arc tangent of one or 2 given numbers.
ATAN2 -- Returns the arc tangent of 2 given numbers.
AVG -- Returns the average value of the given expression.
CEIL -- Returns the closest whole number (integer) upwards from a given decimal point number.
CEILING -- Same as CEIL.
COS -- Returns the cosine of a given number.
COT -- Returns the cotangent of a given number.
COUNT -- Returns the amount of records that are returned by a SELECT query.
DEGREES -- Converts a radians value to degrees.
DIV -- Allows you to divide integers.
EXP -- Returns e to the power of the given number.
FLOOR -- Returns the closest whole number (integer) downwards from a given decimal point number.
GREATEST -- Returns the highest value in a list of arguments.
LEAST -- Returns the smallest value in a list of arguments.
LN -- Returns the natural logarithm of the given number.
LOG -- Returns the natural logarithm of the given number, or the logarithm of the given number to the given base.
LOG10 -- Does the same as LOG, but to base 10.
LOG2 -- Does the same as LOG, but to base 2.
MAX -- Returns the highest value from a set of values.
MIN -- Returns the lowest value from a set of values.
MOD -- Returns the remainder of the given number divided by the other given number.
PI -- Returns PI.
POW -- Returns the value of the given number raised to the power of the other given number.
POWER -- Same as POW.
RADIANS -- Converts a degrees value to radians.
RAND -- Returns a random number.
ROUND -- Rounds the given number to the given amount of decimal places.
SIGN -- Returns the sign of the given number.
SIN -- Returns the sine of the given number.
SQRT -- Returns the square root of the given number.
SUM -- Returns the value of the given set of values combined.
TAN -- Returns the tangent of the given number.
TRUNCATE -- Returns a number truncated to the given number of decimal places.3。 SQLの日付関数
ADDDATE -- Adds a date interval (eg: 10 DAY) to a date (eg: 20/01/20) and returns the result (eg: 20/01/30).
ADDTIME -- Adds a time interval (eg: 02:00) to a time or datetime (05:00) and returns the result (07:00).
CURDATE -- Gets the current date.
CURRENT_DATE -- Same as CURDATE.
CURRENT_TIME -- Gest the current time.
CURRENT_TIMESTAMP -- Gets the current date and time.
CURTIME -- Same as CURRENT_TIME.
DATE -- Extracts the date from a datetime expression.
DATEDIFF -- Returns the number of days between the 2 given dates.
DATE_ADD -- Same as ADDDATE.
DATE_FORMAT -- Formats the date to the given pattern.
DATE_SUB -- Subtracts a date interval (eg: 10 DAY) to a date (eg: 20/01/20) and returns the result (eg: 20/01/10).
DAY -- Returns the day for the given date.
DAYNAME -- Returns the weekday name for the given date.
DAYOFWEEK -- Returns the index for the weekday for the given date.
DAYOFYEAR -- Returns the day of the year for the given date.
EXTRACT -- Extracts from the date the given part (eg MONTH for 20/01/20 = 01).
FROM DAYS -- Returns the date from the given numeric date value.
HOUR -- Returns the hour from the given date.
LAST DAY -- Gets the last day of the month for the given date.
LOCALTIME -- Gets the current local date and time.
LOCALTIMESTAMP -- Same as LOCALTIME.
MAKEDATE -- Creates a date and returns it, based on the given year and number of days values.
MAKETIME -- Creates a time and returns it, based on the given hour, minute and second values.
MICROSECOND -- Returns the microsecond of a given time or datetime.
MINUTE -- Returns the minute of the given time or datetime.
MONTH -- Returns the month of the given date.
MONTHNAME -- Returns the name of the month of the given date.
NOW -- Same as LOCALTIME.
PERIOD_ADD -- Adds the given number of months to the given period.
PERIOD_DIFF -- Returns the difference between 2 given periods.
QUARTER -- Returns the year quarter for the given date.
SECOND -- Returns the second of a given time or datetime.
SEC_TO_TIME -- Returns a time based on the given seconds.
STR_TO_DATE -- Creates a date and returns it based on the given string and format.
SUBDATE -- Same as DATE_SUB.
SUBTIME -- Subtracts a time interval (eg: 02:00) to a time or datetime (05:00) and returns the result (03:00).
SYSDATE -- Same as LOCALTIME.
TIME -- Returns the time from a given time or datetime.
TIME_FORMAT -- Returns the given time in the given format.
TIME_TO_SEC -- Converts and returns a time into seconds.
TIMEDIFF -- Returns the difference between 2 given time/datetime expressions.
TIMESTAMP -- Returns the datetime value of the given date or datetime.
TO_DAYS -- Returns the total number of days that have passed from ‘00-00-0000’ to the given date.
WEEK -- Returns the week number for the given date.
WEEKDAY -- Returns the weekday number for the given date.
WEEKOFYEAR -- Returns the week number for the given date.
YEAR -- Returns the year from the given date.
YEARWEEK -- Returns the year and week number for the given date.4。 SQLのその他の関数
BIN -- Returns the given number in binary.
BINARY -- Returns the given value as a binary string.
CAST -- Converst one type into another.
COALESCE -- From a list of values, returns the first non-null value.
CONNECTION_ID -- For the current connection, returns the unique connection ID.
CONV -- Converts the given number from one numeric base system into another.
CONVERT -- Converts the given value into the given datatype or character set.
CURRENT_USER -- Returns the user and hostname which was used to authenticate with the server.
DATABASE -- Gets the name of the current database.
GROUP BY -- Used alongside aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the results.
HAVING -- Used in the place of WHERE with aggregate functions.
IF -- If the condition is true it returns a value, otherwise it returns another value.
IFNULL -- If the given expression equates to null, it returns the given value.
ISNULL -- If the expression is null, it returns 1, otherwise returns 0.
LAST_INSERT_ID -- For the last row which was added or updated in a table, returns the auto increment ID.
NULLIF -- Compares the 2 given expressions. If they are equal, NULL is returned, otherwise the first expression is returned.
SESSION_USER -- Returns the current user and hostnames.
SYSTEM_USER -- Same as SESSION_USER.
USER -- Same as SESSION_USER.
VERSION -- Returns the current version of the MySQL powering the database.SQLのワイルドカード文字
SQLでは、ワイルドカードはLIKEで使用される特殊文字です。 およびNOT LIKE キーワード。これにより、高度なパターンのデータをかなり効率的に検索できます。
% -- Equates to zero or more characters.
-- Example: Find all customers with surnames ending in ‘ory’.
SELECT * FROM customers
WHERE surname LIKE '%ory';
_ -- Equates to any single character.
-- Example: Find all customers living in cities beginning with any 3 characters, followed by ‘vale’.
SELECT * FROM customers
WHERE city LIKE '_ _ _vale';
[charlist] -- Equates to any single character in the list.
-- Example: Find all customers with first names beginning with J, K or T.
SELECT * FROM customers
WHERE first_name LIKE '[jkt]%';SQLキー
リレーショナルデータベースには、プライマリの概念があります。 および外国 キー。 SQLテーブルでは、これらは制約として含まれ、テーブルには主キー、外部キー、またはその両方を含めることができます。
1。 SQLの主キー
プライマリを使用すると、テーブル内の各レコードを一意に識別できます。テーブルごとに持つことができる主キーは1つだけであり、この制約を任意の単一または列の組み合わせに割り当てることができます。ただし、これは、この列内の各値が一意である必要があることを意味します。
通常、テーブルでは、ID列が主キーであり、通常はAUTO_INCREMENTとペアになっています。 キーワード。これは、新しいレコードが作成されると、値が自動的に増加することを意味します。
例(MySQL)
新しいテーブルを作成し、主キーをID列に設定します。
CREATE TABLE customers (
id int NOT NULL AUTO_INCREMENT,
FirstName varchar(255),
Last Name varchar(255) NOT NULL,
address varchar(255),
email varchar(255),
PRIMARY KEY (id)
);2。 SQLの外部キー
1つまたは複数の列に外部キーを適用できます。 リンクに使用します リレーショナルデータベースに2つのテーブルをまとめます。
外部キーを含むテーブルは、子と呼ばれます。 キー、
参照(または候補)キーを含むテーブルは、親と呼ばれます。 テーブル。
これは基本的に、列データが2つのテーブル間で共有されることを意味します。これは、外部キーによって、親テーブルにも存在しない無効なデータが挿入されるのを防ぐためです。
例(MySQL)
新しいテーブルを作成し、他のテーブルのIDを参照する列を外部キーに変換します。
CREATE TABLE orders (
id int NOT NULL,
user_id int,
product_id int,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (product_id) REFERENCES products(id)
);SQLのインデックス
インデックスは、データの取得をより迅速かつ効率的にするために頻繁に検索される列に割り当てることができる属性です。
CREATE INDEX -- Creates an index named ‘idx_test’ on the first_name and surname columns of the users table. In this instance, duplicate values are allowed.
CREATE INDEX idx_test
ON users (first_name, surname);
CREATE UNIQUE INDEX -- The same as the above, but no duplicate values.
CREATE UNIQUE INDEX idx_test
ON users (first_name, surname);
DROP INDEX -- Removes an index.
ALTER TABLE users
DROP INDEX idx_test;SQL結合
SQLでは、JOIN 句は、両方のテーブルに含まれる共通の列に基づいて、複数のテーブルのデータを組み合わせた結果を返すために使用されます。
使用できるさまざまな結合があります:
- 内部結合(デフォルト): 両方のテーブルで値が一致するレコードを返します。
- 左参加: 最初のテーブルのすべてのレコードと、2番目のテーブルの一致するレコードを返します。
- 右参加: 2番目のテーブルのすべてのレコードと、最初のテーブルの一致するレコードを返します。
- 完全参加: 一致する場合は、両方のテーブルからすべてのレコードを返します。
結合がどのように機能するかを視覚化する一般的な方法は次のとおりです。

SELECT orders.id, users.FirstName, users.Surname, products.name as ‘product name’
FROM orders
INNER JOIN users on orders.user_id = users.id
INNER JOIN products on orders.product_id = products.id;ビューは基本的にSQL結果セットであり、ラベルの下でデータベースに格納されるため、クエリを再実行しなくても後でビューに戻ることができます。
これらは、何度も必要になる可能性のあるコストのかかるSQLクエリがある場合に特に役立ちます。したがって、同じ結果セットを生成するために何度も実行する代わりに、一度実行してビューとして保存することができます。
ビューを作成するには、次のようにします。
CREATE VIEW priority_users AS
SELECT * FROM users
WHERE country = ‘United Kingdom’;その後、保存された結果セットにアクセスする必要がある場合は、次のようにアクセスできます。
SELECT * FROM [priority_users];
CREATE OR REPLACEを使用 コマンドを使用すると、次のようにビューを更新できます:
CREATE OR REPLACE VIEW [priority_users] AS
SELECT * FROM users
WHERE country = ‘United Kingdom’ OR country=’USA’;
ビューを削除するには、DROP VIEWを使用するだけです。 コマンド。
DROP VIEW priority_users;Webサイトとアプリケーションの大部分は、何らかの方法でリレーショナルデータベースを使用しています。これにより、SQLを知ることは非常に価値があり、より複雑で機能的なシステムを作成できます。
今後の記事の最新情報については、Twitterでフォローしてください。幸せな学習!