- ピボットテーブルについて簡単に説明します
- ツール(dbForge Studio for MySQL)を使用したデータのピボット
- SQLによるデータのピボット
- SQLServerのT-SQLベースの例
- MySQLの例
- データピボットの自動化、動的なクエリの作成
ピボットテーブルについて簡単に説明します
この記事では、テーブルデータの行から列への変換について説明します。このような変換は、ピボットテーブルと呼ばれます。多くの場合、ピボットの結果は、統計データがレポートに適した、または必要な形式で表示される要約テーブルです。
さらに、このようなデータ変換は、データベースが正規化されておらず、情報が最適でない形式でデータベースに格納されている場合に役立ちます。したがって、データベースを再編成してデータを新しいテーブルに転送したり、必要なデータ表現を生成したりする場合は、データピボットが役立ちます。つまり、値を行から結果の列に移動します。
以下は、古い製品テーブル(ProductsOld)と新しいテーブル(ProductsNew)の例です。このような結果を簡単に実現できるのは、行から列への変換です。
これがピボットテーブルの例です。
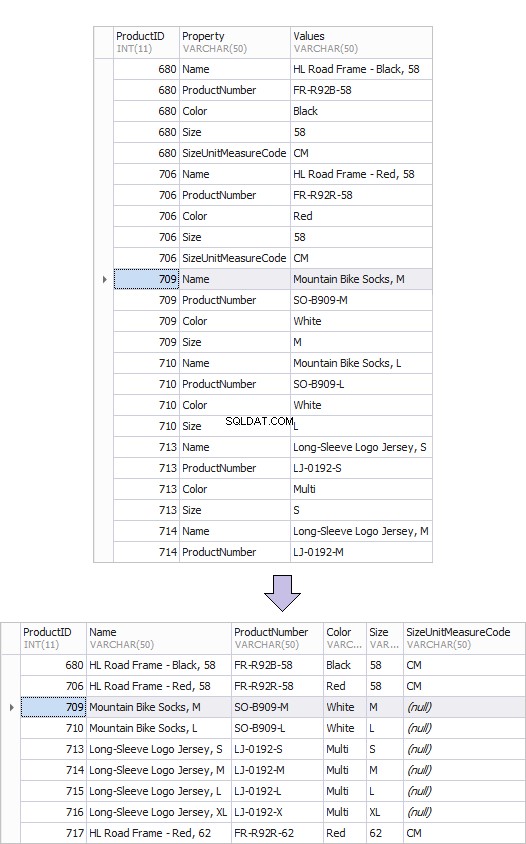
ツール(dbForge Studio for MySQL)を使用したデータのピボット
便利なグラフィカル環境でデータピボットを実装できるツールを備えたアプリケーションがあります。たとえば、dbForge Studio for MySQLには、わずか数ステップで目的の結果を提供するピボットテーブル機能が含まれています。

注文の簡略化された表を使用した例を見てみましょう– PurchaseOrderHeader 。
CREATE TABLE PurchaseOrderHeader ( PurchaseOrderID INT(11) NOT NULL, EmployeeID INT(11) NOT NULL, VendorID INT(11) NOT NULL, PRIMARY KEY (PurchaseOrderID) ); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (1, 258, 1580); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (2, 254, 1496); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (3, 257, 1494); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (4, 261, 1650); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (5, 251, 1654); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (6, 253, 1664); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (7, 255, 1678); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (8, 256, 1616); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (9, 259, 1492); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (10, 250, 1602); INSERT PurchaseOrderHeader(PurchaseOrderID, EmployeeID, VendorID) VALUES (11, 258, 1540); ...
表から選択し、特定のサプライヤからの特定の従業員による注文数を決定する必要があると想定します。情報が必要な従業員のリスト– 250、251、252、253、254。
レポートの推奨されるビューは次のとおりです。
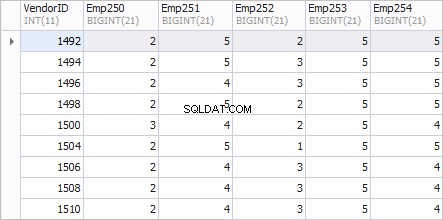
左の列VendorID ベンダーのIDを表示します。列Emp250 、 Emp251 、 Emp252 、 Emp253 、および Emp254 注文数を表示します。
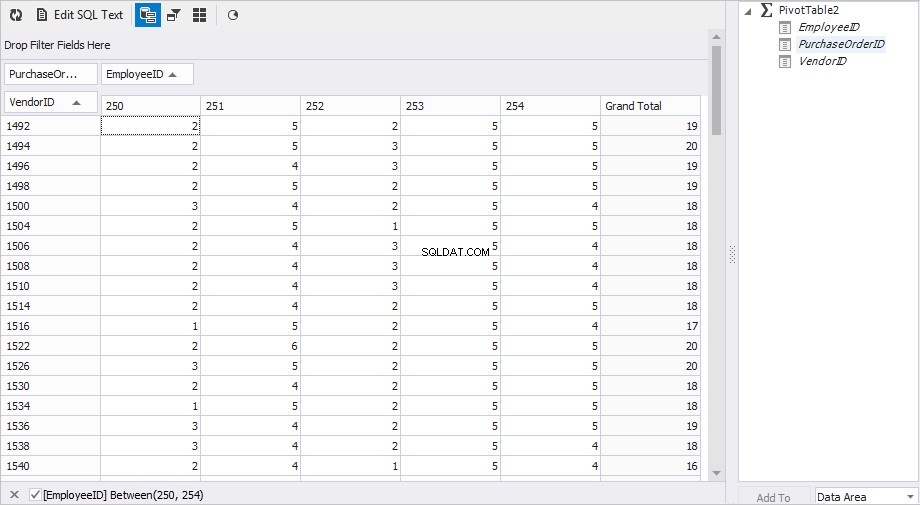
dbForge Studio for MySQLでこれを実現するには、次のことを行う必要があります。
- ドキュメントの「ピボットテーブル」表現のデータソースとしてテーブルを追加します。データベースエクスプローラーで、 PurchaseOrderHeaderを右クリックします。 テーブルを選択し、送信先を選択します 次に、ピボットテーブル ポップアップメニューで。
- 値が行になる列を指定します。 VendorIDをドラッグします [行フィールドをここにドロップ]ボックスの列。
- 値が列になる列を指定します。 EmployeeIDをドラッグします [列フィールドをここにドロップ]ボックスに列を追加します。必要な従業員(250、251、252、253、254)にフィルターを設定することもできます。
- 値がデータになる列を指定します。 PurchaseOrderIDをドラッグします [データアイテムをここにドロップ]ボックスの列。
- PurchaseOrderIDのプロパティ内 列で、集計のタイプを指定します–値の数 。
必要な結果がすぐに得られました。
SQLによるデータのピボット
もちろん、SQLクエリを作成することにより、データベースを使用してデータ変換を実行できます。ただし、少し問題があります。MySQLには、これを可能にする特定のステートメントがありません。
SQLServerのT-SQLベースの例
たとえば、SqlServerとOracleには、このようなデータ変換を可能にするPIVOT演算子があります。 SqlServerを使用した場合、クエリは次のようになります。
SELECT
VendorID
,[250] AS Emp1
,[251] AS Emp2
,[252] AS Emp3
,[253] AS Emp4
,[254] AS Emp5
FROM (SELECT
PurchaseOrderID
,EmployeeID
,VendorID
FROM Purchasing.PurchaseOrderHeader) p
PIVOT
(
COUNT(PurchaseOrderID) FOR EmployeeID IN ([250], [251], [252], [253], [254])
) AS t
ORDER BY t.VendorID;
MySQLの例
MySQLでは、SQLの手段を使用する必要があります。データはベンダー列でグループ化する必要があります– VendorID 、および必要な従業員ごとに( EmployeeID )、集計関数を使用して別の列を作成する必要があります。
この場合、注文数を計算する必要があるため、集計関数COUNTを使用します。
ソーステーブルでは、すべての従業員に関する情報が1つの列に格納されます EmployeeID 、特定の従業員の注文数を計算する必要があるため、特定の行のみを処理するように集計関数を教える必要があります。
集計関数はNULL値を考慮しないため、この特殊性を目的に使用します。
条件演算子IFまたはCASEを使用できます。これは、目的の従業員に特定の値を返します。それ以外の場合は、単にNULLを返します。その結果、COUNT関数はNULL以外の値のみをカウントします。
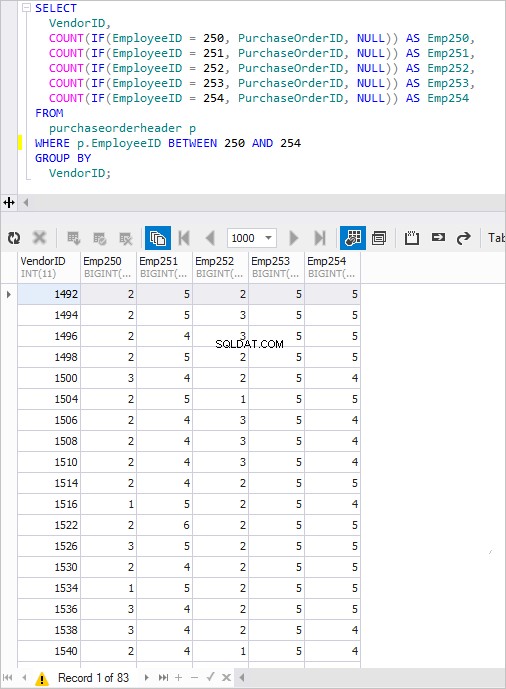
結果のクエリは次のとおりです。
SELECT VendorID, COUNT(IF(EmployeeID = 250, PurchaseOrderID, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, PurchaseOrderID, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, PurchaseOrderID, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, PurchaseOrderID, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, PurchaseOrderID, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;>
またはこのように:
VendorID, COUNT(IF(EmployeeID = 250, 1, NULL)) AS Emp250, COUNT(IF(EmployeeID = 251, 1, NULL)) AS Emp251, COUNT(IF(EmployeeID = 252, 1, NULL)) AS Emp252, COUNT(IF(EmployeeID = 253, 1, NULL)) AS Emp253, COUNT(IF(EmployeeID = 254, 1, NULL)) AS Emp254 FROM PurchaseOrderHeader p WHERE p.EmployeeID BETWEEN 250 AND 254 GROUP BY VendorID;
実行すると、おなじみの結果が得られます。
データピボットの自動化、動的なクエリの作成
ご覧のとおり、クエリには一定の一貫性があります。つまり、変換されたすべての列が同様の方法で形成されます。クエリを作成するには、テーブルから特定の値を知る必要があります。ピボットクエリを作成するには、可能なすべての値を確認する必要があります。その場合にのみ、クエリを作成する必要があります。または、このタスクをサーバーに渡して、サーバーにこれらの値を取得させ、ルーチンタスクを動的に実行させることもできます。
新しいテーブルProductsNewを作成した最初の例に戻りましょう。 ProductsOldから テーブル。そこでは、プロパティの値が制限されており、可能なすべての値を知ることさえできません。プロパティの名前とその値が格納されている場所に関する情報しかありません。これらはプロパティです および値 それぞれ列。
SQLクエリを作成するアルゴリズム全体は、値を取得することであり、そこからクエリの変更できない部分の新しい列と連結が形成されます。
SELECT
GROUP_CONCAT(
CONCAT(
' MAX(IF(Property = ''',
t.Property,
''', Value, NULL)) AS ',
t.Property
)
) INTO @PivotQuery
FROM
(SELECT
Property
FROM
ProductOld
GROUP BY
Property) t;
SET @PivotQuery = CONCAT('SELECT ProductID,', @PivotQuery, ' FROM ProductOld GROUP BY ProductID');
変数@PivotQueryはクエリを格納し、テキストはわかりやすくするためにフォーマットされています。
SELECT ProductID, MAX(IF(Property = 'Color', Value, NULL)) AS Color, MAX(IF(Property = 'Name', Value, NULL)) AS Name, MAX(IF(Property = 'ProductNumber', Value, NULL)) AS ProductNumber, MAX(IF(Property = 'Size', Value, NULL)) AS Size, MAX(IF(Property = 'SizeUnitMeasureCode', Value, NULL)) AS SizeUnitMeasureCode FROM ProductOld GROUP BY ProductID
それを実行した後、ProductsNewテーブルのスキームに対応する望ましい結果が得られます。
さらに、変数@PivotQueryからのクエリは、MySQLステートメントEXECUTEを使用してスクリプトで実行できます。
PREPARE statement FROM @PivotQuery; EXECUTE statement; DEALLOCATE PREPARE statement;
