MySQLレプリケーションは、Github、Twitter、Facebookなどの巨大な組織による高可用性のための最も一般的で広く使用されているソリューションです。セットアップは簡単ですが、ソフトウェアのアップグレード、レプリカノード間でのデータのドリフトやデータの不整合、トポロジの変更、フェイルオーバー、リカバリなど、メンテナンスからこのソリューションを使用する際に直面する課題があります。 MySQLがバージョン5.6をリリースしたとき、特にグローバルトランザクションID(GTID)、イベントチェックサム、マルチスレッドスレーブ、クラッシュセーフスレーブ/マスターを含むレプリケーションに多くの重要な機能拡張がもたらされました。 MySQL5.7とMySQL8.0でレプリケーションがさらに改善されました。
レプリケーションにより、1つのMySQLサーバー(プライマリ/マスター)からのデータを1つ以上のMySQLサーバー(レプリカ/スレーブ)にレプリケートできます。 MySQLレプリケーションはセットアップが非常に簡単で、読み取りワークロードをスケールアウトし、高可用性と地理的冗長性を提供し、バックアップと分析ジョブをオフロードするために使用されます。
MySQLReplicationが実際にどのように機能するかについて簡単に説明しましょう。 MySQLレプリケーションは幅広く、それを構成する方法とその使用方法は複数あります。デフォルトでは、非同期レプリケーションを使用します。これは、トランザクションがローカル環境で完了するときに機能します。イベントがスレーブに到達するという保証はありません。これは、緩く結合されたマスターとスレーブの関係です。ここで、
-
プライマリはレプリカを待機しません。
-
レプリカは、読み取る量とバイナリログのどのポイントから読み取るかを決定します。
-
レプリカは、変更の読み取りまたは適用において、マスターの背後に任意に遅れることがあります。
プライマリがクラッシュした場合、プライマリがコミットしたトランザクションがどのレプリカにも送信されていない可能性があります。その結果、プライマリから最も高度なレプリカへのフェイルオーバーは、この場合、前のサーバーと比較して実際にトランザクションが欠落している目的のプライマリへのフェイルオーバーにつながる可能性があります。
非同期レプリケーションでは、書き込みがスレーブに書き込まれる前にマスターによってローカルで確認されるため、書き込みレイテンシが低くなります。レプリカを追加してもレプリケーションの待機時間に影響しないため、読み取りスケーリングに最適です。非同期レプリケーションの優れた使用例には、読み取りスケーリング用の読み取りレプリカ、障害復旧用のライブバックアップコピー、および分析/レポートの展開が含まれます。
MySQL準同期レプリケーション
MySQLは準同期レプリケーションもサポートしています。この場合、マスターは、少なくとも1つのスレーブが変更をリレーログにコピーしてディスクにフラッシュするまで、クライアントへのトランザクションを確認しません。準同期レプリケーションを有効にするには、プラグインをインストールするための追加の手順が必要であり、指定されたMySQLマスターノードとスレーブノードで有効にする必要があります。
準同期は、高可用性とデータ損失が重要でない多くの場合に適した実用的なソリューションのようです。ただし、準同期は追加のラウンドトリップのためにパフォーマンスに影響を与え、データ損失に対する強力な保証を提供しないことを考慮する必要があります。コミットが正常に戻ると、データは少なくとも2つの場所(マスターと少なくとも1つのスレーブ)に存在することがわかります。マスターがコミットしても、マスターがスレーブからの確認応答を待機しているときにクラッシュが発生した場合は、トランザクションがどのスレーブにも到達していない可能性があります。この場合、コミットはアプリケーションに返されないため、これはそれほど大きな問題ではありません。将来トランザクションを再試行するのはアプリケーションのタスクです。覚えておくべき重要なことは、マスターに障害が発生し、スレーブが昇格した場合、古いマスターはレプリケーションチェーンに参加できないということです。状況によっては、これによりスレーブ上のデータとの競合が発生する可能性があります。つまり、スレーブがバイナリログイベントを受信した後、マスターがスレーブから確認応答を取得する前にマスターがクラッシュした場合です。したがって、安全な唯一の方法は、古いマスターのデータを破棄し、新しく昇格したマスターのデータを使用して最初からプロビジョニングすることです。
MySQL 5.7.7以降、デフォルトのバイナリログ形式またはbinlog_format変数は、5.7.7より前のSTATEMENTであったROWを使用します。さまざまなレプリケーション形式は、ソースのバイナリログイベントを記録するために使用される方法に対応しています。バイナリログに書き込まれたイベントはソースから読み取られ、レプリカで処理されるため、レプリケーションは機能します。イベントは、イベントのタイプに応じてさまざまなレプリケーション形式でバイナリログに記録されます。何を使用すればよいかわからないことが問題になる可能性があります。 MySQLには、STATEMENT、ROW、およびMIXEDの3つの形式のレプリケーションメソッドがあります。
-
ステートメントベースのレプリケーション(SBR)形式は、まさにそれが何であるか、つまり実行されるすべてのステートメントのレプリケーションストリームです。スレーブノードで再生されるマスター上。デフォルトでは、MySQLの従来の(非同期)レプリケーションは、スレーブへのレプリケートされたトランザクションを並行して実行しません。つまり、レプリケーションストリーム内のステートメントの順序が100%同じではない可能性があることを意味します。また、ステートメントを再生すると、ソースから実行されたときと同時に実行されなかったときに異なる結果が得られる可能性があります。これにより、プライマリとそのレプリカに対して一貫性のない状態が発生します。多くの同時スレッドでMySQLを実行している人はあまりいないため、これは長年の問題ではありませんでした。ただし、最新のマルチCPUアーキテクチャでは、これは実際には通常の日常のワークロードで発生する可能性が高くなっています。
-
ROWレプリケーション形式は、SBRに欠けているソリューションを提供します。行ベースのレプリケーション(RBR)ログ形式を使用する場合、ソースは、個々のテーブル行がどのように変更されたかを示すイベントをバイナリログに書き込みます。ソースからレプリカへのレプリケーションは、テーブル行への変更を表すイベントをレプリカにコピーすることで機能します。これは、より多くのデータを生成できることを意味し、レプリカのディスクスペースに影響を与え、ネットワークトラフィックとディスクI/Oに影響を与えます。ステートメントが多くの行を変更する場合、たとえばUPDATEステートメントの場合、ロールバックされたステートメントであっても、RBRはより多くのデータをバイナリログに書き込むことを検討してください。ポイントインタイムスナップショットの実行にも、さらに時間がかかる場合があります。大量のデータをバイナリログに書き込むために必要なロック時間が与えられると、同時実行性の問題が発生する可能性があります。
-
次に、これら2つの間にメソッドがあります。混合モードレプリケーション。このタイプのレプリケーションは、クエリにUUID()関数、トリガー、ストアドプロシージャ、UDF、およびその他のいくつかの例外が含まれている場合を除いて、常にステートメントをレプリケートします。混合モードではデータドリフトの問題は解決されないため、ステートメントベースのレプリケーションと一緒に使用することは避けてください。
マルチマスターセットアップを計画していますか?
循環レプリケーション(リングトポロジとも呼ばれます)は、MySQLレプリケーションの既知の一般的なセットアップです。これは、マルチマスターセットアップ(下の画像を参照)を実行するために使用され、マルチデータセンター環境を使用している場合に必要になることがよくあります。アプリケーションは他のデータセンターのマスターが書き込みを確認するのを待つことができないため、ローカルマスターが推奨されます。通常、自動インクリメントオフセットは、マスター間のデータの衝突を防ぐために使用されます。この方法で2人のマスターに相互に書き込みを実行させることは、広く受け入れられているソリューションです。
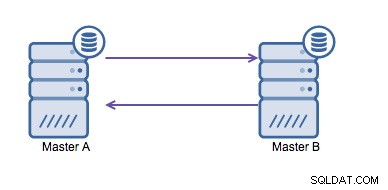
ただし、複数のデータセンターを同じデータベースに書き込む必要がある場合、最終的には、相互にデータを書き込む必要のある複数のマスターになります。 MySQL 5.7.6より前は、メッシュタイプのレプリケーションを実行する方法がなかったため、代わりに循環リングレプリケーションを使用することもできました。
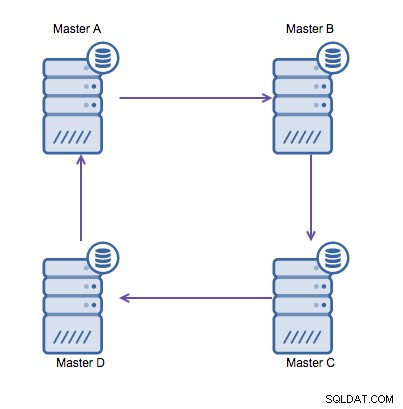
MySQLでのリングレプリケーションは、遅延、高可用性の理由で問題があります。 、およびデータドリフト。サーバーAにデータを書き込むには、サーバーDに到達するまでに3ホップかかります(サーバーBおよびCを介して)。 (従来の)MySQLレプリケーションはシングルスレッドであるため、レプリケーションで長時間実行されるクエリはリング全体を停止させる可能性があります。また、いずれかのサーバーがダウンすると、リングが壊れ、現在、フェイルオーバーソフトウェアはリング構造を修復できません。次に、データがサーバーAに書き込まれ、サーバーCまたはDで同時に変更されると、データドリフトが発生する可能性があります。
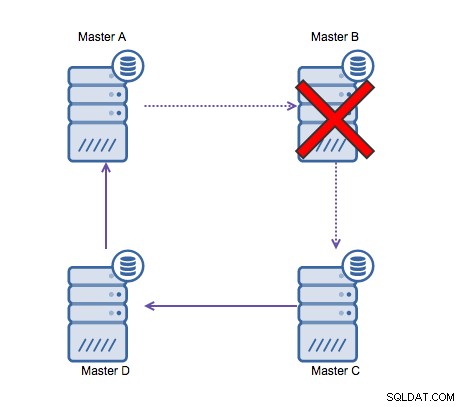
一般に、循環レプリケーションはMySQLに適していないため、次のようにする必要があります。絶対に避けてください。それを念頭に置いて設計されているため、GaleraClusterはマルチデータセンターの書き込みに適した代替手段になります。
さまざまなハウスキーピングバッチジョブは、古いデータのクリーンアップから別のソースから取得した「いいね」の平均の計算まで、さまざまなタスクを実行することがよくあります。これは、ジョブが設定された間隔で多くのデータベースアクティビティを作成し、ほとんどの場合、データベースに大量のデータを書き戻すことを意味します。当然、これはレプリケーションストリーム内のアクティビティが等しく増加することを意味します。
ステートメントベースのレプリケーションは、バッチジョブで使用される正確なクエリをレプリケートするため、クエリがマスターで処理されるのに30分かかった場合、スレーブスレッドは少なくとも同じ量の間停止します。時間。これは、他のデータが複製できないことを意味し、スレーブノードはマスターに遅れを取り始めます。これがフェールオーバーツールまたはプロキシのしきい値を超えると、クラスター内の使用可能なサーバーからこれらのスレーブノードが削除される可能性があります。ステートメントベースのレプリケーションを使用している場合は、ジョブのデータを小さなバッチで処理することで、これを防ぐことができます。
これで、行ベースのレプリケーションはクエリの代わりに行情報をレプリケートするため、これによる影響を受けないと思われるかもしれません。これは、DDLの変更の場合、レプリケーションがステートメントベースの形式に戻るため、部分的に当てはまります。また、多数のCRUD(作成、読み取り、更新、削除)操作は、レプリケーションストリームに影響を与えます。ほとんどの場合、これは依然としてシングルスレッド操作であるため、すべてのトランザクションは、レプリケーションを介して前のトランザクションが再生されるのを待ちます。これは、マスターの同時実行性が高い場合、レプリケーション中にスレーブがトランザクションの過負荷で停止する可能性があることを意味します。
これを回避するために、MariaDBとMySQLの両方が並列レプリケーションを提供します。実装はベンダーやバージョンごとに異なる場合があります。 MySQL 5.6は、クエリがスキーマによって分離されている限り、並列レプリケーションを提供します。 MariaDB10.0とMySQL5.7はどちらもスキーマ間の並列レプリケーションを処理できますが、他の境界があります。並列スレーブスレッドを介してクエリを実行すると、大量の書き込みを行う場合にレプリケーションストリームが高速化される可能性があります。それ以外の場合は、従来のシングルスレッドレプリケーションに固執することをお勧めします。
5.7のリリース以降、MySQLでのスキーマ変更またはDDL(データ定義言語)変更の管理が大幅に改善されました。 MySQL 8.0までは、サポートされているDDL変更アルゴリズムはCOPYとINPLACEです。
-
コピー:このアルゴリズムは、変更されたスキーマを使用して新しい一時テーブルを作成します。データを新しい一時テーブルに完全に移行すると、古いテーブルを交換して削除します。
-
INPLACE:このアルゴリズムは、元のテーブルに対して適切な操作を実行し、可能な限りテーブルのコピーと再構築を回避します。
-
インスタント:このアルゴリズムはMySQL 8.0以降に導入されましたが、まだ制限があります。
MySQL 8.0では、アルゴリズムINSTANTが導入され、列を追加するためのテーブルを即座にインプレースで変更し、忙しい本番環境での応答性と可用性を向上させた同時DMLを可能にしました。これにより、通常はアプリケーションの観点から大きな問題であったレプリカの大きなラグやストールを回避できます。これにより、ラグが原因でスレーブの読み取りがまだ更新されていないため、古いデータが取得されます。
これは有望な改善ですが、それでも制限があり、これらのINSTANTおよびINPLACEアルゴリズムを適用できない場合があります。たとえば、INSTANTおよびINPLACEアルゴリズムの場合、列のデータ型の変更も通常のDBAタスクであり、特にデータ変更によるアプリケーション開発の観点ではそうです。これらの機会は避けられません。したがって、COPYアルゴリズムを続行することはできません。これは、テーブルをロックし、スレーブで遅延を引き起こすためです。また、影響を受けるテーブルを参照する着信トランザクションを積み上げるため、この実行中にプライマリ/マスターサーバーにも影響を与えます。ビジー状態のサーバーで直接ALTERまたはスキーマ変更を実行することはできません。これは、ダウンタイムを伴うか、忍耐力を失うと、特にターゲットテーブルが巨大な場合に、データベースが破損する可能性があるためです。
実行中の本番セットアップでスキーマ変更を実行することは、常に困難な作業であることは事実です。頻繁に使用される回避策は、最初にスキーマの変更をスレーブノードに適用することです。これはステートメントベースのレプリケーションでは正常に機能しますが、行ベースのレプリケーションではある程度までしか機能しません。行ベースのレプリケーションでは、テーブルの最後に追加の列を存在させることができるため、最初の列を書き込むことができる限り、問題はありません。まず、変更をすべてのスレーブに適用し、次にスレーブの1つにフェイルオーバーしてから、変更をマスターに適用し、それをスレーブとしてアタッチします。変更に中央への列の挿入または列の削除が含まれる場合、これは行ベースのレプリケーションで機能します。
pt-oscを使用してジャンプする場合、このツールは新しいテーブル構造でシャドウテーブルを作成し、トリガーを介して新しいデータを挿入し、バックグラウンドでデータを埋め戻します。新しいテーブルの作成が完了すると、トランザクション内で古いテーブルを新しいテーブルに交換するだけです。これはすべての場合に機能するわけではありません。特に、既存のテーブルにすでにトリガーがある場合はそうです。
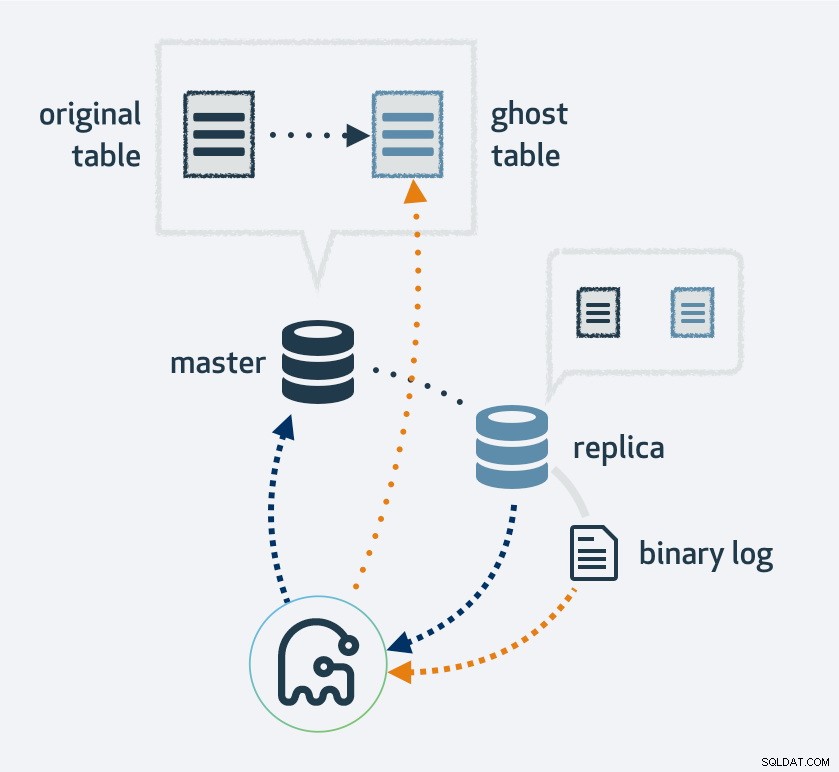
gh-ostを使用すると、最初に既存のテーブルレイアウトのコピーが作成されます。テーブルを新しいレイアウトに変更してから、プロセスをMySQLレプリカとして接続します。レプリケーションストリームを使用して、元のテーブルに挿入された新しい行を検索すると同時に、テーブルを埋め戻します。埋め戻しが完了すると、元のテーブルと新しいテーブルが切り替わります。当然、新しいテーブルに対するすべての操作は、最終的にレプリケーションストリームになります。したがって、各レプリカで、移行は同時に行われます。
DDLの問題に取り組んでいますが、一般的な問題はメモリテーブルの作成です。メモリテーブルは非永続テーブルであり、テーブル構造は残りますが、MySQLの再起動後にデータが失われます。マスターとスレーブの両方で新しいメモリテーブルを作成すると、空のテーブルが作成され、完全に正常に機能します。いずれかが再起動されると、テーブルが空になり、レプリケーションエラーが発生します。
スレーブノードのデータが異なる結果を返すと行ベースのレプリケーションが中断し、既存のデータを挿入しようとするとステートメントベースのレプリケーションが中断します。メモリテーブルの場合、これは頻繁なレプリケーションブレーカーです。修正は簡単です。データの新しいコピーを作成し、エンジンをInnoDBに変更すると、複製が安全になります。
read_only ={True | 1}
の設定もちろん、これはリングトポロジを使用している場合に考えられるケースであり、可能であればリングトポロジの使用はお勧めしません。スレーブノードに同じデータがないと、レプリケーションが中断する可能性があることを前述しました。多くの場合、これは、マスターノードではなくスレーブノードのデータを変更する何か(または誰か)によって引き起こされます。マスターノードのデータが変更されると、これはスレーブに複製され、そこで変更を適用できなくなります。これにより、複製が中断されます。これは、特にスレーブが昇格した場合、またはクラッシュのためにフェイルオーバーした場合に、クラスターレベルでのデータ破損につながる可能性もあります。それは災害になる可能性があります。
これを簡単に防ぐには、read_onlyとsuper_read_only(> 5.6のみ)がONまたは1に設定されていることを確認します。これら2つの変数の違いと、無効または有効にした場合の影響を理解しているかもしれません。彼ら。 super_read_only(MySQL 5.7.8以降)を無効にすると、rootユーザーはターゲットまたはレプリカの変更を防ぐことができます。したがって、両方を無効にすると、レプリケーションを除いて、誰もがデータに変更を加えることができなくなります。 ClusterControlなどのほとんどのフェールオーバーマネージャーは、このフラグを自動的に設定して、フェールオーバー中にユーザーが使用済みマスターに書き込めないようにします。それらのいくつかは、フェイルオーバー後もこれを保持します。
GTIDの有効化
MySQLレプリケーションでは、バイナリログの正しい位置からスレーブを起動することが不可欠です。この位置の取得は、バックアップを作成するとき(xtrabackupとmysqldumpがこれをサポートしている)、またはコピーを作成しているノードでスレーブを停止したときに実行できます。 CHANGE MASTER TOコマンドを使用してレプリケーションを開始すると、次のようになります。
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;間違った場所でレプリケーションを開始すると、悲惨な結果を招く可能性があります。データが二重に書き込まれたり、更新されなかったりする可能性があります。これにより、マスターノードとスレーブノード間でデータドリフトが発生します。
また、マスターをスレーブにフェイルオーバーするには、正しい位置を見つけて、マスターを適切なホストに変更する必要があります。 MySQLは、マスターからのバイナリログと位置を保持しませんが、代わりに独自のバイナリログと位置を作成します。これは、スレーブノードを新しいマスターに再調整する場合に深刻な問題になる可能性があります。フェイルオーバー時のマスターの正確な位置を新しいマスターで見つける必要があります。そうすれば、すべてのスレーブを再調整できます。
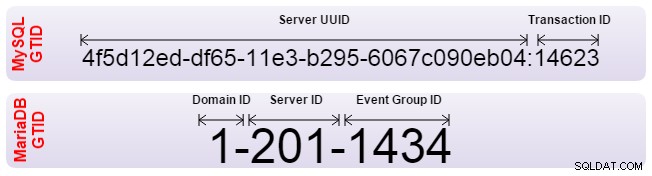
Oracle MySQLとMariaDBの両方がグローバルトランザクション識別子(GTID)を実装しましたこの問題を解決します。 GTIDを使用すると、スレーブの自動調整が可能になり、サーバーはそれ自体で正しい位置を把握します。ただし、どちらもGTIDの実装が異なるため、互換性がありません。ある場所から別の場所へのレプリケーションを設定する必要がある場合は、従来のバイナリログポジショニングを使用してレプリケーションを設定する必要があります。また、フェイルオーバーソフトウェアはGTIDを使用しないことを認識しておく必要があります。
クラッシュセーフとは、スレーブのMySQL / OSがクラッシュした場合でも、MySQLデータベースをスレーブに復元せずに、スレーブを回復してレプリケーションを続行できることを意味します。クラッシュセーフなスレーブを機能させるには、InnoDBストレージエンジンのみを使用する必要があります。5.6では、relay_log_info_repository=TABLEおよびrelay_log_recovery=1を設定する必要があります。
実践は確かに完璧ですが、これらの重要な技術に関する適切なトレーニングと知識がなければ、面倒なことや災害につながる可能性があります。これらの慣行は、MySQLの専門家によって一般的に順守されており、本番データベースサーバーでMySQLレプリケーションを管理する際の日常業務の一部として大規模な業界で採用されています。
MySQLレプリケーションについて詳しく知りたい場合は、MySQLレプリケーションに関するこのチュートリアルで高可用性を確認してください。
データベース管理ソリューションの最新情報とオープンソースベースのデータベースのベストプラクティスについては、TwitterとLinkedInでフォローし、ニュースレターを購読してください。