GTIDがMySQL5.6で導入されて以来、ハイブリッドレプリケーション、つまり同じセットアップでGaleraと非同期MySQLレプリケーションを組み合わせることがはるかに簡単になりました。スタンドアロンのMySQLサーバーからGaleraClusterに複製するのはかなり簡単でしたが、その逆(Galera→スタンドアロンのMySQL)を行うのは少し困難でした。少なくともGTIDが到着するまで。
非同期スレーブをGaleraクラスターに接続する理由はいくつかあります。 1つは、Galeraノードで長時間実行されるレポート/ OLAPタイプのクエリは、レポートの負荷が非常に高く、ノードがそれに対処するためにかなりの労力を費やす必要がある場合、クラスター全体の速度を低下させる可能性があります。そのため、レポートクエリをスタンドアロンサーバーに送信して、Galeraをレポートの負荷から効果的に分離できます。ベルトとサスペンダーのアプローチでは、非同期スレーブはリモートライブバックアップとしても機能します。
このブログ投稿では、GaleraクラスターをGTIDを使用してMySQLサーバーにレプリケートする方法と、マスターノードに障害が発生した場合にレプリケーションをフェイルオーバーする方法を示します。
MySQL5.5でのハイブリッドレプリケーション
MySQL 5.5では、壊れたレプリケーションを再開するには、最後のバイナリログファイルと位置を特定する必要があります。これらは、バイナリログが有効になっている場合、すべてのGaleraノードで異なります。この状況は、次の図で説明できます。
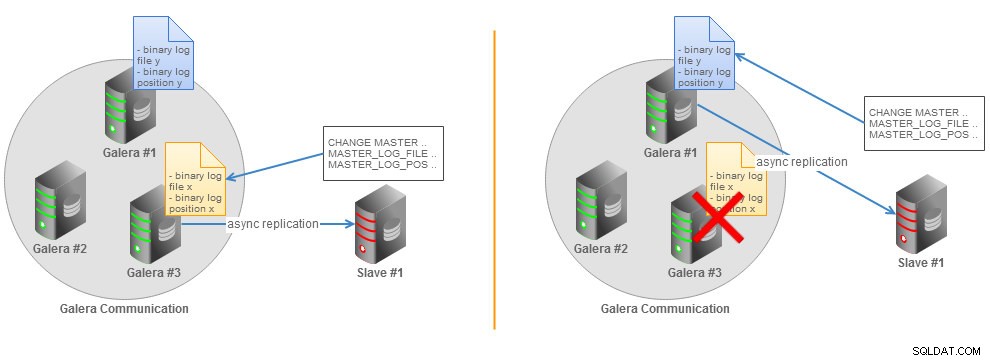 GTIDを使用しないGaleraクラスター非同期スレーブトポロジ
GTIDを使用しないGaleraクラスター非同期スレーブトポロジ MySQLマスターに障害が発生すると、レプリケーションが中断し、スレーブは別のマスターに切り替える必要があります。新しいGaleraノードを選択し、新しいバイナリログファイルとスレーブによって実行された最後のトランザクションの位置を手動で決定する必要があります。もう1つのオプションは、新しいマスターノードからデータをダンプし、スレーブで復元して、新しいマスターノードでレプリケーションを開始することです。これらのオプションはもちろん実行可能ですが、本番環境ではあまり実用的ではありません。
GTIDが問題を解決する方法
GTID(Global Transaction Identifier)は、ノード間でより優れたトランザクションマッピングを提供し、MySQL5.6でサポートされています。 Galera Clusterでは、すべてのノードが異なるbinlogファイルを生成します。 binlogイベントは同じで同じ順序ですが、binlogファイル名とオフセットは異なる場合があります。 GTIDを使用すると、スレーブは複数のマスターからの一意のトランザクションを確認できます。これは、レプリケーションを再開または再開する必要がある場合に、スレーブ実行リストに簡単にマッピングできます。
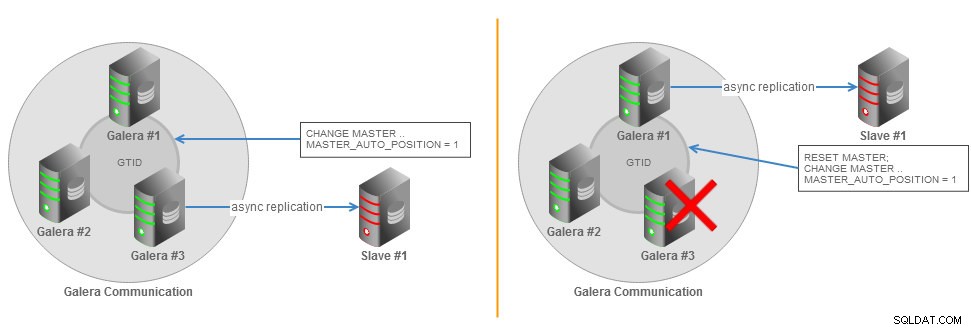 GTIDフェイルオーバーを使用したGaleraクラスター非同期スレーブトポロジ
GTIDフェイルオーバーを使用したGaleraクラスター非同期スレーブトポロジ マスターと同期するために必要なすべての情報は、レプリケーションストリームから直接取得されます。これは、複製にGTIDを使用している場合、CHANGEMASTERTOステートメントにMASTER_LOG_FILEまたはMASTER_LOG_POSオプションを含める必要がないことを意味します。代わりに、MASTER_AUTO_POSITIONオプションを有効にするだけで済みます。 GTIDの詳細については、MySQLのドキュメントページをご覧ください。
手動によるハイブリッドレプリケーションの設定
このセットアップを続行する前に、Galeraノード(マスター)とスレーブがMySQL5.6で実行されていることを確認してください。 Galeraにsbtestというデータベースがあり、これをスレーブノードに複製します。
1.各DBノードのmy.cnf(スレーブノードを含む)内で次の行を指定して、必要なレプリケーションオプションを有効にします。
マスター(ガレラ)ノードの場合:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=1 # 1 for master1, 2 for master2, 3 for master3
binlog_format=ROWスレーブノードの場合:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=101 # 101 for slave
binlog_format=ROW
replicate_do_db=sbtest
slave_net_timeout=602. Galeraクラスターのクラスターローリングリスタートを実行します(ClusterControlUI>管理>アップグレード>ローリングリスタートから)。これにより、各ノードに新しい構成が再ロードされ、GTIDが有効になります。スレーブも再起動します。
3.スレーブレプリケーションユーザーを作成し、Galeraノードの1つで次のステートメントを実行します。
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepassword';4.スレーブにログインし、Galeraノードの1つからデータベースsbtestをダンプします。
$ mysqldump -uroot -p -h192.168.0.201 --single-transaction --skip-add-locks --triggers --routines --events sbtest > sbtest.sql5.ダンプファイルをスレーブサーバーに復元します。
$ mysql -uroot -p < sbtest.sql6.スレーブノードでレプリケーションを開始します:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.201', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;レプリケーションが正しく実行されていることを確認するには、スレーブステータスの出力を調べます。
mysql> SHOW SLAVE STATUS\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...ClusterControlを使用したハイブリッドレプリケーションの設定
前の段落では、バイナリログを有効にし、ノードごとにクラスターを再起動し、データをコピーしてからレプリケーションをセットアップするために必要なすべての手順について説明しました。手順は面倒な作業であり、これらの手順の1つで簡単にエラーを起こす可能性があります。 ClusterControlでは、必要なすべての手順を自動化しました。
1. ClusterControlユーザーの場合、[ノード]ページのノードに移動して、バイナリロギングを有効にすることができます。
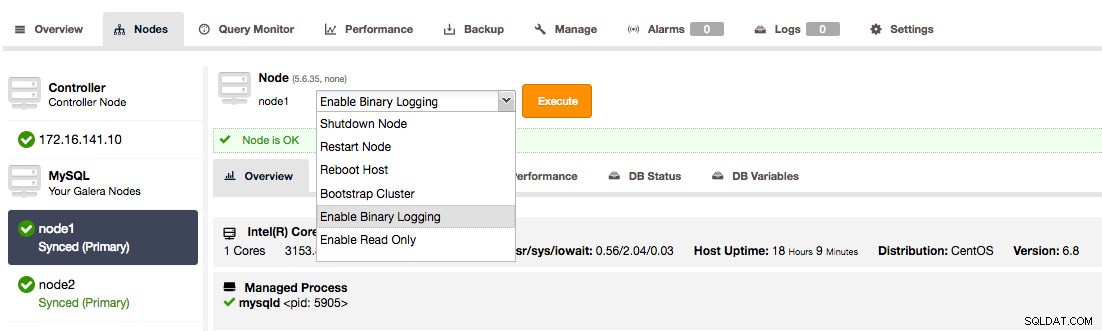 ClusterControlを使用してGaleraクラスターでバイナリロギングを有効にする
ClusterControlを使用してGaleraクラスターでバイナリロギングを有効にする これにより、バイナリログの有効期限を設定し、GTIDを有効にして、自動再起動できるダイアログが開きます。
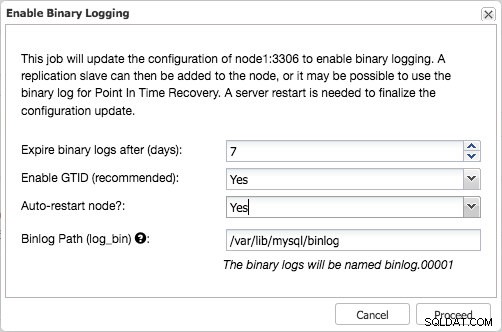 GTIDを有効にしてバイナリロギングを有効にする
GTIDを有効にしてバイナリロギングを有効にする これによりジョブが開始され、これらの変更が構成に安全に書き込まれ、適切な権限を持つレプリケーションユーザーが作成され、ノードが安全に再起動されます。
 写真の説明
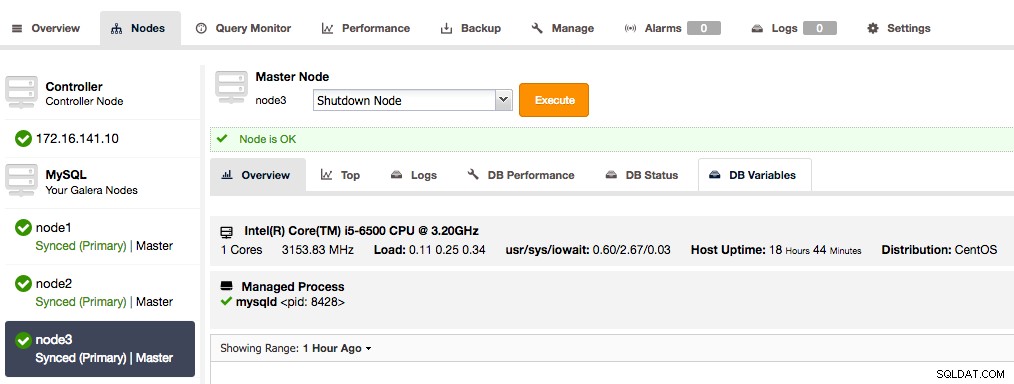
写真の説明 すべてのノードがマスターであることを示すまで、クラスター内のガレラノードごとにこのプロセスを繰り返します。
 すべてのGaleraクラスターノードがマスターになりました
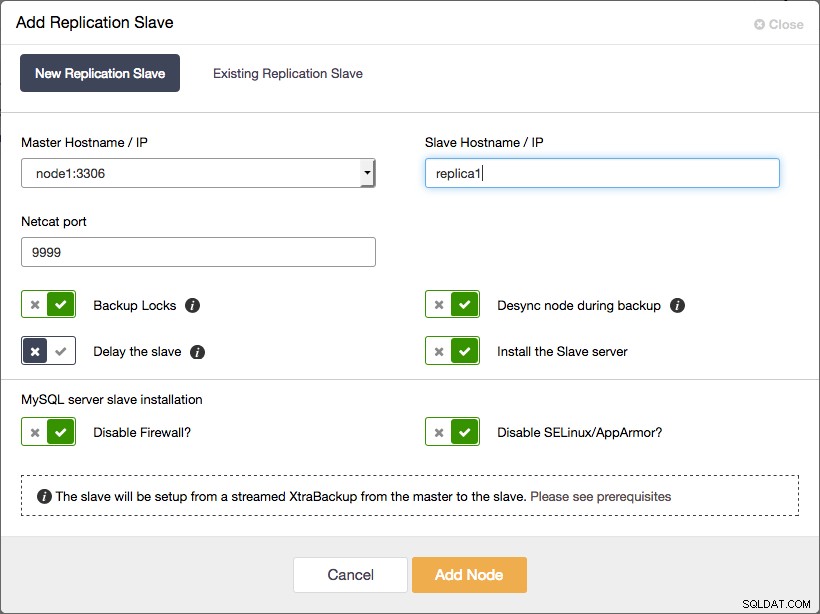
すべてのGaleraクラスターノードがマスターになりました 2.非同期レプリケーションスレーブをクラスターに追加します
 ClusterControlを使用して非同期レプリケーションスレーブをGaleraクラスターに追加する
ClusterControlを使用して非同期レプリケーションスレーブをGaleraクラスターに追加する そして、これがあなたがしなければならないすべてです。前の段落で説明したプロセス全体は、ClusterControlによって自動化されています。
マスターの変更
指定されたマスターがダウンした場合、スレーブはslave_net_timeout値で再接続を再試行します(セットアップは60秒-デフォルトは1時間です)。スレーブステータスに次のエラーが表示されるはずです:
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 1GTIDが有効になっているGaleraを使用しているため、クラスターとノードの自動リカバリの場合、マスターフェイルオーバーはClusterControlを介してサポートされます。 有効になっています。ネットワーク接続またはその他の理由でマスターがフェイルオーバーするかどうかにかかわらず、ClusterControlはクラスター内の最も適切な他のマスターノードに自動的にフェイルオーバーします。
フェイルオーバーを手動で実行する場合は、マスターノードを次のように変更するだけです。
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;場合によっては、マスターノードが変更された後に「キーの重複エントリ..」エラーが発生することがあります:
Last_Errno: 1062
Last_Error: Could not execute Write_rows event on table sbtest.sbtest; Duplicate entry '1089775' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.000009, end_log_pos 85789000古いバージョンのMySQLでは、 SET GLOBAL SQL_SLAVE_SKIP_COUNTER =nを使用できます。 ステートメントをスキップしますが、GTIDでは機能しません。 PerconaのMiguelは、空のトランザクションを挿入してこれを修復する方法について、すばらしいブログ投稿を書きました。
小規模なデータベースの場合の別のアプローチは、使用可能なGaleraノードのいずれかから新しいダンプを取得して復元し、RESETMASTERステートメントを使用することです。
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> DROP SCHEMA sbtest; CREATE SCHEMA sbtest; USE sbtest;
mysql> SOURCE /root/sbtest_from_galera2.sql; -- repeat step #4 above to get this dump
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;pt-table-checksumを使用して、レプリケーションの整合性を確認することもできます。詳細については、このブログ投稿を参照してください。
注:MySQLレプリケーションでは、スレーブアプライヤーはデフォルトでシングルスレッドのままであるため、非同期レプリケーションのパフォーマンスがGaleraの並列レプリケーションと同じであるとは期待しないでください。 MySQL 5.6および5.7の場合、スレーブノードで非同期レプリケーションを並列に実行するオプションがありますが、原則として、このレプリケーションは、同じスキーマ内で発生するトランザクションの正しい順序に依存します。レプリケーションの負荷が集中的で継続的である場合、スレーブラグは増大し続けます。スレーブがマスターに追いつくことができない場合があります。