高可用性の構築、一度に1ステップ
データベースインフラストラクチャに関しては、私たち全員がそれを望んでいます。私たちは皆、可用性の高いセットアップを構築するよう努めています。冗長性が鍵です。最下位レベルで冗長性の実装を開始し、スタックを継続します。それはハードウェアから始まります-冗長電源、冗長冷却、ホットスワップディスク。ネットワーク層-複数のNICが結合され、冗長ルーターを使用しているさまざまなスイッチに接続されています。ストレージには、RAIDに設定されたディスクを使用します。これにより、パフォーマンスが向上するだけでなく、冗長性も提供されます。次に、ソフトウェアレベルで、クラスタリングテクノロジーを使用します。複数のデータベースノードが連携して冗長性を実装します:MySQLクラスター、Galeraクラスター。
単一のデータセンターにすべてがある場合、これはすべて適切ではありません。データセンターがダウンしたり、サービスの一部(ただし重要なサービス)がオフラインになったり、データセンターへの接続が失われた場合でも、サービスがダウンします-下位レベルの冗長性の量に関係なく。そして、はい、それらのことが起こります。
- 2017年2月、S3サービスの中断によりUS-East-1地域で大混乱が発生しました
- 2011年4月の米国東部地域でのEC2およびRDSサービスの中断
- 2011年8月、EU-West地域でEC2、EBS、RDSが中断されました
- 停電により、2009年6月にRackspaceTexasDCがダウンしました
- UPSの障害により、2010年1月にRackspaceLondonDCで数百台のサーバーがオフラインになりました
これは失敗の完全なリストではなく、Googleですばやく検索した結果にすぎません。これらは、すべての卵を同じバスケットに入れた場合に問題が発生する可能性があり、問題が発生する可能性がある例として役立ちます。もう1つの例は、ハリケーンサンディです。これにより、米国東部から米国西部のDCに大量のデータが流出しました。当時、誰もが期待してインフラストラクチャを他の海岸に移動するために急いでいたため、米国西部のインスタンスをスピンアップすることはほとんどできませんでした。ノースバージニアDCは天候の影響を大きく受けます。
したがって、高可用性環境を構築する場合は、マルチデータセンターのセットアップが必須です。このブログ投稿では、Galera Cluster for MySQL/MariaDBを使用してこのようなインフラストラクチャを構築する方法について説明します。
ガレラのコンセプト
特定のソリューションを検討する前に、可用性の高いマルチDCガレラセットアップで非常に重要な2つの概念について説明します。
クォーラム
高可用性にはリソースが必要です。つまり、高可用性を実現するには、クラスター内に多数のノードが必要です。クラスターは、そのメンバーの一部の損失を許容できますが、ある程度までしか許容できません。特定の失敗率を超えると、スプリットブレインシナリオを見ている可能性があります。
2ノードのセットアップの例を見てみましょう。一方のノードがダウンした場合、もう一方のノードは、ピアがクラッシュし、ネットワーク障害ではないことをどのようにして知ることができますか?その場合、他のノードも稼働していて、トラフィックを処理している可能性があります。このような場合を処理する良い方法はありません…これが、フォールトトレランスが通常3つのノードから始まる理由です。 Galeraは、クォーラム計算を使用して、クラスターがトラフィックを安全に処理できるかどうか、またはクラスターが操作を停止する必要があるかどうかを判断します。障害が発生すると、残りのすべてのノードが相互に接続を試み、稼働中のノードの数を判別します。次に、クラスタの以前の状態と比較され、ノードの50%以上が稼働している限り、クラスタは動作を継続できます。
これにより、次のようになります。
2ノードクラスター-フォールトトレランスなし
3ノードクラスター-最大1回のクラッシュ
4ノードクラスター-最大1回のクラッシュ(2つのノードがクラッシュする場合、50%のみクラスターの一部が使用可能になる場合、存続するには50%以上のノードが必要です)
5ノードクラスター-最大2回のクラッシュ
6ノードクラスター-最大2回のクラッシュ
おそらく、クラスターに奇数のノードを持たせたいというパターンが見られます。高可用性の観点から、クラスター内の5ノードから6ノードに移動しても意味がありません。より優れたフォールトトレランスが必要な場合は、7ノードを選択する必要があります。
セグメント
通常、Galeraクラスターでは、すべての通信はすべてからすべてのパターンに従います。各ノードは、クラスター内の他のすべてのノードと通信します。
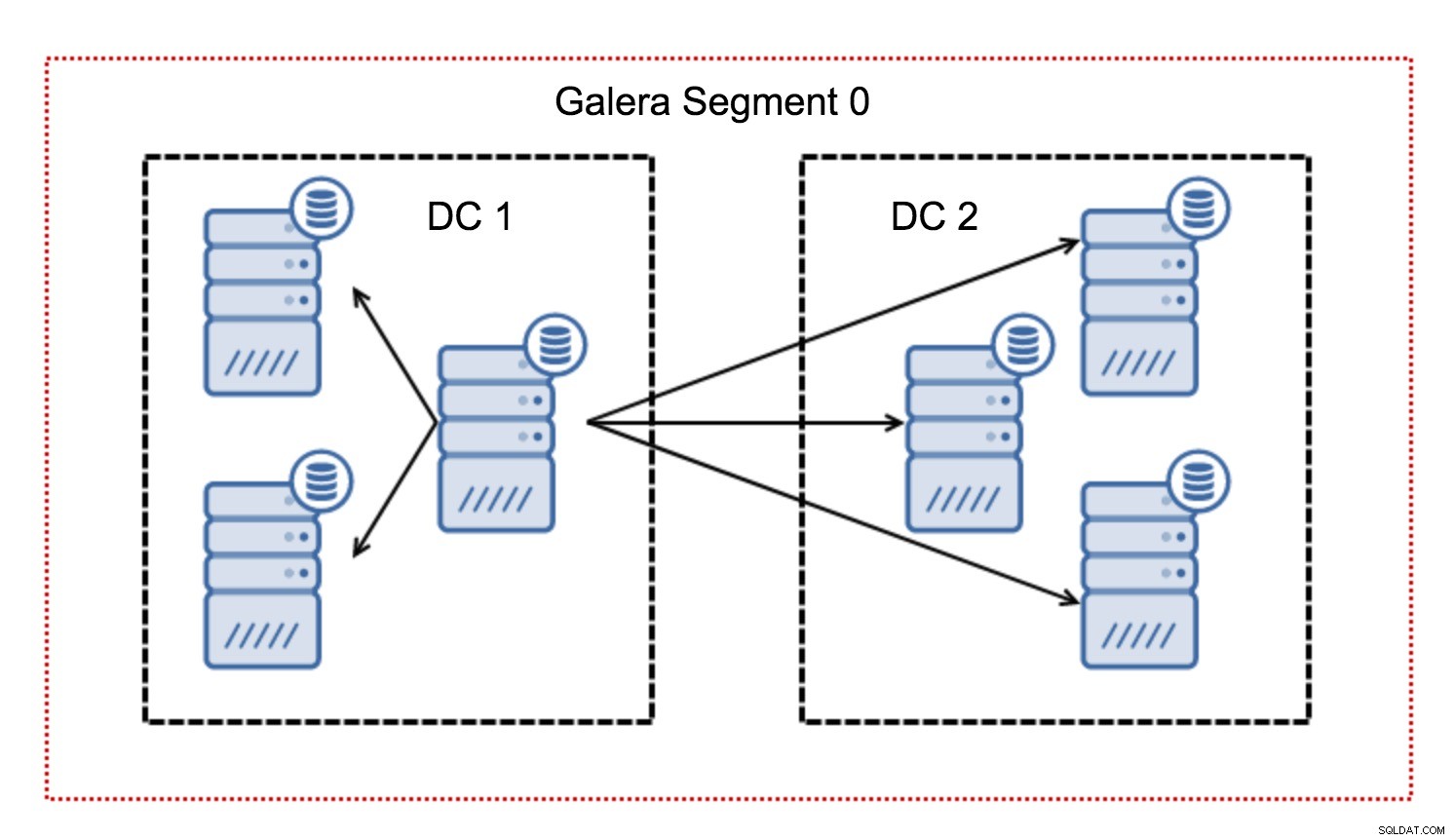
ご存知かもしれませんが、Galeraの各書き込みセットは、クラスター内のすべてのノードによって認証される必要があります。したがって、ノードで発生したすべての書き込みは、クラスター内のすべてのノードに転送される必要があります。これは、低遅延環境で問題なく機能します。ただし、マルチDCセットアップについて話している場合は、ローカルネットワークよりもはるかに高い遅延を考慮する必要があります。ワイドエリアネットワークにまたがるクラスターでより耐えられるようにするために、Galeraはセグメントを導入しました。
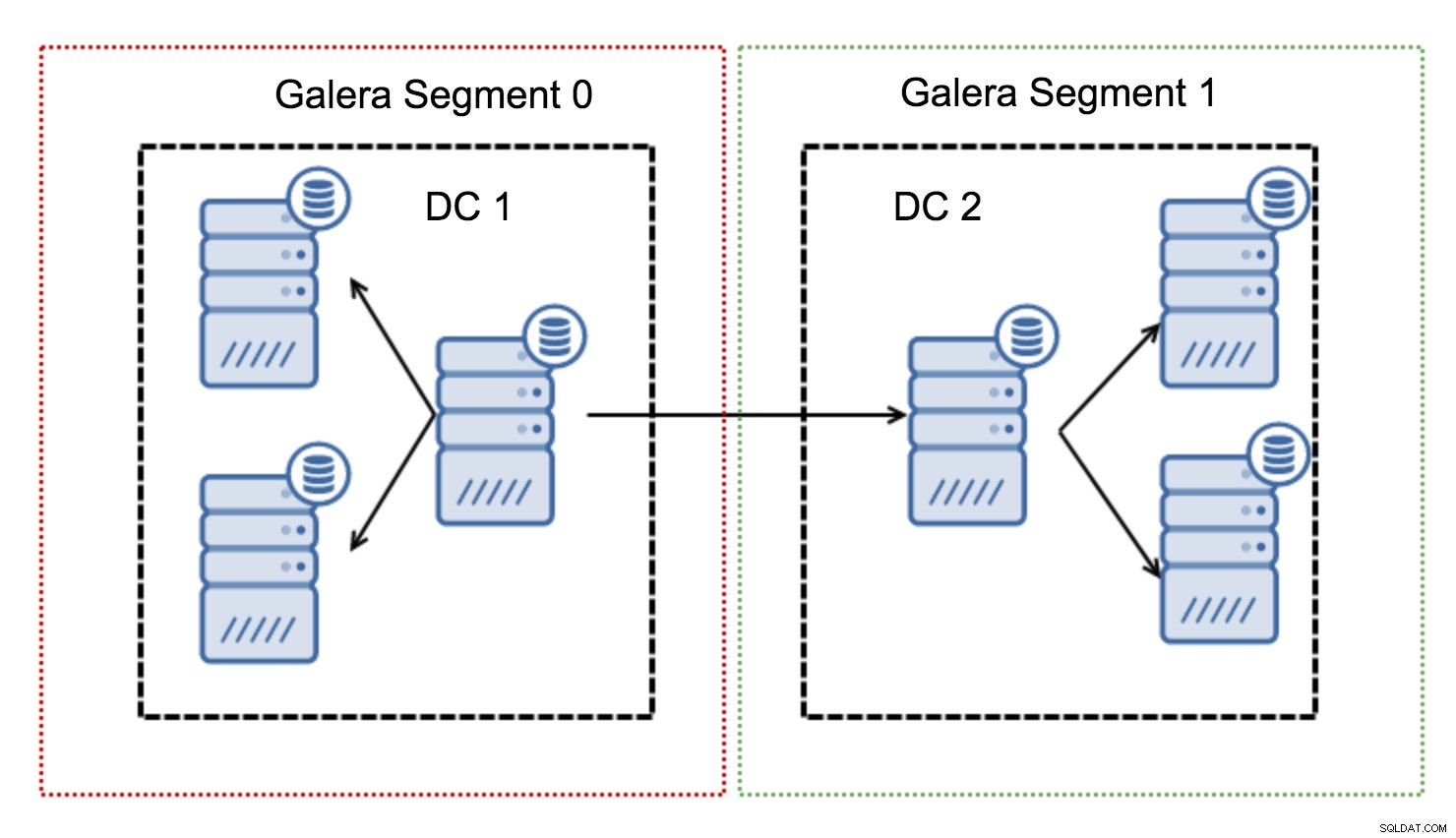
これらは、ノードのグループ(セグメント)内にGaleraトラフィックを含めることによって機能します。単一のセグメント内のすべてのノードは、ローカルネットワーク内にあるかのように機能します。つまり、1対すべての通信を想定しています。クロスセグメントトラフィックの場合、状況は異なります。各セグメントで1つの「リレー」ノードが選択され、すべてのクロスセグメントトラフィックがそれらのノードを通過します。リレーノードがダウンすると、別のノードが選出されます。これによって遅延が大幅に減少することはありません。結局のところ、1つのリモートホストまたは複数のリモートホストに接続しても、WANの遅延は同じままですが、WANリンクの帯域幅が制限される傾向があり、転送されるデータの量に対して課金します。このようなアプローチでは、セグメント間で交換されるデータの量を制限できます。もう1つの時間とコストを節約するオプションは、ドナーが必要なときに同じセグメント内のノードが優先されるという事実です。これも、WANを介して転送されるデータの量を制限し、ほとんどの場合、ローカルネットワークとしてSSTを高速化します。 WANリンクよりも高速になります。
これらの概念のいくつかが邪魔になったので、GaleraクラスターのマルチDCセットアップの他の重要な側面を見てみましょう。
直面しようとしている問題
WANにまたがる環境で作業する場合、環境を設計する際に考慮する必要のある問題がいくつかあります。
クォーラム計算
前のセクションでは、Galeraクラスターでのクォーラム計算がどのように見えるかを説明しました。つまり、存続可能性を最大化するためにノードの数を奇数にする必要があります。それはすべてマルチDCセットアップでも当てはまりますが、さらにいくつかの要素がミックスに追加されます。まず、Galeraでデータセンターの障害を自動的に処理するかどうかを決定する必要があります。これにより、使用するデータセンターの数が決まります。 2つのDCを想像してみましょう。ノードを50%から50%に分割し、1つのデータセンターがダウンした場合、2つ目のDCには「プライマリ」状態を維持するための50%+1ノードがありません。ノードを不均等に分割し、それらの大部分を「メイン」データセンターで使用している場合、そのデータセンターがダウンしたときに、「バックアップ」DCにはクォーラムを形成するための50%+1ノードがありません。ノードに異なる重みを割り当てることはできますが、結果はまったく同じになります。手動で介入しなければ、2つのDC間で自動的にフェイルオーバーする方法はありません。自動フェイルオーバーを実装するには、3つ以上のDCが必要です。繰り返しになりますが、理想的には奇数です。3つのデータセンターは完全に優れたセットアップです。次に、問題は、ノードがいくつ必要かということです。それらをデータセンター全体に均等に分散させる必要があります。残りは、セットアップで処理する必要のある障害が発生したノードの数だけです。
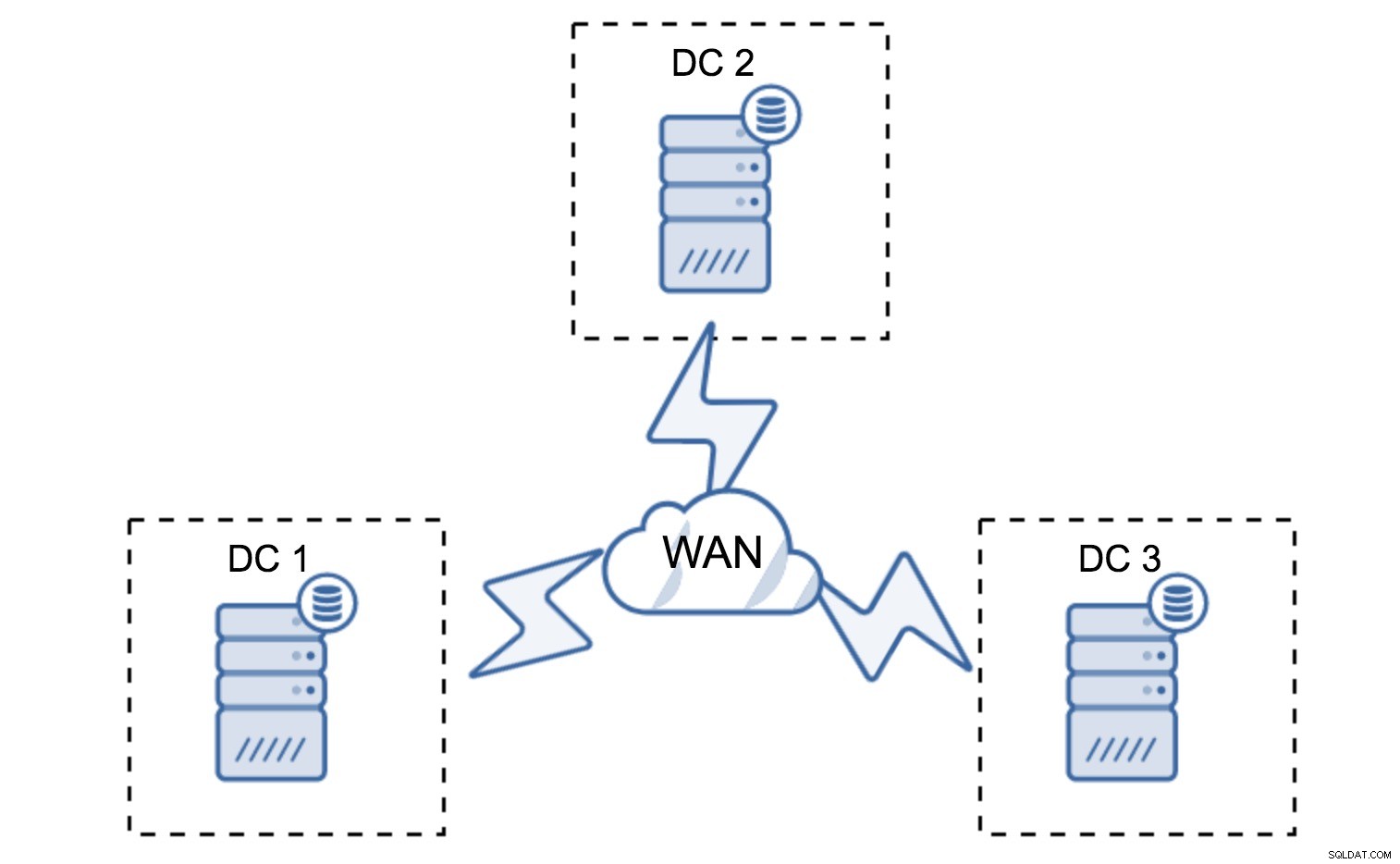
最小限のセットアップでは、データセンターごとに1つのノードが使用されますが、重大な欠点があります。すべての状態転送では、WANを介してデータを移動する必要があり、その結果、SSTを完了するために必要な時間が長くなるか、コストが高くなります。
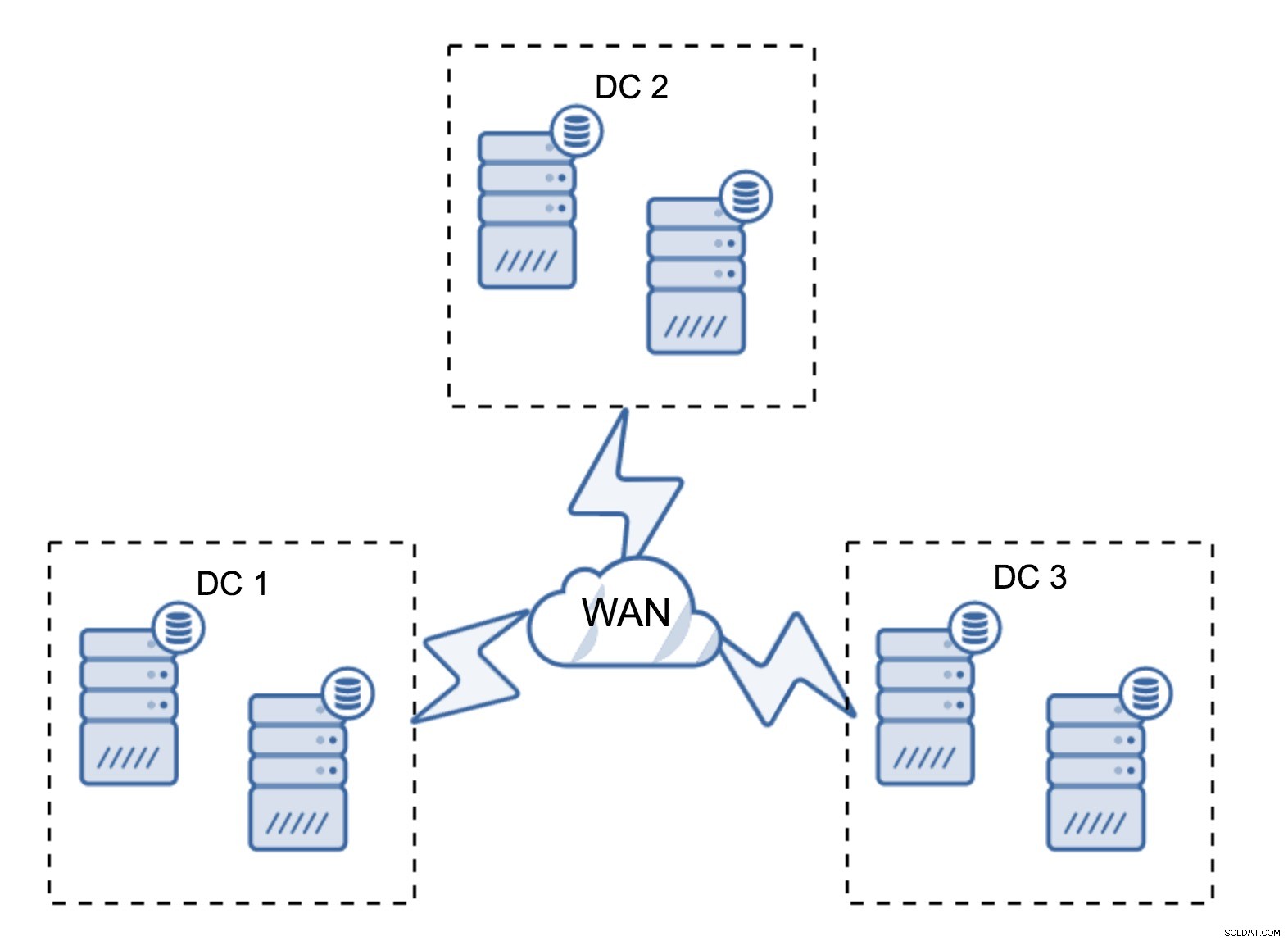
非常に一般的なセットアップは、データセンターごとに2つ、合計6つのノードを持つことです。この設定は、ノードの数が偶数であるため、予期しないように見えます。ただし、考えてみると、それほど大きな問題ではない可能性があります。3つのノードが同時にダウンする可能性はほとんどなく、このような設定では、最大2つのノードのクラッシュに耐えることができます。データセンター全体がオフラインになり、残りの2つのDCが運用を継続する可能性があります。また、最小限の設定に比べて大きな利点があります。ノードがオフラインになると、データセンターには常にドナーとして機能できる2番目のノードがあります。ほとんどの場合、WANはSSTには使用されません。
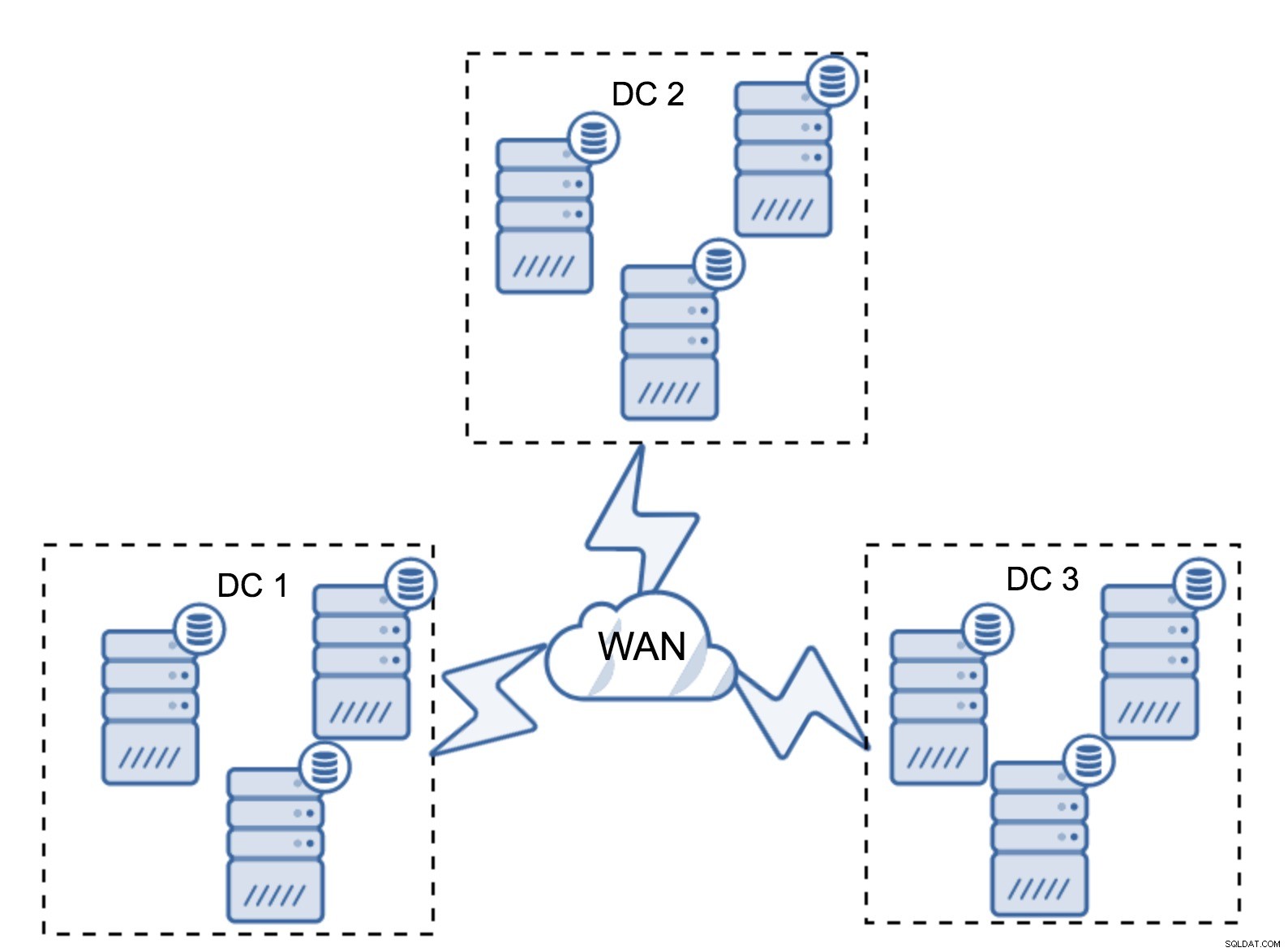
もちろん、ノードの数をクラスターごとに3つ、合計で9つに増やすことができます。これにより、さらに優れた存続可能性が得られます。最大4つのノードがクラッシュしても、クラスターは存続します。一方、セグメントを使用する場合でも、ノードが多いほど操作のオーバーヘッドが高くなり、Galeraクラスターをある程度までスケールアウトできることに注意する必要があります。
たとえば、アプリケーションが2つしかないため、3つ目のデータセンターが必要ない場合があります。もちろん、3つのデータセンターの要件は引き続き有効であるため、回避することはできませんが、完全にロードされたデータベースサーバーの代わりにGalera Arbitrator(garbd)を使用することはまったく問題ありません。
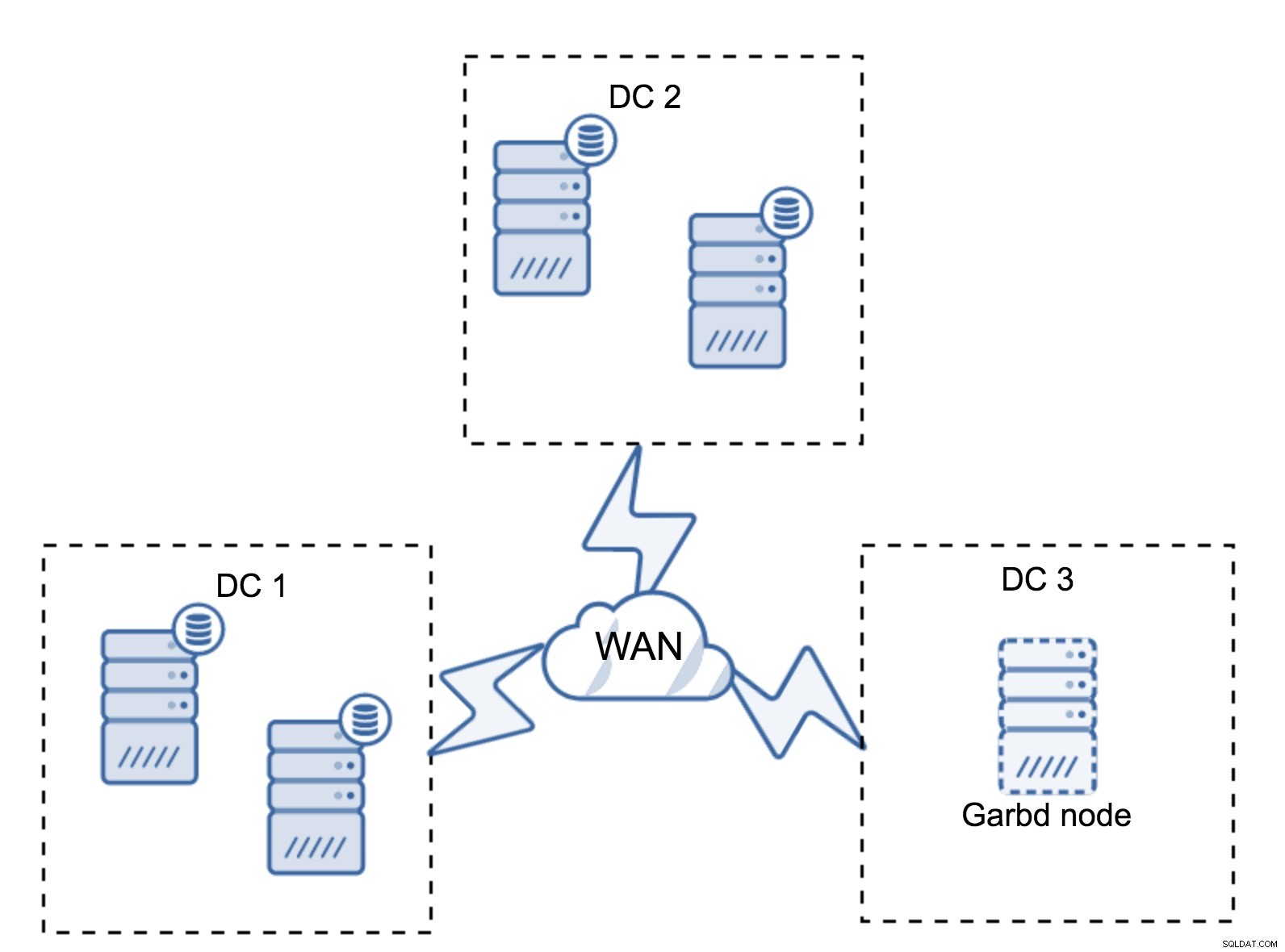
Garbdは、仮想サーバーであっても、より小さなノードにインストールできます。強力なハードウェアを必要とせず、データを保存したり、書き込みセットを適用したりすることもありません。ただし、すべてのレプリケーショントラフィックを確認し、クォーラムの計算に参加します。そのおかげで、4つのノードのようなセットアップを展開できます。3番目のノードではDC + garbdごとに2つです。合計で5つのノードがあり、そのようなクラスターは最大2つの障害を受け入れることができます。つまり、データセンターの1つの完全なシャットダウンを受け入れることができるということです。
どのオプションがあなたに適していますか?すべての場合に最適なソリューションはありません。それはすべて、インフラストラクチャの要件によって異なります。幸いなことに、さまざまなオプションから選択できます。多かれ少なかれノード、完全な3DCまたは2DC、3番目のノードのgarbdです。自分に適したものが見つかる可能性が非常に高いです。
ネットワーク遅延
マルチDCセットアップを使用する場合、ネットワーク遅延はローカルネットワーク環境から予想されるものよりも大幅に高くなることに注意する必要があります。これにより、GaleraクラスターをスタンドアロンのMySQLインスタンスまたはMySQLレプリケーションセットアップと比較すると、パフォーマンスが大幅に低下する可能性があります。すべてのノードが書き込みセットを認証する必要があるという要件は、どれだけ離れていても、すべてのノードが書き込みセットを受信する必要があることを意味します。非同期レプリケーションでは、コミットする前に待つ必要はありません。もちろん、レプリケーションには他の問題と欠点がありますが、レイテンシーは主要なものではありません。この問題は、データベースにホットスポット(頻繁に更新される行(カウンター、キューなど))がある場合に特に顕著になります。これらの行は、ネットワークラウンドトリップごとに1回以上更新することはできません。世界中にまたがるクラスターの場合、これは簡単に、1つの行を1秒間に2〜3回以上更新できないことを意味します。これが制限になる場合は、Galeraクラスターが特定のワークロードに適していないことを意味している可能性があります。
マルチDCガレラクラスターのプロキシレイヤー
複数のデータセンターにまたがるGaleraクラスタを用意するだけでは不十分ですが、それらにアクセスするにはアプリケーションが必要です。データベース層の複雑さをアプリケーションから隠すための一般的な方法の1つは、プロキシを利用することです。プロキシはデータベースへのエントリポイントとして使用され、データベースノードの状態を追跡し、常に使用可能なノードのみにトラフィックを転送する必要があります。このセクションでは、マルチDCガレラクラスターに使用できるプロキシレイヤーの設計を提案します。 ProxySQLを使用します。これにより、データベースノードの処理にかなりの柔軟性が得られますが、Galeraノードの状態を追跡できる限り、別のプロキシを使用できます。
プロキシの場所はどこですか?
つまり、ここには2つの一般的なパターンがあります。ProxySQLを別のノードにデプロイするか、アプリケーションホストにデプロイすることができます。これらの各設定の長所と短所を見てみましょう。
個別のホストセットとしてのプロキシレイヤー
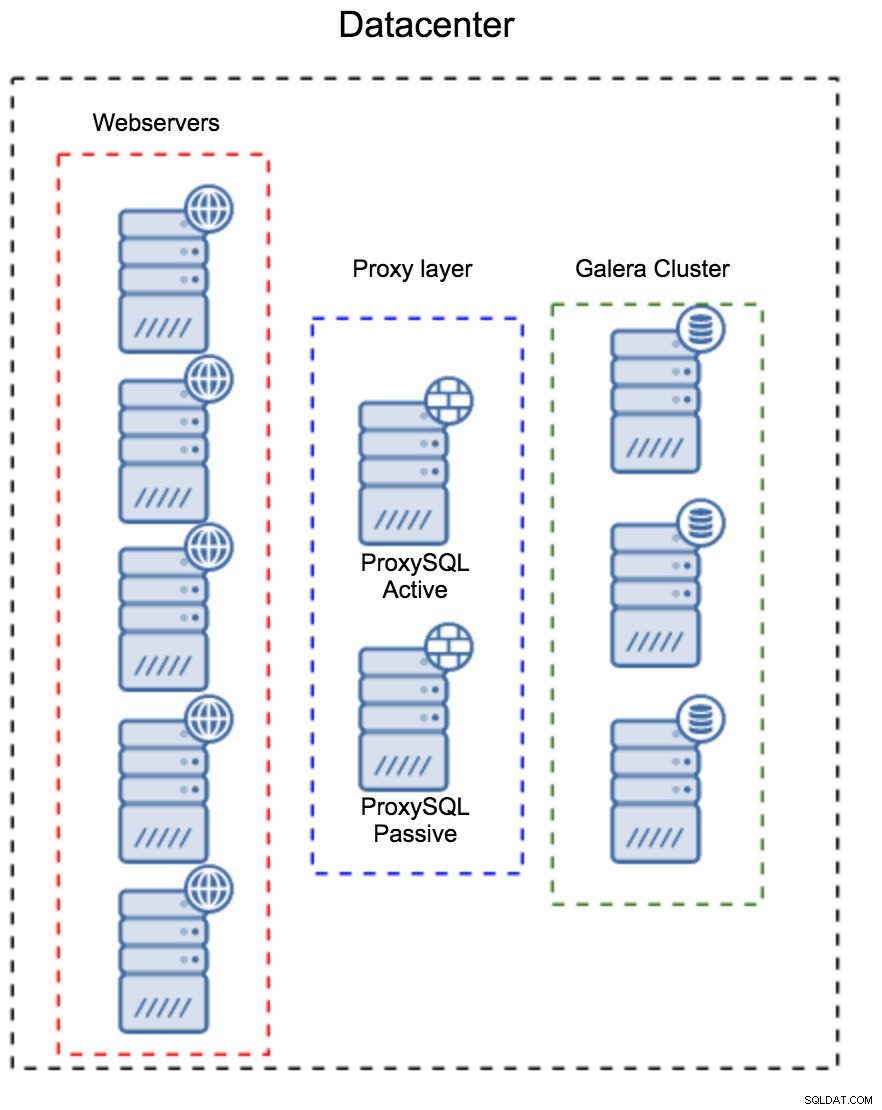
最初のパターンは、個別の専用ホストを使用してプロキシレイヤーを構築することです。 ProxySQLをいくつかのホストにデプロイし、仮想IPとキープアライブを使用して高可用性を維持できます。アプリケーションはVIPを使用してデータベースに接続し、VIPは、要求が常に使用可能なProxySQLにルーティングされるようにします。この設定の主な問題は、最大で1つのProxySQLインスタンスを使用することです。すべてのスタンバイノードがトラフィックのルーティングに使用されるわけではありません。これにより、通常使用するよりも強力なハードウェアを使用せざるを得なくなる場合があります。一方、セットアップの保守は簡単です。すべてのProxySQLノードに構成の変更を適用する必要がありますが、それらはほんの一握りです。 ClusterControlのオプションを利用してノードを同期することもできます。このような設定は、使用するすべてのデータセンターで複製する必要があります。
アプリケーションインスタンスにインストールされたプロキシ
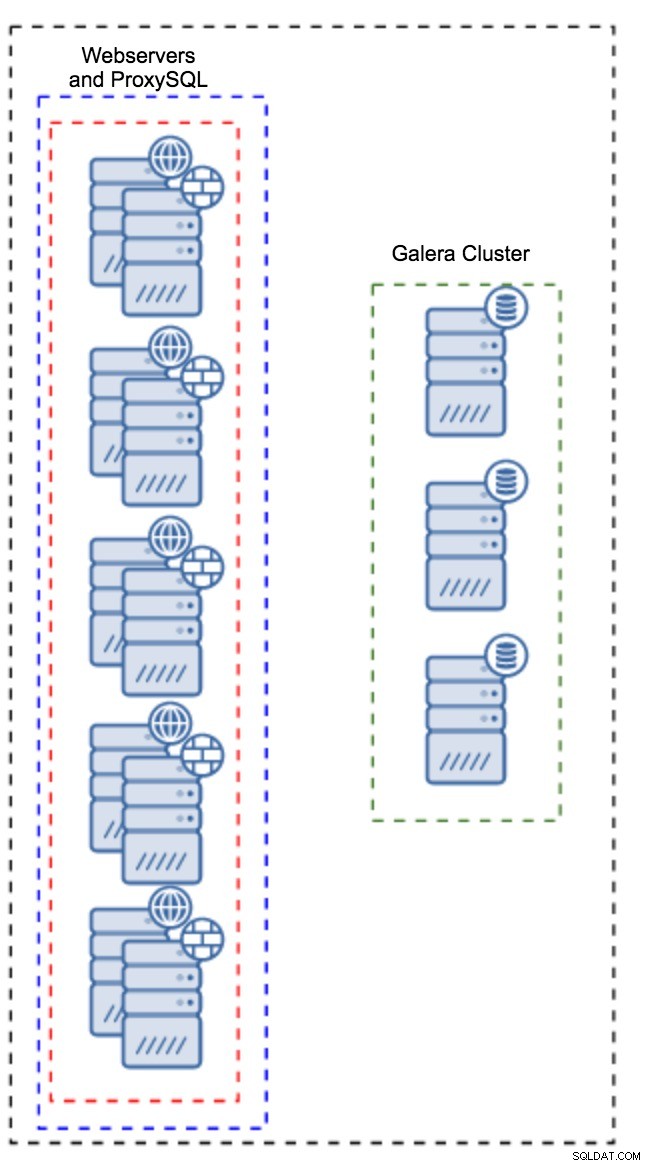
別のホストセットを用意する代わりに、ProxySQLをアプリケーションホストにインストールすることもできます。アプリケーションはローカルホスト上のProxySQLに直接接続し、UNIXソケットを使用してTCP接続のオーバーヘッドを最小限に抑えることもできます。このような設定の主な利点は、多数のProxySQLインスタンスがあり、負荷がそれらに均等に分散されることです。 1つがダウンした場合、そのアプリケーションホストのみが影響を受けます。残りのノードは引き続き機能します。直面する最も深刻な問題は、構成管理です。多数のProxySQLノードがある場合、それらの構成の同期を維持する自動化された方法を考え出すことが重要です。 ClusterControl、またはPuppetなどの構成管理ツールを使用できます。
WAN環境でのガレラの調整
Galeraのデフォルトはローカルネットワーク用に設計されており、WAN環境で使用する場合は、ある程度の調整が必要です。できる基本的な調整のいくつかについて説明しましょう。正確な調整には本番データとトラフィックが必要であることに注意してください。変更を加えて適切であると想定することはできません。適切なベンチマークを実行する必要があります。
オペレーティングシステムの構成
オペレーティングシステムの構成から始めましょう。ここで提案されているすべての変更がWAN関連であるとは限りませんが、MySQLをインストールするための適切な開始点を思い出してください。
vm.swappiness = 1Swappinessは、オペレーティングシステムがスワップを使用する度合いを制御します。最近のカーネルでは、OSがスワップをまったく使用できなくなり、深刻なパフォーマンスの問題が発生する可能性があるため、ゼロに設定しないでください。
/sys/block/*/queue/scheduler = deadline/noopMySQLが使用するブロックデバイスのスケジューラは、deadlineまたはnoopのいずれかに設定する必要があります。正確な選択はベンチマークによって異なりますが、どちらの設定も、デフォルトのスケジューラーであるCFQよりも優れた同様のパフォーマンスを提供するはずです。
MySQLの場合、カーネルに応じてEXT4またはXFSの使用を検討する必要があります(これらのファイルシステムのパフォーマンスは、カーネルバージョンごとに異なります)。いくつかのベンチマークを実行して、より適切なオプションを見つけてください。
これに加えて、sysctlネットワーク設定を調べることをお勧めします。詳細については説明しませんが(ここにドキュメントがあります)、一般的な考え方は、バッファ、バックログ、タイムアウトを増やして、ストールや不安定なWANリンクに対応しやすくすることです。
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0OSの調整に加えて、Galeraネットワーク関連の設定を調整することを検討する必要があります。
evs.suspect_timeout
evs.inactive_timeoutこれらの変数のデフォルト値を変更することを検討することをお勧めします。両方のタイムアウトは、クラスターが障害のあるノードを排除する方法を制御します。すべてのノードが非アクティブなメンバーに到達できない場合、疑わしいタイムアウトが発生します。非アクティブタイムアウトは、ノードが応答しない場合にノードがクラスター内にとどまることができる期間のハード制限を定義します。通常、デフォルト値が適切に機能することがわかります。ただし、場合によっては、特にWAN経由でGaleraクラスターを実行している場合(たとえば、AWSリージョン間)、これらの変数を増やすと、パフォーマンスがより安定する可能性があります。 WANリンクが不安定なためにノードがクラスターから外れる可能性を低くするために、両方をPT1Mに設定することをお勧めします。
evs.send_window
evs.user_send_windowこれらの変数、 evs.send_window およびevs.user_send_window 、レプリケーションを介して同時に送信できるパケットの数を定義します( evs.send_window )およびそれらのうちのいくつにデータが含まれる可能性があるか( evs.user_send_window )。高遅延接続の場合、これらの値を大幅に増やす価値がある場合があります(たとえば、512または1024)。
evs.inactive_check_period上記の変数も変更される可能性があります。 evs.inactive_check_period 、デフォルトでは1秒に設定されていますが、これはWAN設定には多すぎる可能性があります。 PT30Sに設定することをお勧めします。
gcs.fc_factor
gcs.fc_limitここでは、フロー制御が開始される可能性を最小限に抑えたいため、 gcs.fc_factorを設定することをお勧めします。 1に増やし、 gcs.fc_limitを増やします。 たとえば、260に。
gcs.max_packet_size遅延が大幅に大きいWANリンクを使用しているため、パケットのサイズを増やしたいと考えています。出発点としては2097152が適切です。
先に述べたように、これらのパラメータを設定する方法について簡単なレシピを提供することは事実上不可能です。これは、あまりにも多くの要因に依存するためです。事前に、本番データにできるだけ近いデータを使用して、独自のベンチマークを実行する必要があります。システムが調整されていると言えます。そうは言っても、これらの設定は、より正確なチューニングの開始点となるはずです。
今のところ以上です。 GaleraはWAN環境で非常にうまく機能するので、試してみて、どのように乗り込むかをお知らせください。