100%慣れていないデータベースで作業する必要がある場合、利用可能な数百のメトリックに圧倒される可能性があります。最も重要なものはどれですか?何を監視する必要がありますか、またその理由は何ですか?メトリックのどのパターンがいくつかの警鐘を鳴らすべきですか?このブログ投稿では、MySQLまたはMariaDBを本番環境で実行しているときに監視するための最も重要なメトリックのいくつかを紹介します。
Com_*ステータスカウンター
まず、Com_ *カウンターから始めます。これらのカウンターは、MySQLが実行するクエリの数とタイプを定義します。ここでは、SELECT、INSERT、UPDATEなどのクエリタイプについて説明しています。突然のスパイクや予期しないドロップは、システムに問題が発生したことを示唆している可能性があるため、これらを監視することは非常に重要です。
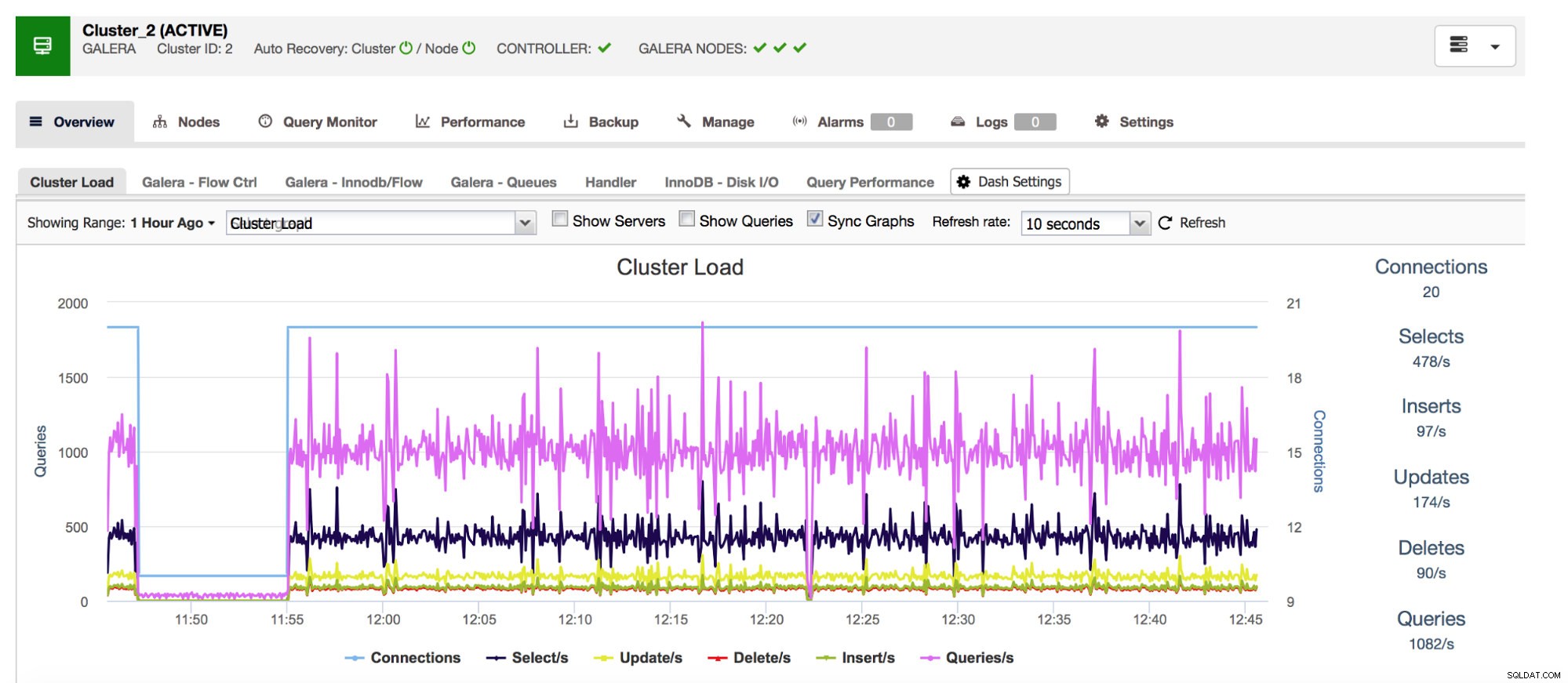
包括的なデータベース管理システムClusterControlは、「概要」セクションで最も一般的なクエリタイプに関連するこのデータを表示します。
Handler_*ステータスカウンター
注意が必要なメトリックのカテゴリは、MySQLのHandler_*カウンターです。 Com_ *カウンターは、MySQLインスタンスが実行しているクエリの種類を示しますが、あるSELECTは別のSELECTとは完全に異なる可能性があります。SELECTはプライマリキールックアップである可能性があり、インデックスを使用できない場合はテーブルスキャンでもあります。ハンドラーは、MySQLが保存されたデータにアクセスする方法を教えてくれます。これは、パフォーマンスの問題を調査し、クエリのレビューと追加のインデックス作成で利益が得られるかどうかを評価するのに非常に役立ちます。
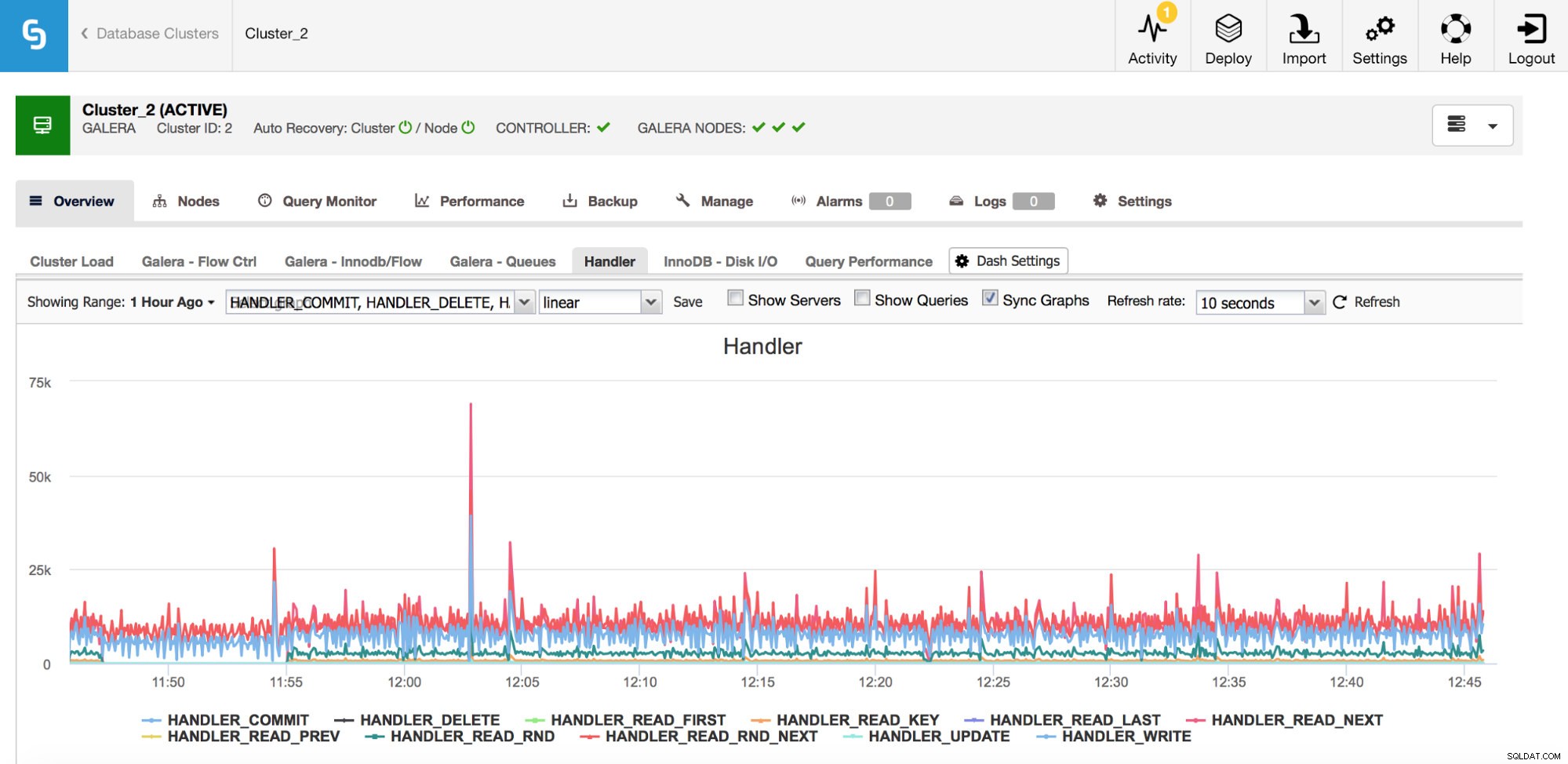
上のグラフからわかるように、追跡するメトリックはたくさんあります(そして、ClusterControlは最も重要なものをグラフ化します)-ここではそれらすべてをカバーしません(MySQLドキュメントで説明を見つけることができます)が、強調したいと思います最も重要なもの。
Handler_read_rnd_next-MySQLがインデックスルックアップなしで行にアクセスするときはいつでも、順番に、このカウンターは増加します。ワークロードでhandler_read_rnd_nextがトラフィック全体の高い割合を占める場合、MySQLは多くのテーブルスキャンを実行するため、テーブルが追加のインデックスを使用する可能性が高いことを意味します。
Handler_read_nextおよびhandler_read_prev-これらの2つのカウンターは、MySQLがインデックススキャンを実行するたびに更新されます-順方向または逆方向。 Handler_read_firstとhandler_read_lastは、それらがどのような種類のインデックススキャンであるかをさらに明らかにする可能性があります。フルインデックススキャン(順方向または逆方向)について話している場合、これら2つのカウンターが更新されます。
Handler_read_key-一方、このカウンターは、その値が高い場合、多くの行がインデックスルックアップを介してアクセスされたため、テーブルが適切にインデックス付けされていることを示します。
レプリケーションラグ
MySQLレプリケーションを使用している場合、レプリケーションラグは確実に監視する必要があるメトリックです。レプリケーションラグは避けられず、それに対処する必要がありますが、それに対処するには、なぜそれが発生するのかを理解する必要があります。そのための最初のステップは、それがいつ現れたかを知ることです。
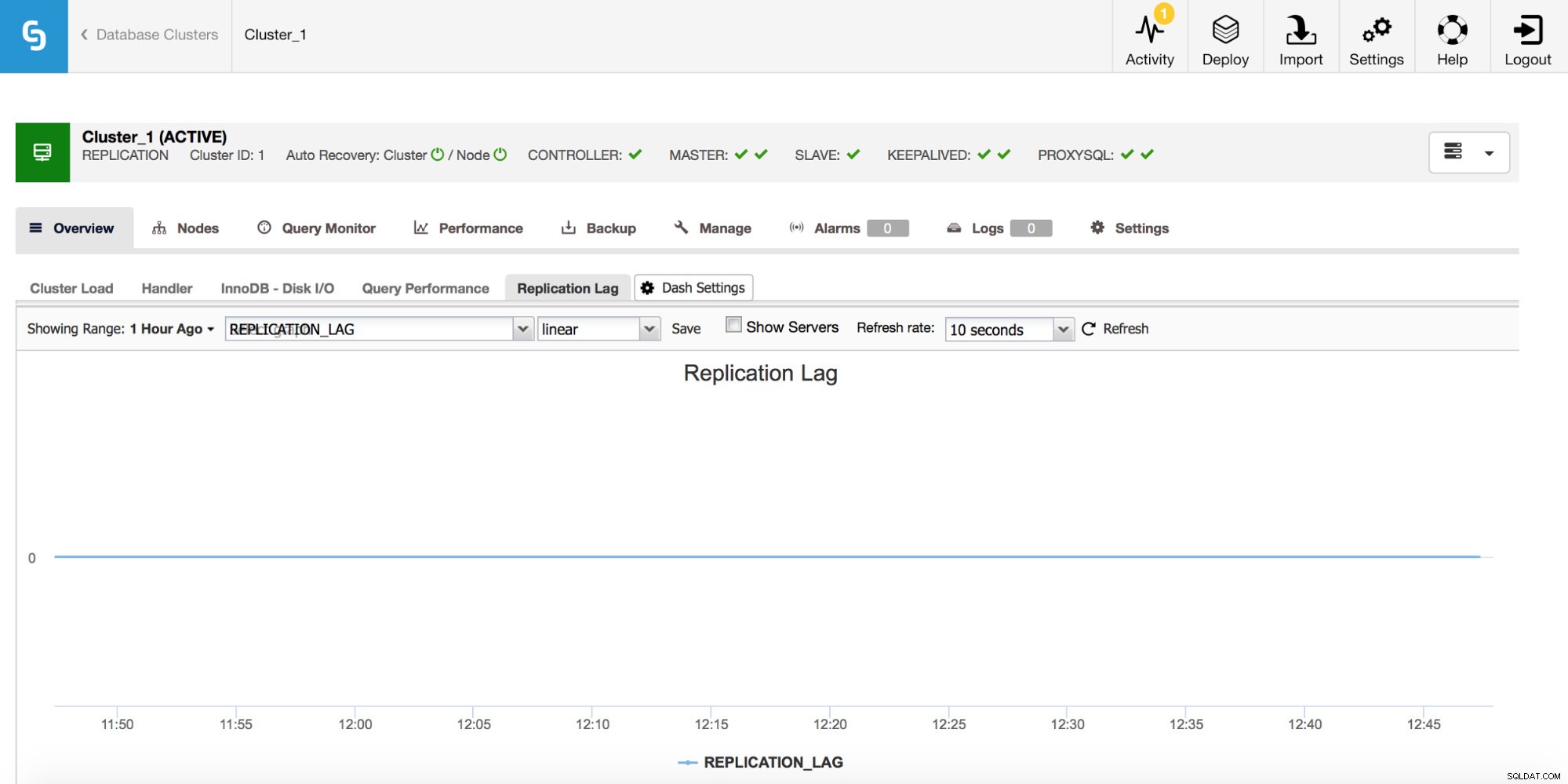
レプリケーションラグの急増が見られる場合は常に、他のグラフをチェックして、より多くの手がかりを取得する必要があります。なぜそれが発生したのでしょうか。何が原因だったのでしょうか?理由は異なる可能性があります-長くて重いDML、短期間に実行されるDMLの数の大幅な増加、CPUまたはI/Oの制限。
InnoDB I / O
I/Oに関連する指標を監視するための重要な指標がいくつかあります。
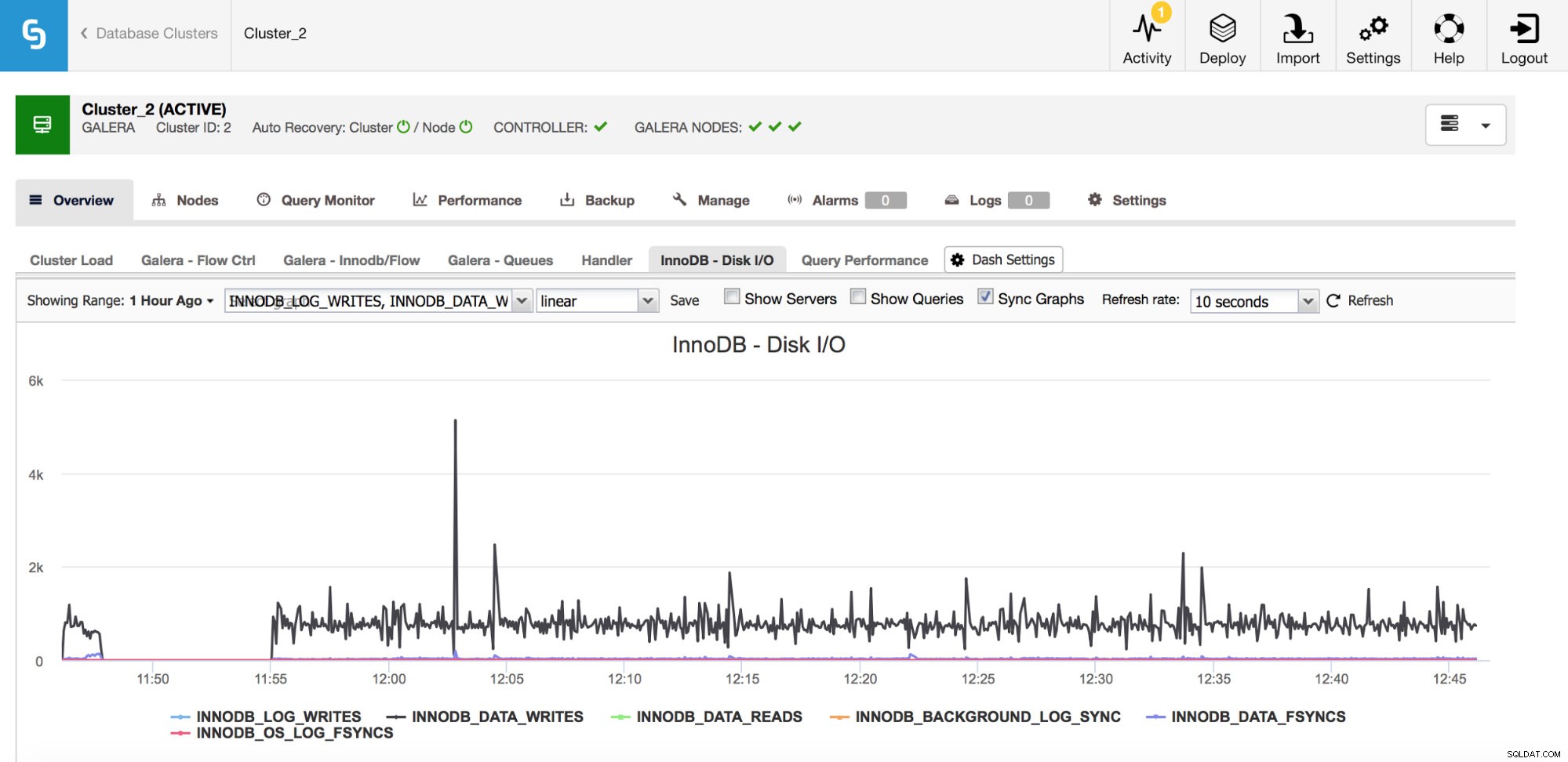
上のグラフでは、InnoDBが実行するI / Oの種類(データの書き込みと読み取り、REDOログの書き込み、fsync)を示すいくつかのメトリックを確認できます。これらのメトリックは、たとえば、レプリケーションの遅延がI / Oの急増によって引き起こされたのか、それとも他の理由によって引き起こされたのかを判断するのに役立ちます。これらのメトリックを追跡し、ハードウェアの制限と比較することも重要です。ディスクのハードウェアの制限に近づいている場合は、データベースのパフォーマンスに深刻な影響を与える前に、これを調べる必要があります。
データベース管理に関するSevereninesDevOpsガイドオープンソースデータベースを自動化および管理するために知っておくべきことを学ぶ無料でダウンロードガレラメトリクス-フロー制御とキュー
たまたまGaleraClusterを使用している場合(使用するフレーバーに関係なく)、綿密に監視したいメトリックがさらにいくつかあります。これらはある程度結びついています。まず、フロー制御に関連するメトリックです。
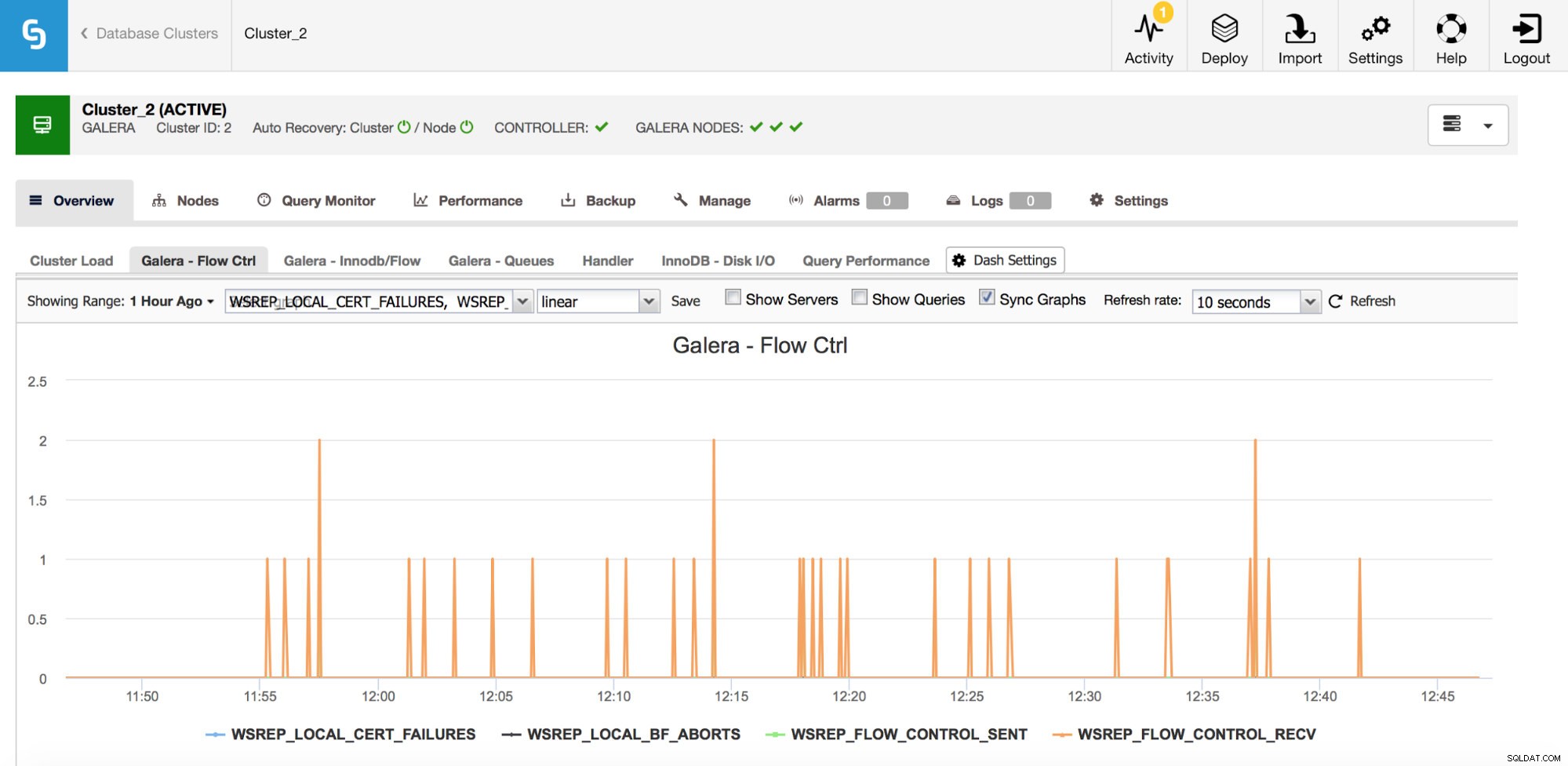
Galeraのフロー制御は、クラスターの同期を維持するための手段です。ノードが停止し、クラスターの残りの部分に追いつくことができない場合は常に、残りのクラスターノードに速度を落とすように求めるフロー制御メッセージの送信を開始します。これにより、追いつくことができます。これによりクラスターのパフォーマンスが低下するため、フロー制御メッセージの送信を開始したノードとノードを識別できることが重要です。これは、ユーザーが経験した速度低下の一部を説明したり、さらなる調査に使用する時間枠とホストを制限したりする可能性があります。
監視する2番目のメトリックのセットは、Galeraの送受信キューに関連するものです。
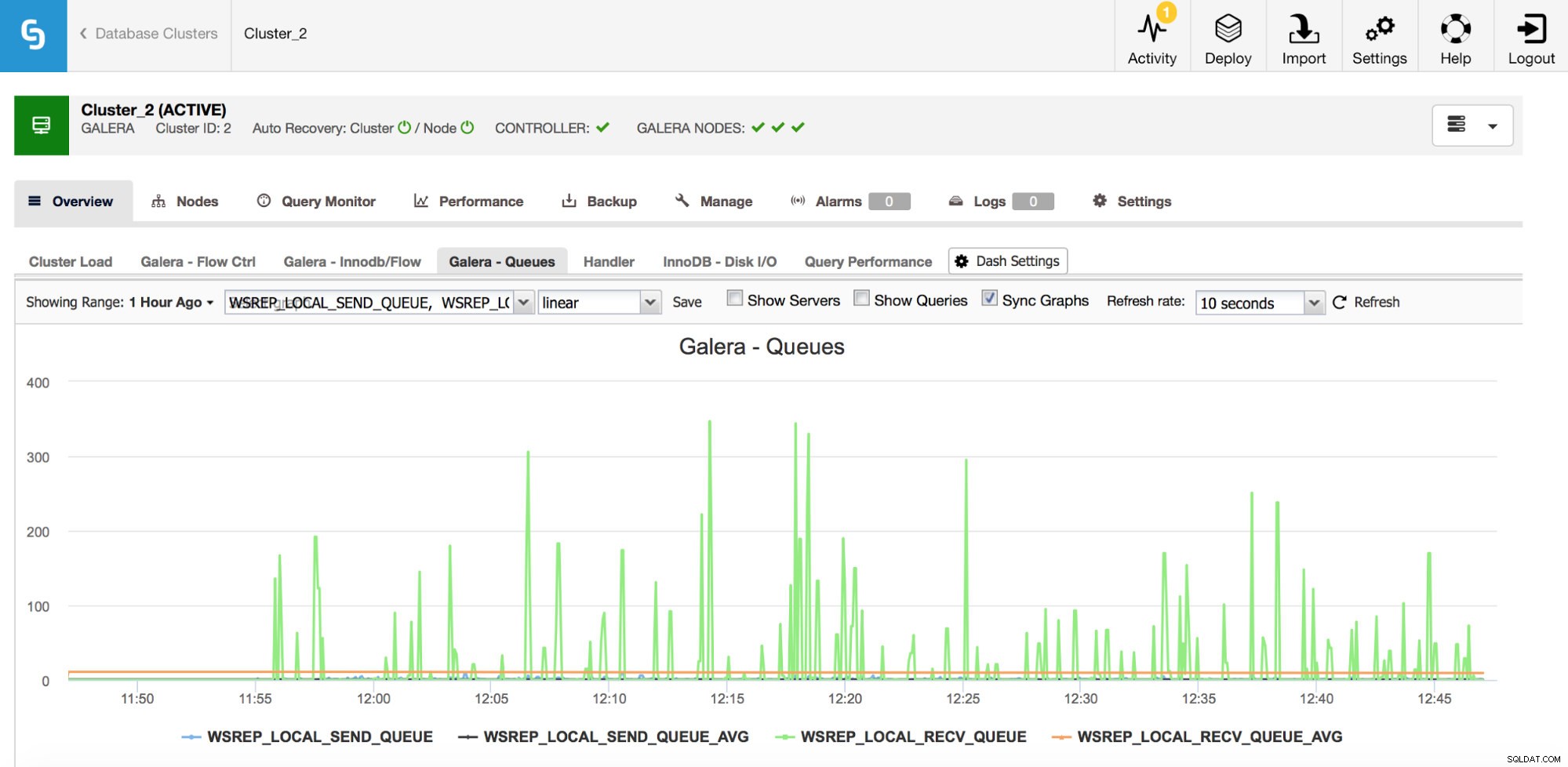
Galeraノードは、すべてをすぐに適用できない場合、ライトセット(トランザクション)をキャッシュできます。必要に応じて、他のノードに送信されようとしているライトセットをキャッシュすることもできます(特定のノードがアプリケーションから書き込みを受信した場合)。どちらの場合も速度低下の症状であり、フロー制御メッセージが送信される可能性が高く、調査が必要です。なぜ、どのノードで、いつ発生したのでしょうか。
もちろん、これは、MySQLが利用できるすべてのメトリックを検討する際の氷山の一角にすぎません。それでも、CPUなどの通常のOS /ハードウェアメトリックに加えて、ここで取り上げたメトリックを監視し始めても間違いはありません。 、メモリ、ディスク使用率、およびサービスの状態。