MySQLテーブルはどのように破損しますか?データファイルを台無しにする方法はたくさんあります。多くの場合、破損は、MySQLがデータの保存と取得に依存する基盤となるプラットフォームの欠陥(ディスクサブシステム、コントローラー、通信チャネル、ドライバー、ファームウェア、またはその他のハードウェアの障害)が原因です。 MySQLサーバーデーモンが突然再起動した場合、または他のOSコンポーネントのクラッシュが原因でサーバーが再起動した場合にも、データが破損する可能性があります。データベースインスタンスがディスクへのデータの書き込み中にあった場合、データを部分的に書き込む可能性があり、予想とは異なるページチェックサムが発生する可能性があります。 MySQLにもバグがあったため、サーバーハードウェアに問題がない場合でも、MySQL自体が破損する可能性があります。
通常、MySQLデータが破損した場合は、最後のバックアップからデータを復元するか、DRサーバーに切り替えるか、Galeraクラスターを使用して他のノードからデータをすぐに提供する場合は、影響を受けるノードを停止することをお勧めします。場合によっては、バックアップがない場合、クラスターがセットアップされていない場合、レプリケーションが非常に長い間ダウンしている場合、またはDR手順がテストされていない場合があります。バックアップがある場合でも、オンラインに戻るまでの時間が短くなる可能性があるため、回復を試みるためにいくつかのアクションを実行することをお勧めします。
MyISAM、悪くて醜い
InnoDBは、MyISAMよりもフォールトトレラントです。 InnoDBにはauto_recovery機能があり、古いMyISAMエンジンと比較してはるかに安全です。
MyISAMテーブルは、多くの書き込みが発生し、そのテーブルで多くのロックが発生すると、簡単に破損する可能性があります。ストレージエンジンは、データをファイルシステムキャッシュに「書き込み」ます。これは、データがディスクにフラッシュされるまでに時間がかかる場合があります。したがって、サーバーが突然再起動すると、キャッシュ内の不明な量のデータが失われます。これは、MyISAMデータが破損する通常の方法です。 MyISAMからInnoDBに移行することをお勧めしますが、これが不可能な場合もあります。
主要な非ノセレ、バックアップ
破損したテーブルを修復する前に、まずデータベースファイルをバックアップする必要があります。はい、すでに壊れていますが、これは、復旧操作によって引き起こされる可能性のあるさらなる損傷のリスクを最小限に抑えるためです。実行するアクションが、手付かずのデータブロックに害を及ぼさないという保証はありません。 4より大きい値でInnoDBリカバリを強制すると、データファイルが破損する可能性があるため、事前のバックアップで、理想的にはデータベースの別の物理コピーで行うようにしてください。
すべてのデータベースからすべてのファイルをバックアップするには、次の手順に従います。
MySQLサーバーを停止します
service mysqld stopdatadirに対して次のコマンドを入力します。
cp -r /var/lib/mysql /var/lib/mysql_bkpデータディレクトリのバックアップコピーができたら、トラブルシューティングを開始できます。
データ破損の特定
エラーログはあなたの親友です。通常、データの破損が発生すると、エラーログに関連情報(ドキュメントへのリンクを含む)が表示されます。それがどこにあるかわからない場合は、my.cnfと変数log_errorを確認してください。詳細については、この記事https://dev.mysql.com/doc/refman/8.0/en/error-log-destination-configurationを確認してください。 html。また、知っておくべきことは、ストレージエンジンのタイプです。この情報は、エラーログまたはinformation_schemaにあります。
mysql> select table_name,engine from information_schema.tables where table_name = '<TABLE>' and table_schema = '<DATABASE>';データ破損の問題を診断するための主なツール/コマンドは、CHECK TABLE、REPAIR TABLE、およびmyisamchkです。 mysqlcheckクライアントはテーブルのメンテナンスを実行します。MySQLの実行中にテーブルのチェック、修復(MyISAM)、最適化、または分析を行います。
mysqlcheck -uroot -p <DATABASE>DATABASEをデータベースの名前に置き換え、TABLEを確認するテーブルの名前に置き換えます。
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheckは、指定されたデータベースとテーブルをチェックします。テーブルがチェックに合格すると、mysqlcheckはテーブルに対してOKを表示します。
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKデータ破損の問題は、権限の問題にも関連している可能性があります。場合によっては、R / Wの問題が原因で、OSがマウントポイントを読み取り専用モードに切り替えることがあります。これは、ユーザーが誤ってデータファイルの所有権を変更したことが原因である可能性があります。このような場合、関連情報はエラーログに表示されます。
[example@sqldat.com employees]# ls -rtla
...
-rw-rw----. 1 mysql mysql 28311552 05-10 06:24 titles.ibd
-rw-r-----. 1 root root 109051904 05-10 07:09 salaries.ibd
drwxr-xr-x. 7 mysql mysql 4096 05-10 07:12 ..
drwx------. 2 mysql mysql 4096 05-10 07:17 .MySQLクライアント
MariaDB [employees]> select count(*) from salaries;
ERROR 1932 (42S02): Table 'employees.salaries' doesn't exist in engineエラーログエントリ
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Failed to find tablespace for table `employees`.`salaries` in the cache. Attempting to load the tablespace with space id 9
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Cannot open datafile for read-only: './employees/salaries.ibd' OS error: 81
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Operating system error number 13 in a file operation.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: The error means mysqld does not have the access rights to the directory.
2018-05-10 9:15:38 140703666226944 [ERROR] InnoDB: Could not find a valid tablespace file for `employees/salaries`. Please refer to https://dev.mysql.com/doc/refman/5.7/en/innodb-troubleshooting-datadict.html for how to resolve the issue.InnoDBテーブルの回復
データベーステーブルにInnoDBストレージエンジンを使用している場合は、InnoDBリカバリプロセスを実行できます。
自動リカバリを有効にするには、MySQLでinnodb_force_recoveryオプションを有効にする必要があります。 Innodb_force_recoveryは、バックグラウンド操作の実行を防ぎながらInnoDBを強制的に起動し、テーブルをダンプできるようにします。
これを行うには、my.cnfを開き、[mysqld]セクションに次の行を追加します。
[mysqld]
innodb_force_recovery=1
service mysql restartinnodb_force_recovery =1から開始して、変更をmy.cnfファイルに保存してから、オペレーティングシステムに適切なコマンドを使用してMySQLサーバーを再起動する必要があります。 innodb_force_recovery値が3以下のテーブルをダンプできる場合は、比較的安全です。多くの場合、4まで上げる必要がありますが、すでにご存知のとおり、データが破損する可能性があります。
[mysqld]
innodb_force_recovery=1
service mysql restart必要に応じて、より高い値に変更します。6が最大で、最も危険です。
データベースを起動できるようになったら、次のコマンドを入力して、すべてのデータベースをdatabases.sqlファイルにエクスポートします。
mysqldump --all-databases --add-drop-database --add-drop-table > dump.sqlmysqlを起動し、DROPDATABASEコマンドを使用して影響を受ける1つまたは複数のデータベースを削除してみてください。 MySQLがデータベースを削除できない場合は、MySQLサーバーを停止した後、以下の手順を使用してデータベースを手動で削除できます。
service mysqld stopデータベースを削除できなかった場合は、次のコマンドを入力してデータベースを手動で削除します。
cd /var/lib/mysql
rm -rf <DATABASE>
内部データベースディレクトリを削除しないでください。
完了したら、[mysqld]の次の行をコメントアウトして、InnoDBリカバリモードを無効にします。
#innodb_force_recovery=...my.cnfファイルへの変更を保存してから、MySQLサーバーを起動します
service mysqld start次のコマンドを入力して、手順5で作成したバックアップファイルからデータベースを復元します。
mysql> tee import_database.log
mysql> source dump.sqlMyISAMの修復
mysqlcheckがテーブルのエラーを報告した場合は、-repairフラグを指定してmysqlcheckコマンドを入力して修正します。 mysqlcheck修復オプションは、サーバーが稼働しているときに機能します。
mysqlcheck -uroot -p -r <DATABASE> <TABLE>サーバーがダウンしていて、何らかの理由でmysqlcheckがテーブルを修復できない場合でも、myisamchkを使用してファイルに対して直接リカバリを実行するオプションがあります。 myisamchkでは、サーバーでテーブルが開いていないことを確認する必要があります。
MySQLを停止します
service mysqld stop
cd /var/lib/mysqlデータベースが配置されているディレクトリに移動します。
cd /var/lib/mysql/employees
myisamchk <TABLE>データベース内のすべてのテーブルを確認するには、次のコマンドを入力します。
myisamchk *.MYI前のコマンドが機能しない場合は、myisamchkの正常な実行を妨げている可能性のある一時ファイルを削除してみてください。これを行うには、data dirディレクトリに戻り、次のコマンドを実行します。
ls */*.TMDリストされている.TMDファイルがある場合は、それらを削除します。
rm */*.TMD次に、myisamchkを再実行します。
テーブルの修復を試みるには、次のコマンドを実行し、TABLEを修復するテーブルの名前に置き換えます。
myisamchk --recover <TABLE>MySQLサーバーを再起動します
service mysqld startデータ損失を回避する方法
回復不能なデータのリスクを最小限に抑えるためにできることがいくつかあります。まず第一に、バックアップ。バックアップの問題は、見落とされることがあるということです。 cronスケジュールバックアップの場合、通常、バックアップログの問題を検出するラッパースクリプトを記述しますが、バックアップがまったく開始されなかった場合は含まれません。 cronはハングすることがあり、多くの場合、監視が設定されていません。もう1つの潜在的な問題は、バックアップが設定されていない場合です。別のツールからレポートを実行して、バックアップステータスを分析し、不足しているバックアップスケジュールについて通知することをお勧めします。そのためにClusterControlを使用することも、独自のプログラムを作成することもできます。
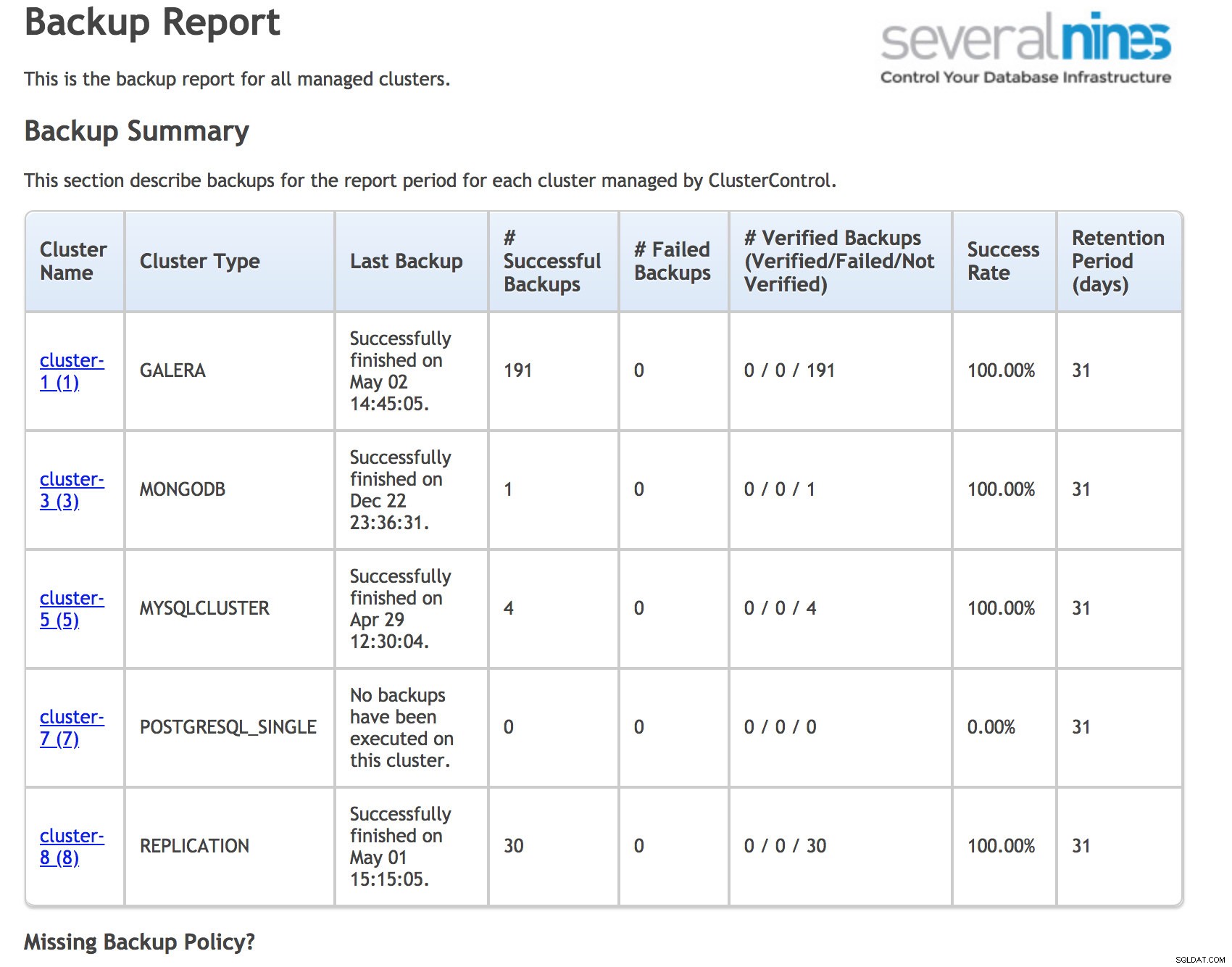 ClusterControl運用バックアップレポート
ClusterControl運用バックアップレポート 起こりうるデータ破損の影響を減らすために、常にクラスター化されたシステムを検討する必要があります。データベースがクラッシュしたり破損したりするのは時間の問題なので、切り替えることができるコピーを用意しておくとよいでしょう。マスター/スレーブレプリケーションである可能性があります。ここで重要なのは、安全な自動リカバリを使用して、スイッチオーバーの複雑さを最小限に抑え、リカバリ時間(RTO)を最小限に抑えることです。
 ClusterControl自動回復機能
ClusterControl自動回復機能