最近では、複数のクラウドにまたがるデータベースが非常に一般的です。それらは、高い可用性と、災害復旧手順を簡単に実装する可能性を約束します。また、ベンダーロックインを回避する方法でもあります。複数のクラウドプロバイダー間で動作できるようにデータベース環境を設計する場合、特定のプロバイダーに固有の機能や実装に縛られていない可能性があります。これにより、別のクラウドやオンプレミスのセットアップなど、環境に別のインフラストラクチャプロバイダーを簡単に追加できます。このような柔軟性は非常に重要です。クラウドプロバイダー間に激しい競争があり、経費削減によって裏付けられれば、相互の移行は非常に実現可能である可能性があります。
インフラストラクチャを複数のデータセンターにまたがって(同じプロバイダーからであろうとなかろうと、実際には問題ではありません)、解決すべき深刻な問題が発生します。データが安全になるようにインフラストラクチャ全体を設計するにはどうすればよいでしょうか。マルチクラウド環境で作業しているときに直面しなければならない課題にどのように対処しますか?このブログでは、1つを見ていきますが、間違いなく最も深刻なもの、つまりスプリットブレインの可能性です。どういう意味ですか?スプリットブレインとは何かを少し掘り下げてみましょう。
「スプリットブレイン」とは何ですか?
スプリットブレインは、複数のノードで構成される環境がネットワークパーティションになり、互いに接触していない複数のセグメントに分割された状態です。最も単純なケースは次のようになります:
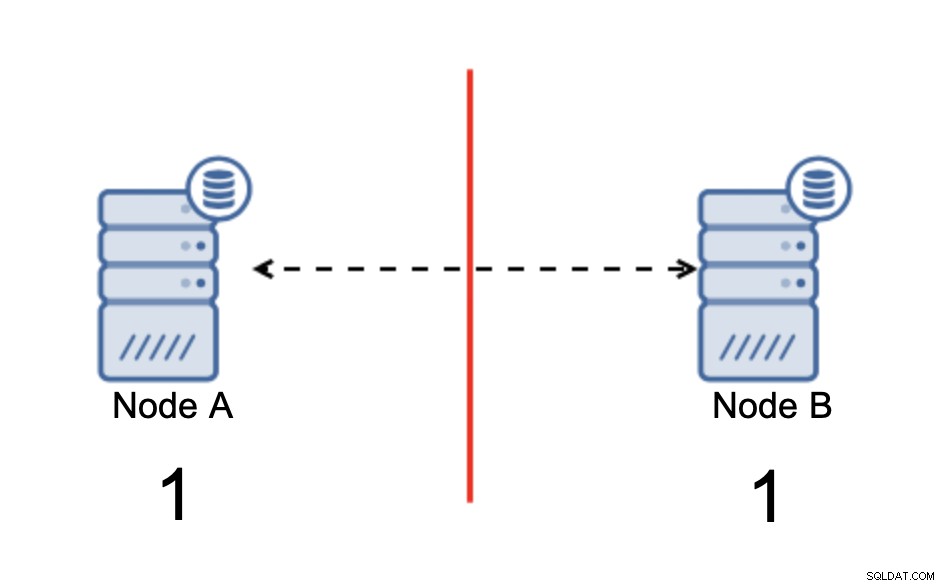
biを使用してネットワーク経由で接続された2つのノードAとBがあります-指向性非同期レプリケーション。次に、これらのノード間のネットワーク接続が切断されます。その結果、両方のノードが相互に接続できず、ノードAで実行された変更をノードBに送信できず、その逆も同様です。 AとBの両方のノードが稼働しており、接続を受け入れています。データを交換することはできません。これは深刻な問題につながる可能性があります。アプリケーションは、データベースの完全な状態を確認することを期待して両方のノードで変更を行う可能性がありますが、実際には、部分的に既知のデータ状態でのみ動作します。その結果、アプリケーションによって誤ったアクションが実行されたり、誤った結果がユーザーに表示されたりする可能性があります。スプリットブレインは潜在的に非常に危険な状態であり、優先事項の1つはある程度それに対処することであることは明らかだと思います。それについて何ができるでしょうか?
要するに、それは状況によって異なります。対処すべき主な問題は、ノードが稼働しているが、ノード間に接続がないため、他のノードの状態を認識していないという事実です。一般に、MySQL非同期レプリケーションには、スプリットブレインの問題を内部的に解決するようなメカニズムはありません。スプリットブレインを回避するのに役立ついくつかのソリューションの実装を試みることができますが、それらには制限があるか、それでも問題を完全には解決しません。
非同期レプリケーションから離れると、状況は異なって見えます。 MySQLGroupReplicationとMySQLGaleraClusterは、ビルドイットクラスター認識の恩恵を受けるテクノロジーです。これらのソリューションは両方とも、ノード間の通信を維持し、クラスターがノードの状態を認識していることを確認します。これらは、クラスターが動作可能かどうかを管理するクォーラムメカニズムを実装します。
これら2つのソリューション(非同期レプリケーションとクォーラムベースのクラスター)について詳しく説明しましょう。
MySQLGaleraClusterとMySQLGroupReplicationの実装の違いについては説明しません。クォーラムベースのアプローチの背後にある基本的な考え方と、クォーラムベースのアプローチが問題を解決するためにどのように設計されているかに焦点を当てます。クラスタ内のスプリットブレイン。
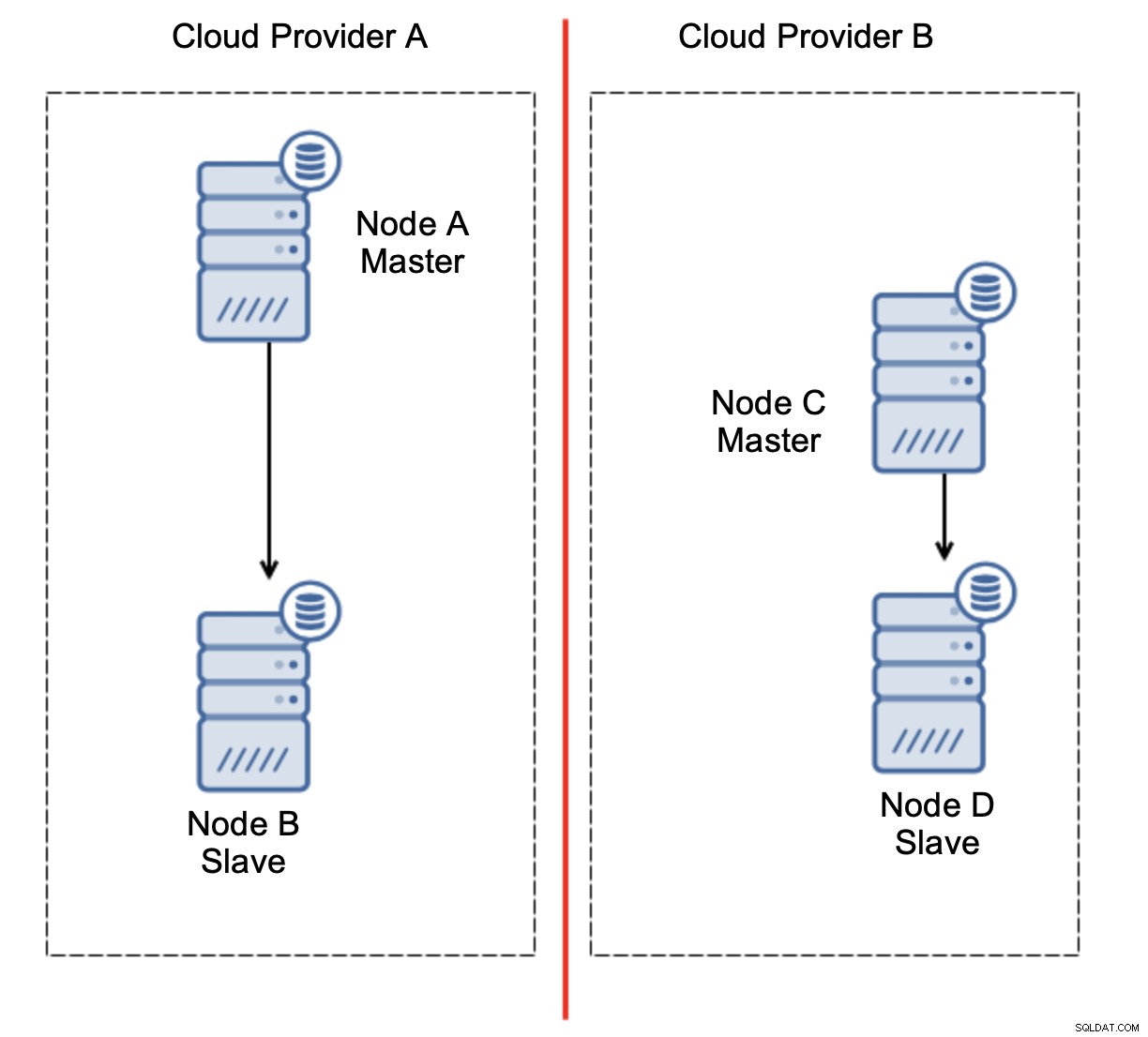
重要なのは、クラスターが動作するには、そのノードの大部分が使用可能である必要があるということです。この要件により、少数派はアクションを実行できないため、少数派がクラスターの残りの部分に実際に影響を与えることはありません。これは、1つのノードの障害を処理できるようにするには、クラスターに少なくとも3つのノードが必要であることも意味します。ノードが2つしかない場合:
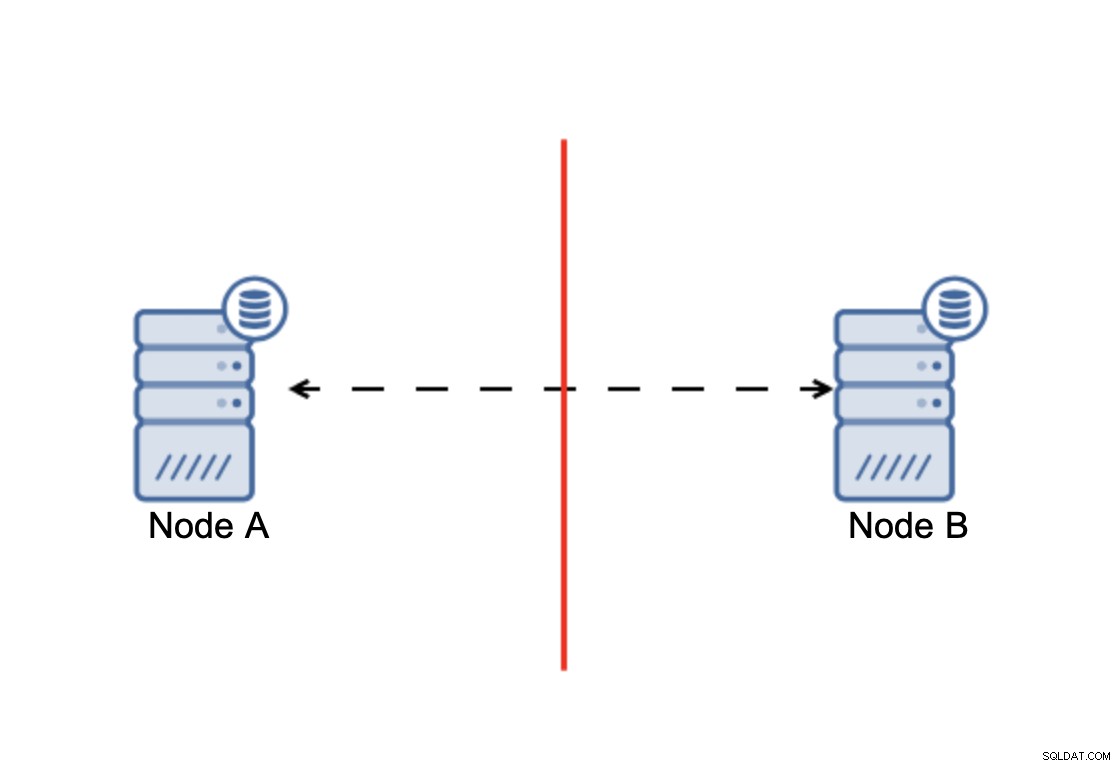
ネットワークが分割されると、2つの部分になります。クラスター。それぞれがクラスター内の全ノードの正確に50%で構成されます。これらの部分のどちらにも過半数はありません。ただし、ノードが3つある場合は、状況が異なります。
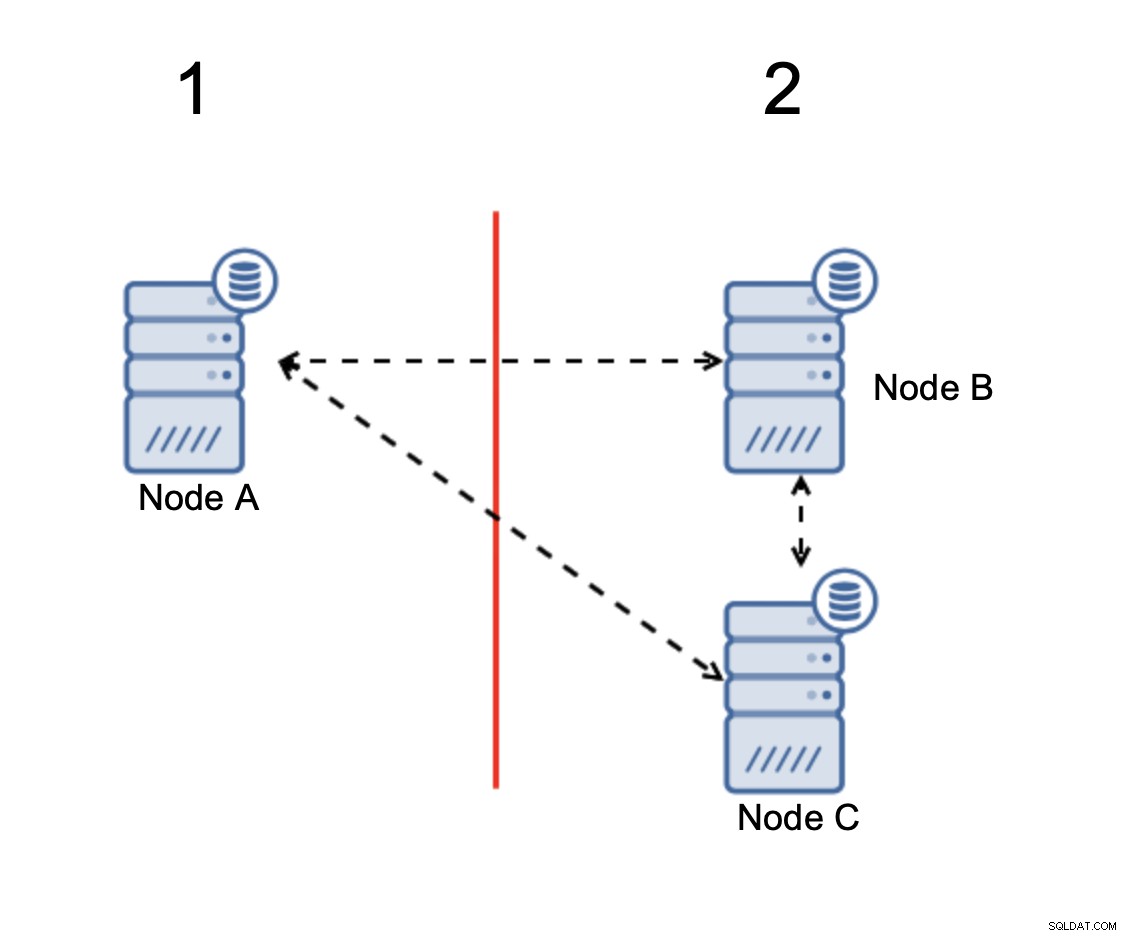
ノードBとCが過半数を占めています。その部分は、2つのノードで構成されています。したがって、3つのうちの3つは動作を継続できます。一方、ノードAはクラスター内のノードの33%のみを表すため、過半数を持たず、スプリットブレインを回避するためにトラフィックの処理を停止します。
このような実装では、スプリットブレインが発生する可能性はほとんどありません(奇妙で予期しないネットワーク状態、競合状態、またはクラスタリングコードの明らかなバグによって導入される必要があります。遭遇することは不可能ではありませんが、このような状況では、クォーラムベースのソリューションの1つを使用することが、現時点で存在するスプリットブレインを回避するための最良のオプションです。
スプリットブレインの処理に関しては理想的な選択肢ではありませんが、非同期レプリケーションは依然として実行可能なオプションです。非同期レプリケーションを使用してマルチクラウドデータベースを実装する前に、考慮すべきことがいくつかあります。
まず、フェイルオーバー。非同期レプリケーションには1つのライターが付属しています。書き込み可能なのはマスターのみで、他のノードは読み取り専用トラフィックのみを処理する必要があります。課題は、マスターの障害にどのように対処するかです。
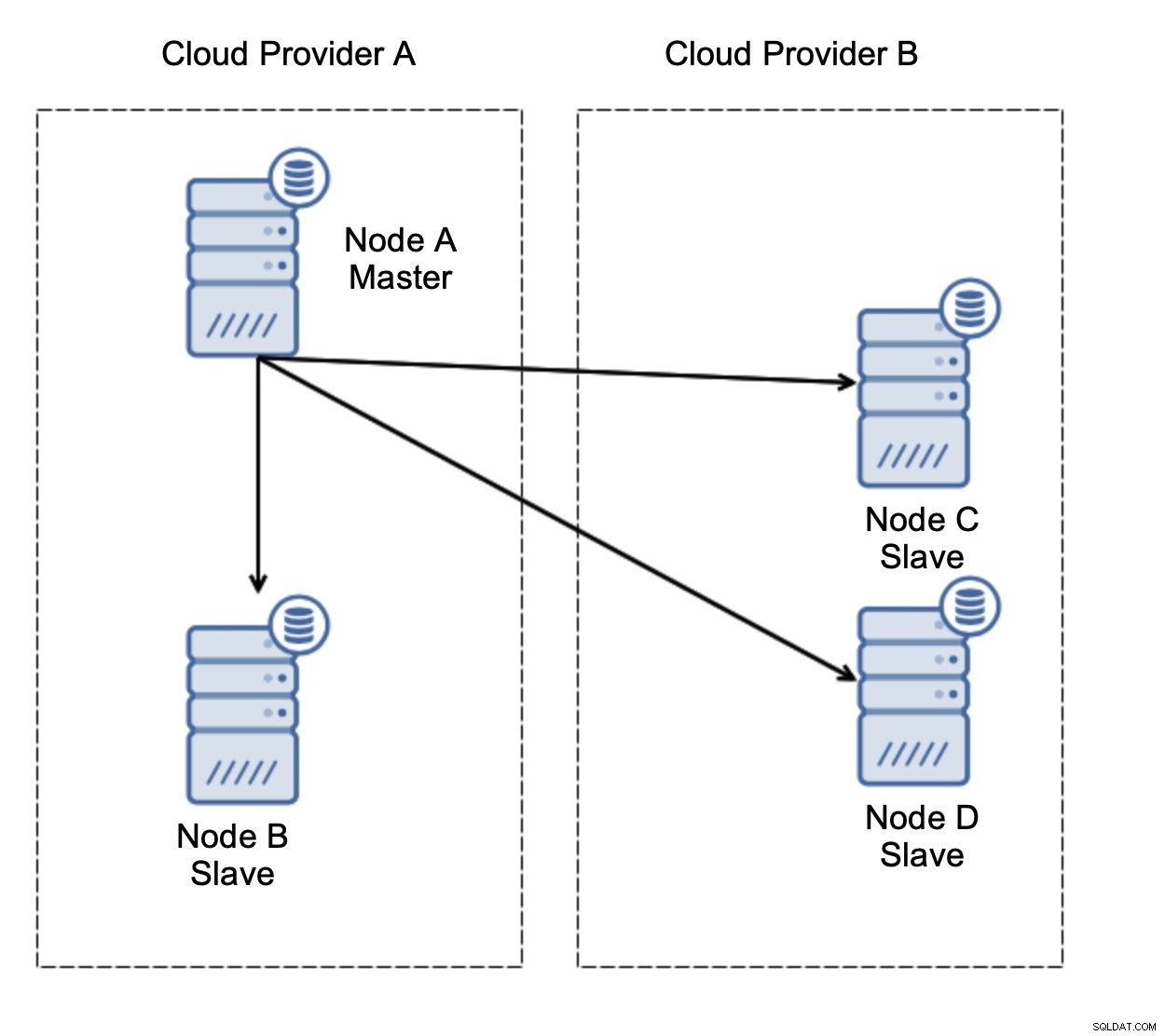
上の図のようにセットアップを検討しましょう。 2つのクラウドプロバイダーがあり、それぞれに2つのノードがあります。プロバイダーAはマスターもホストします。マスターが失敗した場合はどうなりますか?データベースが引き続き機能するように、スレーブの1つを昇格させる必要があります。理想的には、データベースを運用状態にするために必要な時間を短縮するための自動化されたプロセスである必要があります。ただし、ネットワークパーティショニングがあるとしたら、どうなるでしょうか。クラスターの状態をどのように確認する必要がありますか?
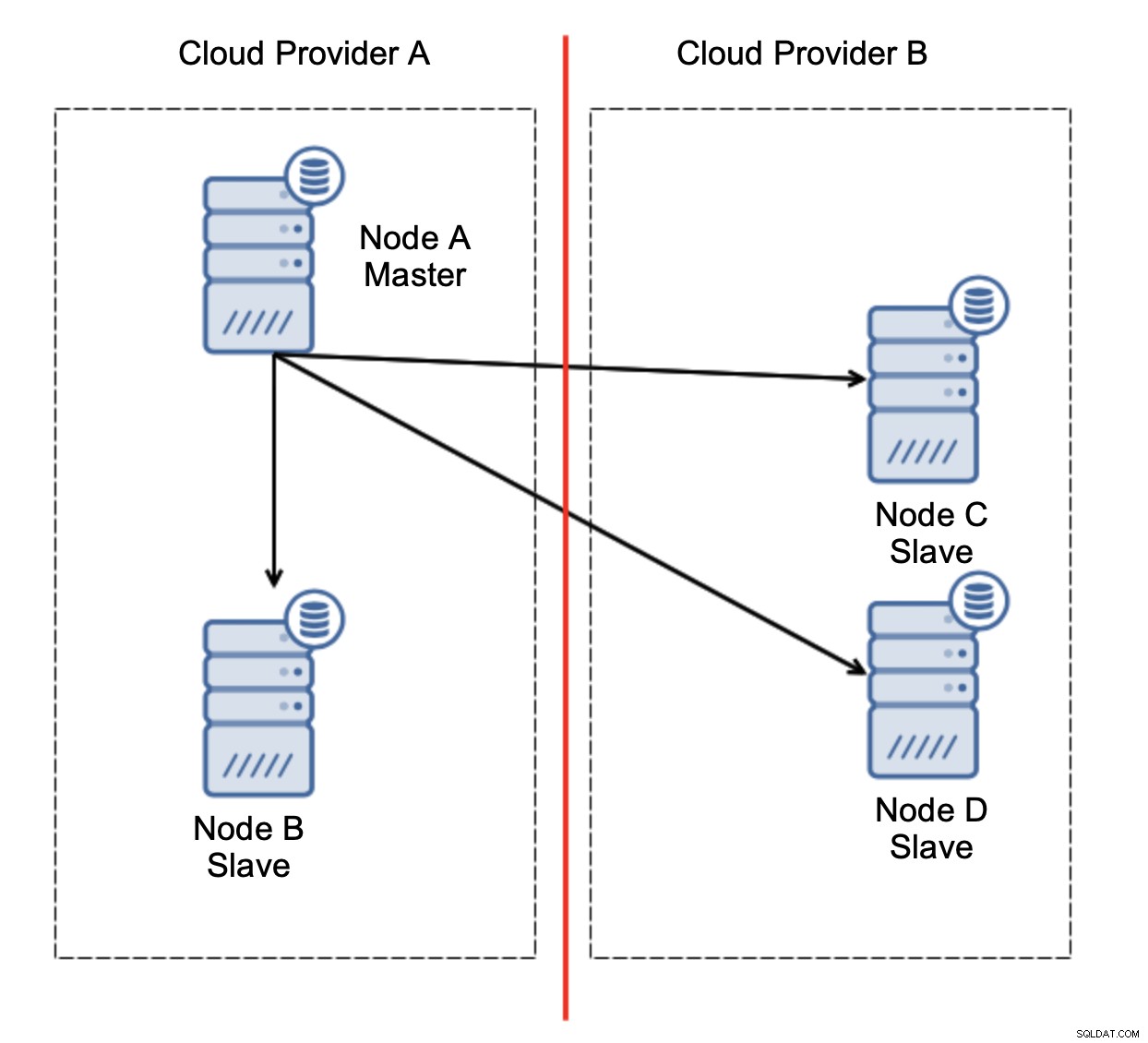
これは私たちが望んでいることではありません。ここにはいくつかのオプションがあります。まず、フェイルオーバーがマスターが配置されているネットワークセグメントの1つでのみ発生するようにフェイルオーバールールを定義できます。この場合、ノードBのみが自動的にマスターに昇格できることを意味します。これにより、ノードAがダウンした場合に自動フェイルオーバーが発生することを保証できますが、ネットワークパーティショニングがある場合はアクションは実行されません。自動フェイルオーバーの処理に役立つツール(ClusterControlなど)の一部は、ホワイトリストとブラックリストをサポートしているため、ユーザーは、フェイルオーバーの候補と見なすことができるノードと、マスターとして使用してはならないノードを定義できます。
別のオプションは、ある種の「トポロジー認識」ソリューションを実装することです。たとえば、ロードバランサーなどの外部サービスを使用してマスターの状態を確認することができます。
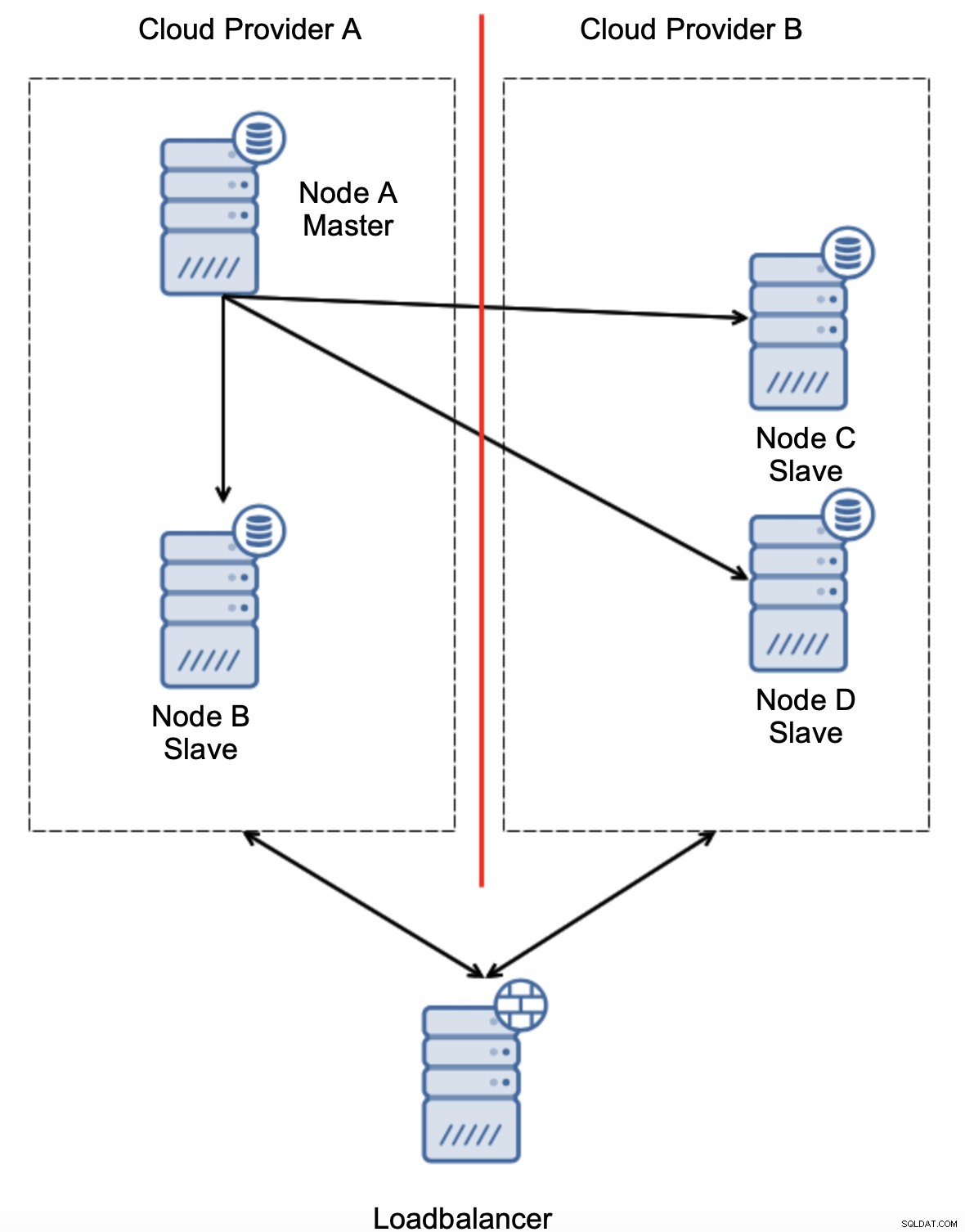
フェイルオーバーの自動化により、トポロジの状態を確認できる場合ロードバランサーの場合、3番目の場所にあるロードバランサーが実際に両方のデータセンターに到達でき、クラウドプロバイダーAのノードがダウンしておらず、クラウドプロバイダーBから到達できないことを明確にすることができます。追加のチェックレイヤーがClusterControlに実装されています。
最後に、自動フェイルオーバーの実装に使用するツールが何であれ、クォーラム対応になるように設計することもできます。次に、3つの場所に3つのノードがあるため、インフラストラクチャのどの部分を維持する必要があり、どの部分を維持する必要がないかを簡単に判断できます。
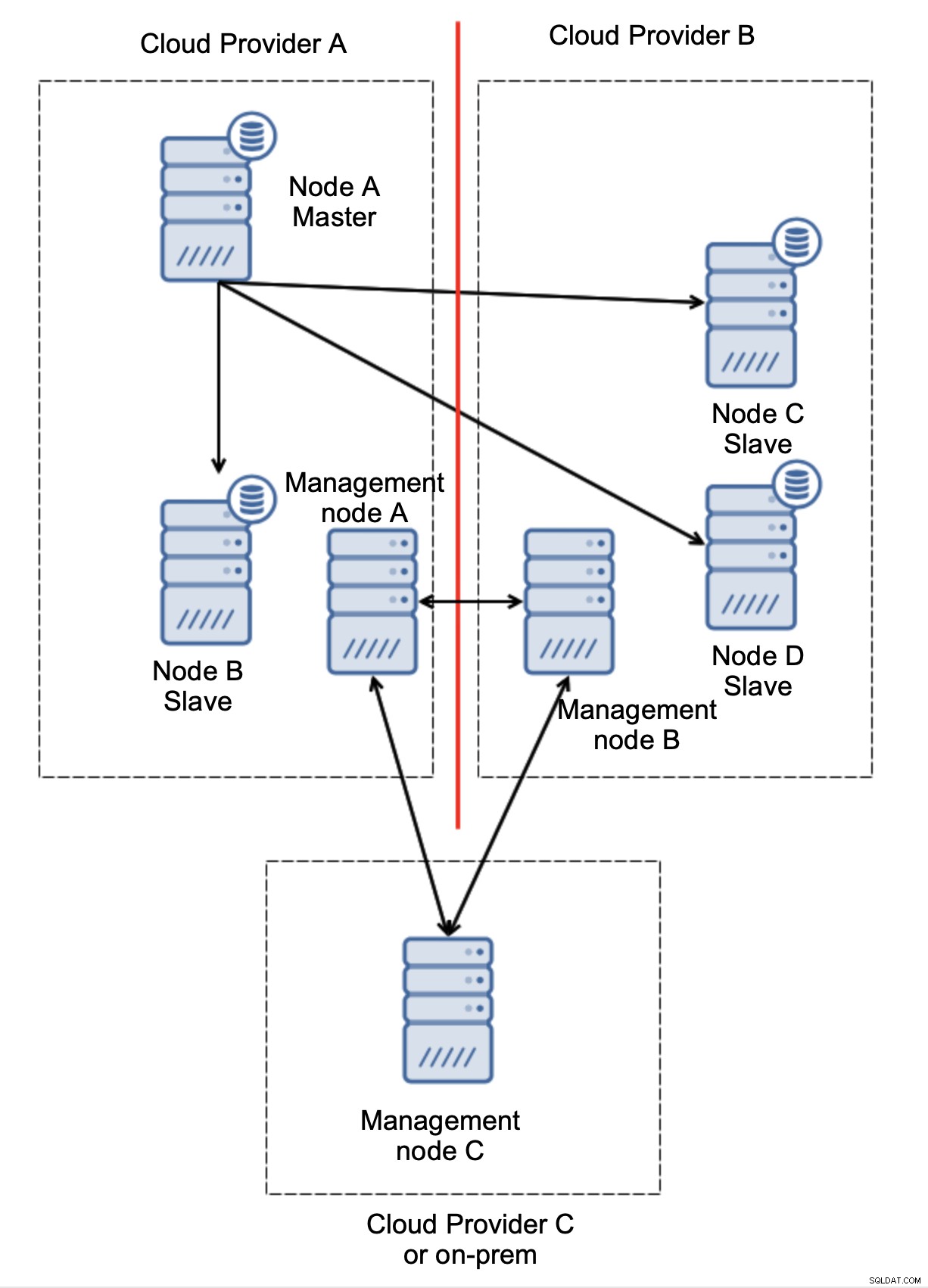
ここでは、問題が接続のみに関連していることがはっきりとわかります。プロバイダーAとBの間。管理ノードCはリレーとして機能するため、フェイルオーバーを開始しないでください。一方、1つのデータセンターが完全に遮断されている場合:

何が起こったかもかなり明確です。管理ノードAは、クラスターの大部分に到達できないことを報告しますが、管理ノードBとCは大部分を形成します。これに基づいて構築し、たとえば、管理ノードの状態に従ってトポロジを管理するスクリプトを作成することができます。つまり、クラウドプロバイダーAで実行されるスクリプトは、管理ノードAが過半数を形成していないことを検出し、すべてのデータベースノードを停止して、パーティション化されたクラウドプロバイダーで書き込みが発生しないようにします。
ClusterControlは、高可用性モードでデプロイされた場合、例で使用した管理ノードとして扱うことができます。 RAFTプロトコルに加えて3つのClusterControlノードは、特定のネットワークセグメントがパーティション化されているかどうかを判断するのに役立ちます。
このブログ投稿で、複数のクラウドプラットフォームにまたがるMySQLデプロイメントで発生する可能性のあるスプリットブレインシナリオについてのアイデアが得られることを願っています。