サンプルの
注:
このソリューションは、「すべてのアプローチには、検証の一部を含める必要があり、挿入が失敗した場合、または参照整合性の維持に失敗した場合のロールバック戦略」を実際には満たしていません。おそらく失敗することはありませんが、基準。本当に複雑なものをセットアップしたい場合は、私たちができますが、これで間違いなくこれらの変換を実行できるはずです。

ステップごとのデータフロー
1。 まず、ファイルを読み込みます。私の場合はCSVに変換しましたが、タブも問題ありません。 
2。 次に、combination lookup/updateを使用して、従業員名をEmployeeテーブルに挿入します。 挿入後、employee_idをidとしてデータストリームに追加します EmployeeNameを削除します データストリームから。

3。 ここでは、[値の選択]ステップを使用して、idの名前を変更しています。 employee_idへのフィールド 
4。 従業員と同じように役職を挿入し、データストリームに役職IDを追加して、JobLevelHistoryも削除します。 データストリームから。

5。 タイトルIDのtitle_idへの単純な名前変更(ステップ3を参照) 
6。 オフィスを挿入し、IDを取得し、ストリームからOfficeHistoryを削除します。

7。 オフィスIDの名前をoffice_idに変更するだけです(手順3を参照)

8。 最後のステップのデータをemployee_id,office_idの値で2つのストリームにコピーします およびemployee_id,title_id それぞれ。

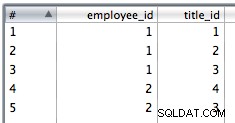
9。 テーブル挿入を使用して、結合データを挿入します。重複がある可能性があり、PK制約により一部の行が失敗するため、挿入エラーを無視するように選択しました。
出力テーブル




