これら2つのアプローチがデータベースで物理的にどのように表されるかを次に示します。
両方のアプローチを分析しましょう...
アプローチ1(両方の方向が表に保存されています):
- PRO:よりシンプルなクエリ。
- CON:のみを挿入/更新/削除すると、データが破損する可能性があります 一方向。
- マイナープロ:友情を複製できないようにするために追加の制約は必要ありません。
- さらに分析が必要です:
- TIE:1つのインデックスカバー 両方向なので、セカンダリインデックスは必要ありません。
- TIE:ストレージ要件。
- TIE:パフォーマンス。
アプローチ2(テーブルに保存されている一方向のみ):
- CON:より複雑なクエリ。
- PRO:反対方向がないため、反対方向の処理を忘れてデータを破損することはできません。 。
- マイナーコン:
CHECK(UID < FriendID)が必要 、したがって、同じ友情を2つの異なる方法で表すことはできません。また、(UID, FriendID)のキー その仕事をすることができます。 - さらに分析が必要です:
- TIE:カバー
には2つのインデックスが必要です クエリの両方向(
{UID, FriendID}の複合インデックス{FriendID, UID}の複合インデックス 。 - TIE:ストレージ要件。
- TIE:パフォーマンス。
- TIE:カバー
には2つのインデックスが必要です クエリの両方向(
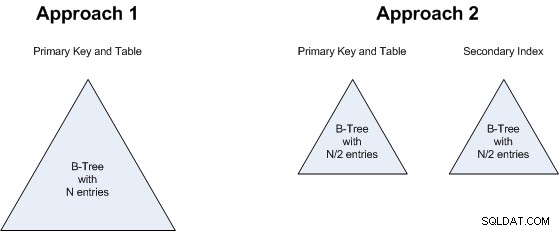
ポイント1 特に興味深いです。 MySQL /InnoDB常に クラスター データ、およびセカンダリインデックスは、クラスター化されたテーブルでは高額になる可能性があります(この記事 )、したがって、アプローチ2のセカンダリインデックスは、行数が少ないことによるすべての利点を使い果たしているように見える場合があります。 ただし 、セカンダリインデックスには、プライマリとまったく同じフィールドが含まれているため(逆の順序でのみ)、この特定のケースではストレージのオーバーヘッドはありません。また、テーブルヒープへのポインタもありません(テーブルヒープがないため)。したがって、通常のヒープベースのインデックスよりもストレージに関してはおそらくさらに安価です。また、クエリがインデックスでカバーされていると仮定すると、クラスター化テーブルのセカンダリインデックスに通常関連付けられているダブルルックアップもありません。したがって、これは基本的に同点です(アプローチ1とアプローチ2のどちらにも大きな利点はありません)。
ポイント2 はポイント1に関連しています。N個の値のBツリーがあるか、それぞれがN/2個の値を持つ2つのBツリーがあるかは関係ありません。したがって、これも同点です。どちらのアプローチでも、ほぼ同じ量のストレージが消費されます。
同じ理由がポイント3にも当てはまります :1つの大きなBツリーを検索するか2つの小さなBツリーを検索するかにかかわらず、大きな違いはないので、これも同点です。
したがって、堅牢性のために、そして多少醜いクエリと追加のCHECKの必要性にもかかわらず 、アプローチ2を使用します。