純粋なBigQuery(標準SQL)を使用してタスクを解決するオプションを利用したかった
前提条件/前提条件 :ソースデータはsandbox.temp.id1_id2_pairsにあります
これを独自のものに置き換えるか、質問のダミーデータでテストする場合は、次のようにこのテーブルを作成できます(もちろん、sandbox.tempを置き換えます)。 独自のproject.dataset )
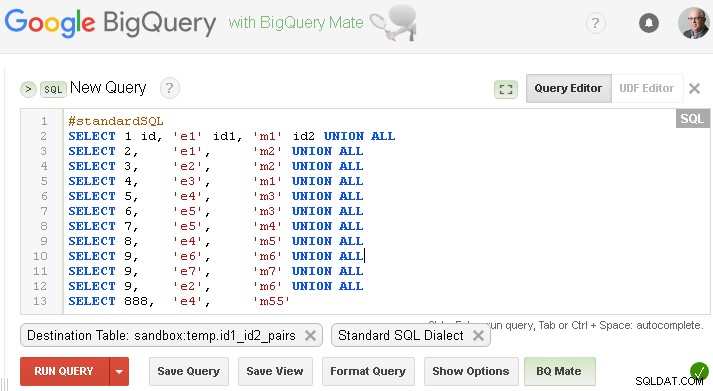
必ずそれぞれの宛先テーブルを設定してください
注 :この回答の下部にそれぞれのクエリをすべて(テキストとして)見つけることができますが、今のところ、スクリーンショットを使用して回答を示しています-すべてが表示されます-クエリ、結果、および使用されるオプション
したがって、3つのステップがあります。
ステップ1-初期化
ここでは、id2との接続に基づいてid1の初期グループ化を行います。
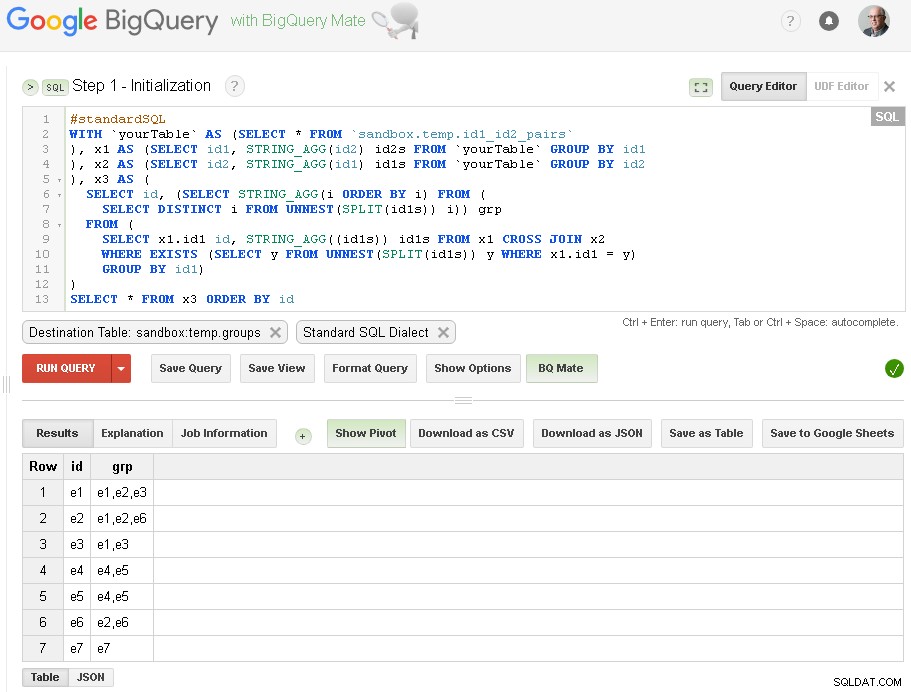
ここでわかるように、id2を介した単純な1レベルの接続に基づいて、それぞれの接続を持つすべてのid1値のリストを作成しました
出力テーブルはsandbox.temp.groupsです。
ステップ2-グループ化の反復
各反復で、すでに確立されているグループに基づいてグループ化を強化します。
クエリのソースは、前のステップの出力テーブル(sandbox.temp.groups)です。 )とDestinationは同じテーブル(sandbox.temp.groups )上書きあり
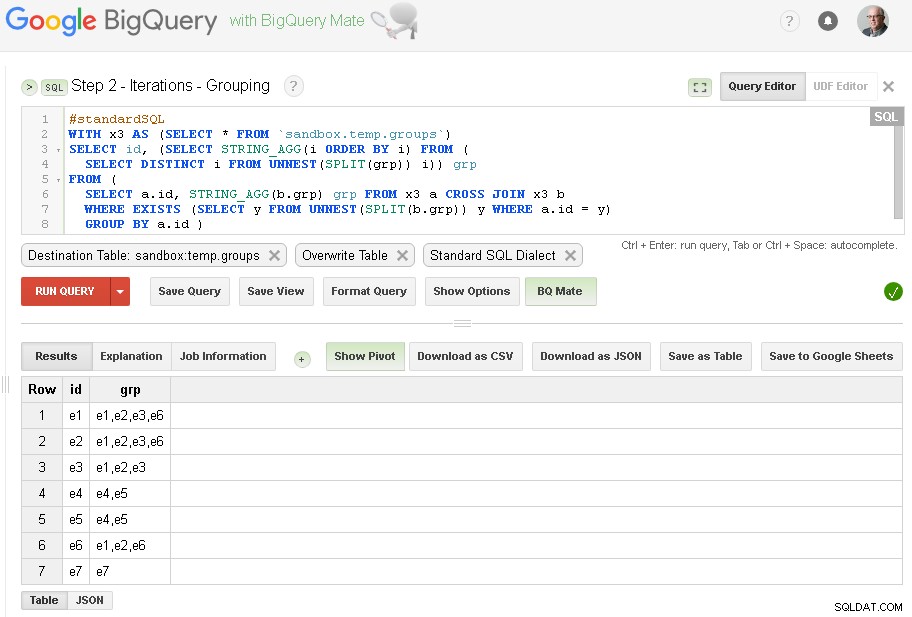
見つかったグループの数が前の反復と同じになるまで反復を続けます
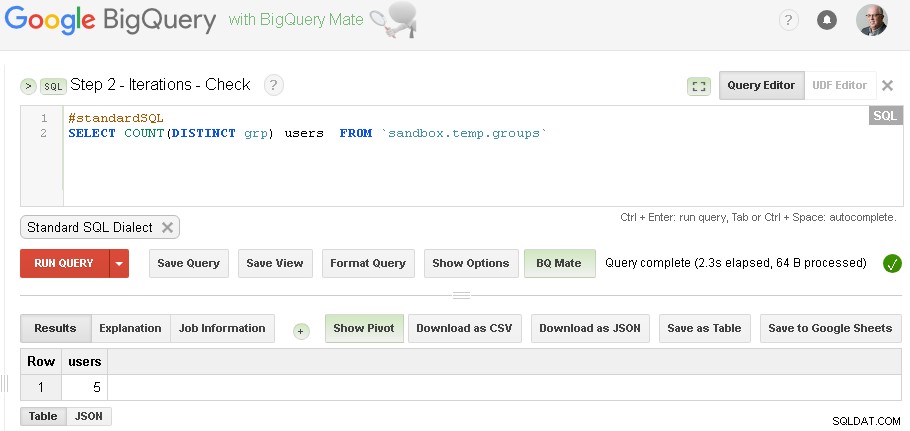
注 :2つのBigQuery Web UIタブを開くことができます(上記のように)。コードを変更せずに、グループ化を実行してから、反復が収束するまで何度もチェックします。
(前提条件のセクションで使用した特定のデータについては、3回の反復がありました。最初の反復では5人のユーザーが生成され、2回目の反復では3人のユーザーが生成され、3回目の反復では3人のユーザーが生成されました。これは、反復を行ったことを示しています。
もちろん、実際のケースでは(反復回数は3回を超える可能性があります)、何らかの自動化が必要です(回答の下部にあるそれぞれのセクションを参照してください)。
ステップ3–最終的なグループ化
id1のグループ化が完了すると、id2の最終的なグループ化を追加できます
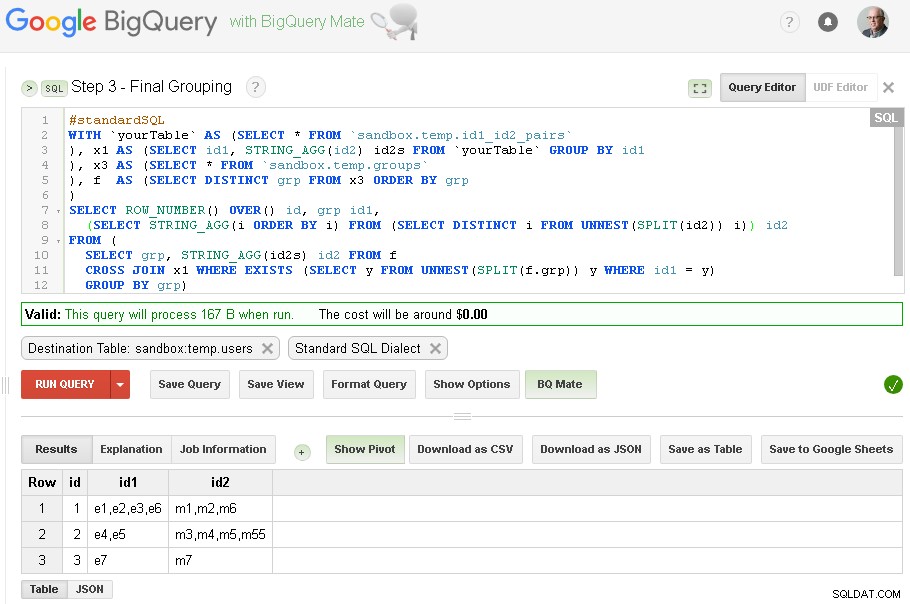
最終結果はsandbox.temp.usersにあります テーブル
使用済みクエリ (上記のロジックとスクリーンショットに従って、必要に応じてそれぞれの宛先テーブルと上書きを設定することを忘れないでください):
前提条件:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
ステップ1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
ステップ2-グループ化
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
ステップ2-チェック
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
ステップ3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
自動化 :
もちろん、反復が速く収束する場合は、上記の「プロセス」を手動で実行できます。したがって、10〜20回の実行になります。ただし、実際のケースでは、クライアント
を使用してこれを簡単に自動化できます。 お好みの