Galera Clusterには、標準のMySQLレプリケーション(またはグループレプリケーション)では利用できない多くの注目すべき機能が付属しています。自動ノードプロビジョニング、競合解決と自動フェイルオーバーを備えた真のマルチマスター。クラスタのパフォーマンスに影響を与える可能性のある制限もいくつかあります。幸い、これらに気付いていない場合は、回避策があります。そして、それを正しく行えば、これらの制限の影響を最小限に抑え、全体的なパフォーマンスを向上させることができます。
これまで、AWSクラウドでのGaleraの実行など、GaleraClusterに関連する多くのヒントとコツについて説明しました。このブログ投稿では、Galeraを最大限に活用する方法の例とともに、パフォーマンスの側面を明確に掘り下げています。
レプリケーションペイロード
ちょっとした紹介-Galeraはコミット段階で書き込みセットを複製し、wsrep複製プラグインを介して書き込みセットを発信元ノードから受信側ノードに同期的に転送します。このプラグインは、レシーバーノードの書き込みセットも認証します。認証プロセスに合格すると、発信元ノードのクライアントにOKが返され、後で非同期で受信側ノードに適用されます。それ以外の場合、トランザクションは発信元ノードでロールバックされ(クライアントにエラーが返されます)、受信側ノードに転送された書き込みセットは破棄されます。
ライトセットは、データベースの状態を変更するトランザクション内の書き込み操作で構成されます。ガレラクラスターでは、自動コミット デフォルトは1(有効)です。文字通り、BEGIN、START TRANSACTION、またはSET autocommit =0で明示的に開始しない限り、GaleraClusterで実行されるSQLステートメントはすべてトランザクションとして囲まれます。次の図は、単一のDMLステートメントをライトセットにカプセル化する方法を示しています。
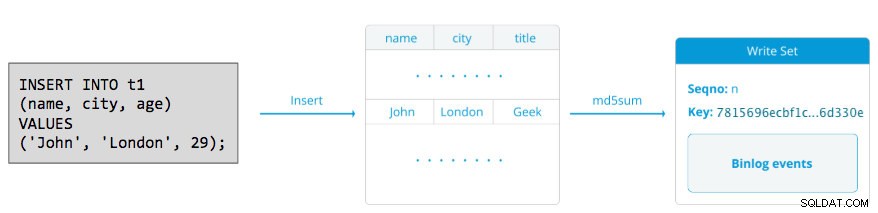
DML(INSERT、UPDATE、DELETE ..)の場合、書き込みセットペイロードは特定のトランザクションのバイナリログイベントで構成されますが、DDL(ALTER、GRANT、CREATE ..)の場合、書き込みセットペイロードはDDLステートメント自体です。 DMLの場合、書き込みセットは、DDLの場合( wsrep_osu_method に応じて)、レシーバーノードでの競合に対して認定される必要があります。 、デフォルトはTOI)、クラスタークラスターはすべてのノードで同じ全順序シーケンスでDDLステートメントを実行し、DDLの進行中に他のトランザクションがコミットするのをブロックします(RSUも参照)。簡単に言うと、GaleraClusterはDDLとDMLのレプリケーションを異なる方法で処理します。
往復時間
一般に、次の要因によって、Galeraが発信元ノードからすべての受信者ノードに書き込みセットを複製できる速度が決まります。
- 発信元ノードからクラスター内で最も遠いノードへのラウンドトリップ時間(RTT)。
- 転送され、受信側ノードでの競合が認定される書き込みセットのサイズ。
たとえば、3ノードのGaleraクラスターがあり、ノードの1つが10ミリ秒(0.01秒)離れている場合、競合することなく同じ行に1秒間に100回を超えて書き込むことができる可能性はほとんどありません。この振る舞いを非常によく説明しているMarkCallaghanからの人気のある引用があります:
「[Galeraクラスター内]特定の行は、RTTごとに複数回変更することはできません」
RTT値を測定するには、発信元ノードでクラスター内の最も遠いノードにpingを実行するだけです。
$ ping 192.168.55.173 # the farthest node数秒(または数分)待ってから、コマンドを終了してください。 ping統計セクションの最後の行は、私たちが探しているものです:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 ms最大 値は1.340ミリ秒(0.00134秒)であり、最小を見積もるときにこの値を取る必要があります このクラスターの1秒あたりのトランザクション数(tps)。 平均 値は0.431ms(0.000431s)であり、これを使用して平均を推定できます。 minの間にtps 値は0.111ms(0.000111s)で、これを使用して最大を推定できます。 tps。 mdevは、RTTサンプルが平均からどのように分布したかを意味します。値が小さいほど、RTTがより安定していることを意味します。
したがって、1秒あたりのトランザクション数は、RTT(秒単位)を1秒に分割することで見積もることができます。

結果として、
- 最小tps:1 / 0.00134(最大RTT)=746.26〜746 tps
- 平均tps:1 / 0.000431(avg RTT)=2320.19〜2320 tps
- 最大tps:1 / 0.000111(最小RTT)=9009.01〜9009 tps
これは、レプリケーションのパフォーマンスを予測するための単なる見積もりであることに注意してください。すべてをデプロイして実行した後は、データベース側でこれを改善するためにできることはあまりありません。ただし、データベースサーバーを相互に近づけて移動または移行して、ノード間のRTTを改善したり、ネットワーク周辺機器やインフラストラクチャをアップグレードしたりする場合を除きます。これには、メンテナンスウィンドウと適切な計画が必要になります。
大きなトランザクションをチャンクアップ
もう1つの要因は、トランザクションのサイズです。ライトセットが転送された後、認証プロセスがあります。認証は、ノードが書き込みセットを適用できるかどうかを判断するプロセスです。 Galeraは、すべての行からMD5チェックサム疑似キーを生成します。認証のコストは、書き込みセットのサイズによって異なります。これは、認証インデックス(ハッシュテーブル)への一意のキールックアップの数に変換されます。 1回のトランザクションで500,000行を更新する場合、例:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;上記は、500,000のバイナリログイベントを含む単一の書き込みセットを生成します。この巨大な書き込みセットは、 wsrep_max_ws_sizeを超えません。 (デフォルトは2GB)したがって、Galeraレプリケーションプラグインによってクラスター内のすべてのノードに転送され、スレーブキューに残っている競合するトランザクションについてレシーバーノード上のこれらの500,000行を認証します。最後に、認証ステータスがグループレプリケーションプラグインに返されます。トランザクションサイズが大きいほど、別のマスターからのトランザクションと競合するリスクが高くなります。競合するトランザクションはサーバーリソースを浪費し、さらにオリジネーターノードへの巨大なロールバックを引き起こします。 MySQLのロールバック操作は、コミット操作よりもはるかに遅く、最適化されていないことに注意してください。
上記のSQLステートメントは、以下の例のように、単純なループを使用して、よりガレラに適したステートメントに書き直すことができます。
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
done上記のシェルコマンドは、トランザクションごとに1000行を500回更新し、実行の間に2秒間待機します。同様の結果を達成するために、ストアドプロシージャまたは他の手段を使用することもできます。 SQLクエリを書き直すことができない場合は、競合のリスクを減らすために、メンテナンスウィンドウ中に大きなトランザクションを実行するようにアプリケーションに指示するだけです。
大幅な削除の場合は、Percona Toolkitのpt-archiverを使用することを検討してください。これは、OLTPクエリに大きな影響を与えることなく、テーブルから古いデータをかじる、影響の少ない転送専用のジョブです。
並列スレーブスレッド
Galeraでは、アプライヤーはマルチスレッドプロセスです。 Applierは、Galera内で実行され、別のノードからの着信書き込みセットを適用するスレッドです。つまり、すべてのレシーバーが、オリジネーター(マスター)ノードから直接送信される複数のDML操作を同時に実行することが可能です。 Galera並列レプリケーションは、安全に実行できる場合にのみトランザクションに適用されます。これにより、ノードが発信元ノードと同期する可能性が高まります。ただし、レプリケーション速度はRTTとライトセットサイズに制限されます。
これを最大限に活用するには、次の2つのことを知る必要があります。
- サーバーにあるコアの数。
- wsrep_cert_deps_distanceの値 ステータス。
ステータスwsrep_cert_deps_distance 並列化の潜在的な程度を教えてくれます。これは、並列に適用できる可能性のある最高と最低のseqno値の間の平均距離の値です。 wsrep_cert_deps_distanceを使用できます 可能なスレーブスレッドの最大数を決定するためのステータス変数。これは時間の経過に伴う平均値であることに注意してください。したがって、適切な値を取得するには、安定した値が得られるまで、テストワークロードまたはベンチマークを介して書き込み操作でクラスターをヒットする必要があります。
コアの数を取得するには、次のコマンドを使用するだけです。
$ grep -c processor /proc/cpuinfo
4理想的には、CPUコアごとに2、3、または4スレッドのスレーブアプライヤーが適切なスタートです。したがって、スレーブスレッドの最小値はCPUコアの4 x数である必要があり、 wsrep_cert_deps_distanceを超えてはなりません。 値:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+wsrep_slave_thread を使用して、スレーブアプライヤースレッドの数を制御できます。 変数。これは動的変数ですが、数を増やすだけですぐに効果があります。値を動的に減らすと、適用が終了してからアプライヤースレッドが終了するまでに時間がかかります。推奨値は16から48の間です:
mysql> SET GLOBAL wsrep_slave_threads = 48;並列スレーブスレッドが機能するためには、以下を設定する必要があることに注意してください(通常はGalera Cluster用に事前構成されています):
innodb_autoinc_lock_mode=2ガレラキャッシュ(gcache)
Galeraは、gcacheと呼ばれる特定のサイズの事前に割り当てられたファイルを使用します。このファイルでは、Galeraノードが書き込みセットのコピーを循環バッファースタイルで保持します。デフォルトでは、そのサイズは128MBで、かなり小さいです。インクリメンタルステート転送(IST)は、ドナーのgcacheで使用可能な欠落しているライトセットのみを送信することによってジョイナーを準備する方法です。 ISTは、状態スナップショット転送(SST)よりも高速であり、非ブロッキングであり、ドナーに大きなパフォーマンスの影響を与えません。可能な限り、これを推奨するオプションにする必要があります。
ISTは、ジョイナーが見逃したすべての変更がドナーのgcacheファイルに残っている場合にのみ達成できます。このための推奨設定は、MySQLデータセット全体と同じ大きさにすることです。ディスク容量が限られているかコストがかかる場合は、Galeraノード間のデータ同期パフォーマンスに影響を与える可能性があるため、gcacheサイズの適切なサイズを決定することが重要です。
以下のステートメントは、Galeraによって複製されたデータの量のアイデアを提供します。ピーク時にGaleraノードの1つで次のステートメントを実行します(MariaDB>10.0およびPXC>5.6、galera> 3.xでテスト済み):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
GaleraノードはSSTの参加を必要とせずに、約16分のダウンタイムが発生する可能性があると推定できます(Galeraが参加者の状態を判別できない場合を除く)。これが短すぎてノードに十分なディスク容量がある場合は、 wsrep_provider_options ="gcache.size =
gcache.recover =yesを使用することもお勧めします wsrep_provider_options (Galera> 3.19)、Galeraはgcacheファイルを削除するのではなく、起動時に使用可能な状態に回復しようとします。これにより、ISTの機能が維持され、SSTが可能な限り回避されます。 CodershipとPerconaは、ブログでこれについて詳しく説明しています。 ISTは、ノードがクラスターに再参加した後に同期するための最良の方法です。 xtrabackupまたはmariabackupよりも50%高速で、mysqldumpよりも5倍高速です。
非同期スレーブ
Galeraノードは緊密に結合されており、レプリケーションのパフォーマンスは最も遅いノードと同じくらい高速です。 Galeraは、フロー制御メカニズムを使用して、メンバー間のレプリケーションフローを制御し、スレーブラグを排除します。レプリケーションは、すべてのノードですべて高速またはすべて低速にすることができ、Galeraによって自動的に調整されます。フロー制御について知りたい場合は、PerconaのJayJanssenによるこのブログ投稿を読んでください。
ほとんどの場合、長時間実行される分析(読み取り集約型)やバックアップ(読み取り集約型、ロック)などの重い操作は避けられないことが多く、クラスターのパフォーマンスを低下させる可能性があります。このタイプのクエリを実行する最良の方法は、非同期スレーブなどの緩く結合されたレプリカサーバーにクエリを送信することです。
非同期スレーブは、標準のMySQL非同期レプリケーションプロトコルを使用してGaleraノードからレプリケートします。 1つのGaleraノードに接続できるスレーブの数に制限はなく、中間マスターとのチェーンアウトも可能です。このサーバーで実行されるMySQL操作は、レプリケーションリンクを確立する前にGaleraノードで完全バックアップを実行してスレーブをステージングする必要がある初期同期フェーズを除いて、クラスターのパフォーマンスに影響を与えません(ただし、ClusterControlでは非同期を構築できます)クラスタに接続する前に、まず既存のバックアップからスレーブにします。
GTID(Global Transaction Identifier)は、ノード間でより優れたトランザクションマッピングを提供し、MySQL5.6およびMariaDB10.0でサポートされています。 GTIDを使用すると、別のマスター(別のGaleraノード)へのスレーブでのフェイルオーバー操作が簡素化され、正確なログファイルと位置を把握する必要がなくなります。 Galeraにも独自のGTID実装が付属していますが、これら2つは互いに独立しています。
ClusterControl->レプリケーションスレーブ機能の追加を使用している場合、非同期スレーブのスケールアウトはワンクリックで行えます:
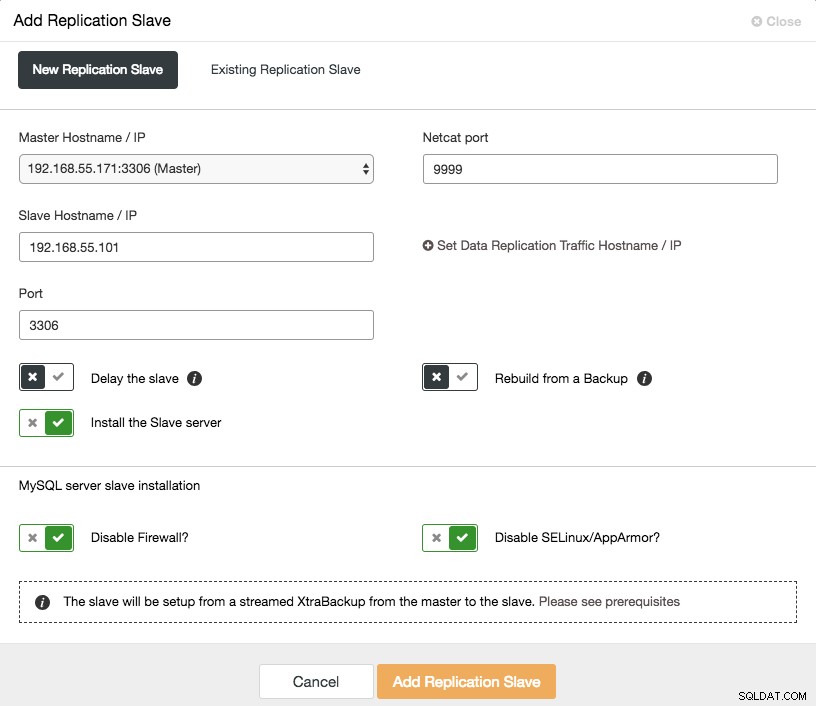
このセットアップを続行する前に、マスター(選択したGaleraノード)でバイナリログを有効にする必要があることに注意してください。この前の投稿では、手動による方法についても説明しました。
次のClusterControlのスクリーンショットは、クラスタートポロジを示しています。これは、非同期スレーブを使用したGaleraClusterアーキテクチャを示しています。
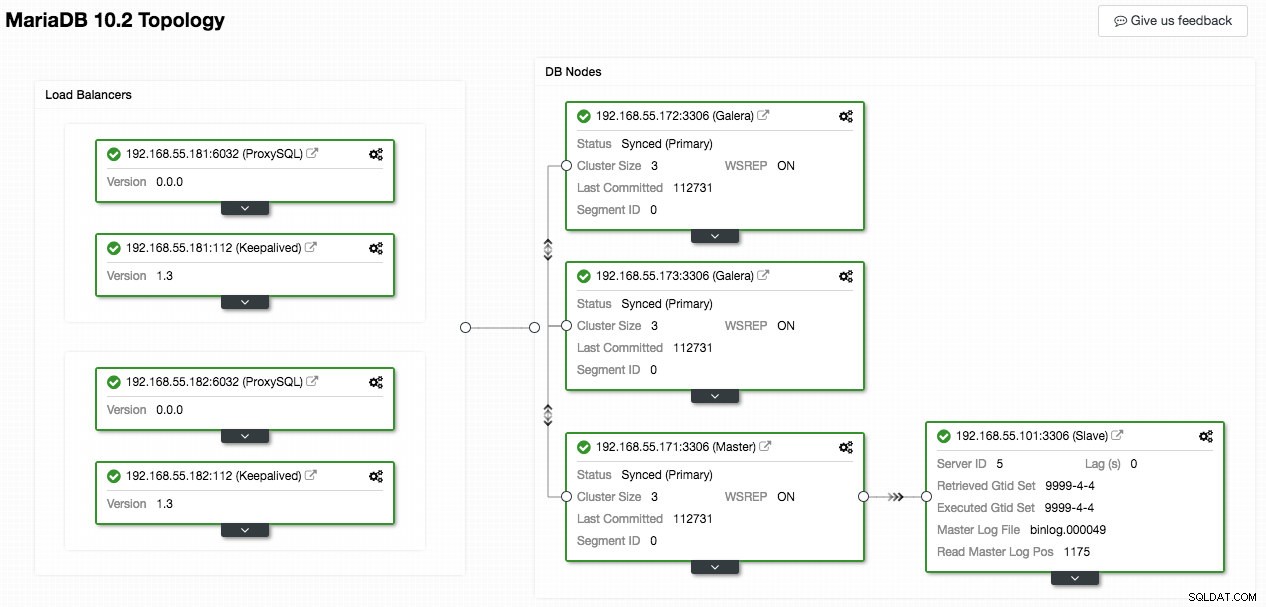
ClusterControlはトポロジーを自動的に検出し、上記のような非常にクールな図を生成します。各ボックスの右上の歯車アイコンをクリックして、このページから直接管理タスクを実行することもできます。
SQL対応のリバースプロキシ
ProxySQLとMariaDBMaxScaleは、MySQLプロトコルを理解し、Galeraノードの前でゲートウェイ、ルーター、ロードバランサー、ファイアウォールとして機能するインテリジェントなリバースプロキシです。 LVSやKeepalivedなどの仮想IPアドレスプロバイダーの助けを借りて、これをGaleraマルチマスターレプリケーションテクノロジーと組み合わせることで、アプリケーションポイントから発生する可能性のあるすべての単一障害点(SPOF)を排除し、可用性の高いデータベースサービスを利用できます。 -ビュー。これにより、アーキテクチャ全体の可用性と信頼性が確実に向上します。
このアプローチのもう1つの利点は、実際のデータベースサーバーに到達する前に、一連のルールに基づいて着信SQLクエリを監視、書き換え、または再ルーティングできることです。これにより、アプリケーション側またはクライアント側での変更が最小限に抑えられ、クエリが次のようにルーティングされます。最適なパフォーマンスのためのより適切なノード。 LOCKTABLESやFLUSHTABLESWITH READ LOCKのようなGaleraの危険なクエリは、システムに大混乱を引き起こす前に防ぐことができますが、「ホットスポット」クエリ(異なるクエリが同時にアクセスしたい行)のようなクエリに影響を与える可能性があります。トランザクションの競合のリスクを減らすために、書き直されるか、単一のGaleraノードにリダイレクトされます。 OLAPやバックアップなどの大量の読み取り専用クエリの場合、非同期スレーブがある場合はそれらを非同期スレーブにルーティングできます。
リバースプロキシは、データベースの状態、クエリ、および変数も監視して、トポロジの変更を理解し、バックエンドサーバーへの正確なルーティング決定を生成します。間接的に、Galeraノードのすべてを定期的にチェックする必要なしに、ノードの監視とクラスターの概要を一元化します。次のスクリーンショットは、ClusterControlのProxySQLモニタリングダッシュボードを示しています。
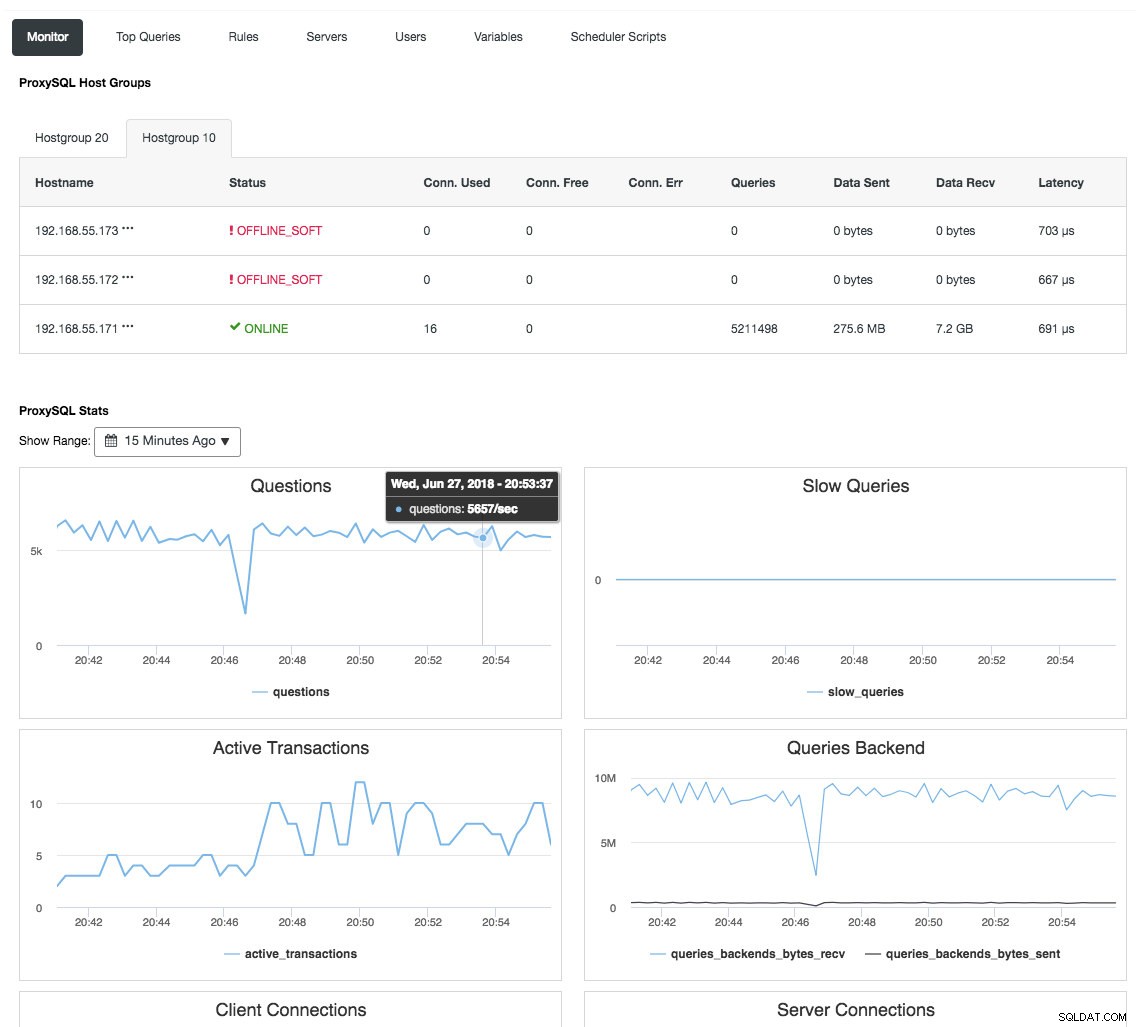
このブログ投稿「ClusterControlDBAになる:ロードバランサーを介してDBコンポーネントをHAにする」で詳しく説明されているように、ロードバランサーがGaleraClusterを大幅に改善するためにもたらすことができる他の多くの利点もあります。
最終的な考え
Galera Clusterが内部でどのように機能するかをよく理解することで、いくつかの制限を回避し、データベースサービスを改善できます。ハッピークラスタリング!