「スプリットブレイン」という用語について聞いたことがあるかもしれません。それは何ですか?それはあなたのクラスターにどのように影響しますか?このブログ投稿では、それが正確に何であるか、データベースにどのような危険をもたらす可能性があるか、それを防ぐ方法、すべてがうまくいかない場合にデータベースから回復する方法について説明します。
単一インスタンスの時代は過ぎ去りました。現在、ほとんどすべてのデータベースがレプリケーショングループまたはクラスターで実行されています。これは高可用性とスケーラビリティには最適ですが、分散データベースには新しい危険性と制限があります。致命的になる可能性のある1つのケースは、ネットワークの分割です。ネットワークの問題により、2つの部分に分割された複数のノードのクラスターを想像してみてください。明らかな理由(データの一貫性)のために、両方の部分が互いに分離されており、それらの間でデータを転送できないため、両方の部分が同時にトラフィックを処理することはできません。また、アプリケーションの観点からも間違っています。最終的にはデータを同期する方法があるとしても(2つのデータセットの調整は簡単ではありませんが)。しばらくの間、アプリケーションの一部は、データベースクラスターの他の部分にアクセスする他のアプリケーションホストによって行われた変更を認識しません。これは深刻な問題につながる可能性があります。
クラスターが書き込みを受け入れる意思のある2つ以上の部分に分割されている状態は、「スプリットブレイン」と呼ばれます。
スプリットブレインの最大の問題は、クラスターの両方の部分で書き込みが発生するため、データのドリフトです。 MySQLフレーバーはいずれも、分岐したデータセットをマージする自動化された手段を提供しません。このような機能は、MySQLレプリケーション、グループレプリケーション、またはGaleraにはありません。データが分岐したら、唯一の選択肢は、クラスターの一部を信頼できる情報源として使用し、他の部分で実行された変更を破棄することです。ただし、データをマージするために手動のプロセスに従うことができない場合を除きます。
これが、スプリットブレインの発生を防ぐ方法から始める理由です。これは、データの不一致を修正するよりもはるかに簡単です。
スプリットブレインを防ぐ方法
正確な解決策は、データベースのタイプと環境のセットアップによって異なります。 GaleraClusterとMySQLレプリケーションの最も一般的なケースのいくつかを見ていきます。
ガレラクラスター
ガレラには、スプリットブレインを処理するための「サーキットブレーカー」が組み込まれています。これは、クォーラムメカニズムに依存しています。ノードの過半数(50%+ 1)がクラスターで使用可能な場合、Galeraは正常に動作します。過半数がない場合、Galeraはトラフィックの提供を停止し、いわゆる「非プライマリ」状態に切り替わります。これは、ガレラを使用しているときにスプリットブレインの状況に対処するために必要なほとんどすべてです。確かに、過半数がない場合でも、Galeraを「プライマリ」状態に強制する手動の方法があります。そうしない限り、安全であるはずです。
クォーラムの計算方法には重要な影響があります。単一のデータセンターレベルでは、ノードの数を奇数にする必要があります。 3つのノードは、1つのノードの障害に対する許容度を提供します(2つのノードは、クラスター内のノードの50%以上が使用可能であるという要件に一致します)。 5つのノードは、2つのノードの障害に対する許容度を提供します(5〜2 =3、これは5つのノードから50%以上です)。一方、4つのノードを使用しても、3つのノードクラスターよりも許容度は向上しません。それでも1つのノードの障害(4-1 =3、4から50%以上)のみを処理しますが、2つのノードの障害はクラスターを使用できなくします(4-2 =2、わずか50%、それ以上)。
単一のデータセンターにGaleraクラスターを導入する場合、理想的には、ノードがデータセンターに存在する限り、複数のアベイラビリティーゾーン(個別の電源、ネットワークなど)にノードを分散する必要があることに注意してください。 。簡単な設定は次のようになります。
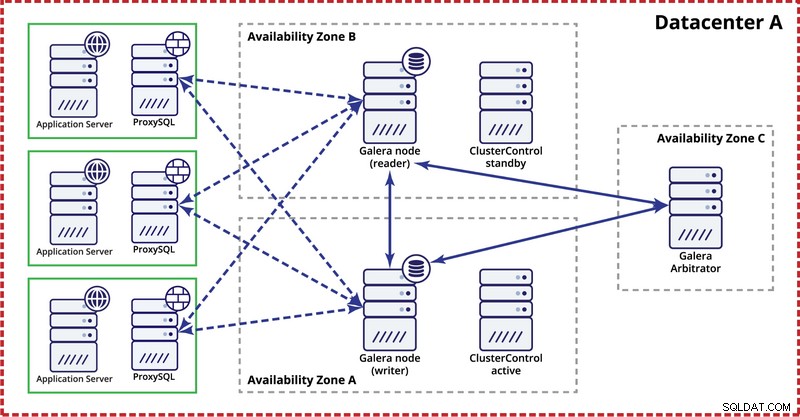
マルチデータセンターレベルでは、これらの考慮事項も適用できます。 Galeraクラスターでデータセンターの障害を自動的に処理する場合は、奇数のデータセンターを使用する必要があります。コストを削減するために、データベースノードの代わりにGaleraアービトレーターを使用できます。 Galeraアービトレーター(garbd)は、クォーラム計算に参加するプロセスですが、データは含まれていません。これにより、リソースを大量に消費しないため、非常に小さなインスタンスでも使用できます。ただし、すべてのレプリケーショントラフィックを「認識」するため、ネットワーク接続は良好である必要があります。セットアップの例は、次の図のようになります。
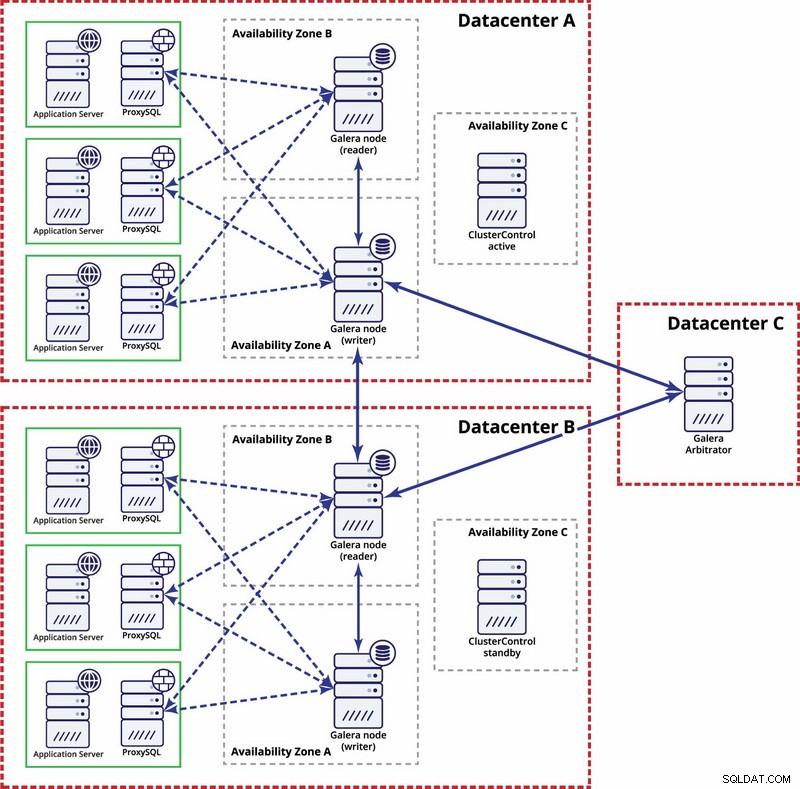
MySQLレプリケーション
MySQLレプリケーションの最大の問題は、Galeraクラスターのように、クォーラムメカニズムが組み込まれていないことです。したがって、セットアップがスプリットブレインの影響を受けないようにするには、さらに多くの手順が必要です。
1つの方法は、データセンター間の自動フェイルオーバーを回避することです。単一のデータセンター内でのみフェイルオーバーするようにフェイルオーバーソリューションを構成できます(ClusterControl、MHA、またはOrchestratorを使用できます)。データセンターが完全に停止した場合、フェイルオーバーの方法と、障害が発生したデータセンターのサーバーが使用されないようにする方法を決定するのは管理者の責任です。
それをより自動化するためのオプションがあります。 Consulを使用して、レプリケーションセットアップ内のノード、およびそれらのノードのどれがマスターであるかに関するデータを保存できます。次に、このエントリを更新し、書き込みを2番目のデータセンターに移動するのは管理者の責任です(またはスクリプトを介して)。 Orchestratorノードを複数のデータセンターに分散してスプリットブレインを検出できるOrchestrator/Raftセットアップのメリットを享受できます。これに基づいて、前述のように、領事館などのエントリを更新するなど、さまざまなアクションを実行できます。重要なのは、これはガレラクラスターよりもセットアップと自動化がはるかに複雑な環境であるということです。以下に、MySQLレプリケーションのマルチデータセンターセットアップの例を示します。
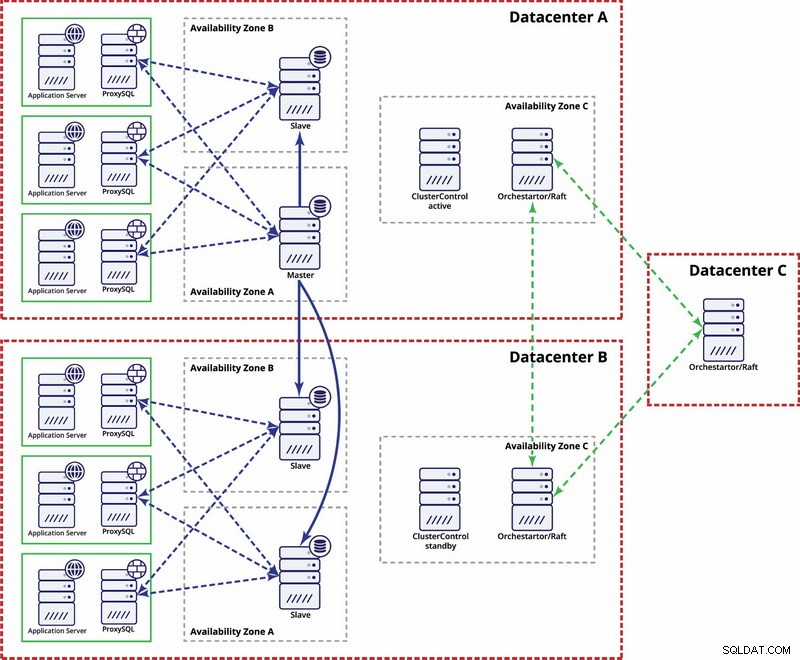
それを機能させるには、スクリプトを作成する必要があることに注意してください。つまり、オーケストレーターノードのスプリットブレインを監視し、STONITHを実装するために必要なアクションを実行し、ネットワークが収束して接続が確立されたら、データセンターAのマスターが使用されないようにします。復元されます。
スプリットブレインが発生しました-次に何をしますか?
最悪のシナリオが発生し、データがドリフトしました。ここで何ができるかについて、いくつかのヒントを提供しようと思います。残念ながら、正確な手順は主にスキーマの設計に依存するため、正確なハウツーガイドを作成することはできません。
覚えておく必要があるのは、最終的な目標は、あるマスターから別のマスターにデータをコピーし、テーブル間のすべての関係を再作成することです。
まず、マスターとしてデータを提供し続けるノードを特定する必要があります。これは、他の「マスター」インスタンスに保存されているデータをマージするデータセットです。それが完了したら、現在のマスターにない古いマスターのデータを特定する必要があります。これは手作業になります。テーブルにタイムスタンプがある場合は、それらを利用して不足しているデータを特定できます。最終的に、バイナリログにはすべてのデータ変更が含まれるため、それらを信頼できます。また、データ構造とテーブル間の関係についての知識に頼らなければならない場合もあります。データが正規化されている場合、1つのテーブルの1つのレコードが、他のテーブルのレコードに関連付けられている可能性があります。たとえば、アプリケーションは、user_idを使用して「address」テーブルに関連する「user」テーブルにデータを挿入する場合があります。関連するすべての行を見つけて抽出する必要があります。
次のステップは、このデータを新しいマスターにロードすることです。ここで注意が必要な部分があります。事前にセットアップを準備しておけば、これは単に2、3のインサートを実行するだけの問題である可能性があります。そうでない場合、これはかなり複雑になる可能性があります。主キーと一意のインデックス値がすべてです。ある種のUUIDジェネレーターを使用するか、MySQLのauto_increment_incrementおよびauto_increment_offset設定を使用して、各サーバーで主キー値が一意として生成される場合、挿入する必要のある古いマスターからのデータが主キーまたは一意になることはありません。キーが新しいマスターのデータと競合しています。それ以外の場合は、古いマスターのデータを手動で変更して、正しく挿入できるようにする必要があります。複雑に聞こえるので、例を見てみましょう。
マスターであるノードAにauto_incrementを使用して行を挿入するとします。簡単にするために、単一の行のみに焦点を当てます。 「id」列と「value」列があります。
特に設定せずに挿入すると、以下のようなエントリが表示されます:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’それらはスレーブに複製されます(B)。スプリットブレインが発生し、新旧両方のマスターで書き込みが実行される場合、次のような状況になります。
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’ご覧のとおり、IDが1004、1005、1006のレコードをノードAから単純にダンプして、ノードBに保存する方法はありません。これは、主キーエントリが重複してしまうためです。実行する必要があるのは、挿入される行のid列の値を、テーブルのid列の最大値よりも大きい値に変更することです。これが単一行に必要なすべてです。複数のテーブルが関係するより複雑な関係の場合、複数の場所で変更を加える必要がある場合があります。
一方、この潜在的な問題を予測し、ノードAに奇数IDを格納し、ノードBに偶数IDを格納するようにノードを構成した場合、問題の解決ははるかに簡単でした。
ノードAは、auto_increment_offset=1およびauto_increment_increment=2
で構成されました。ノードBは、auto_increment_offset=2およびauto_increment_increment=2
で構成されました。スプリットブレインの前のノードAでのデータの外観は次のとおりです。
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’スプリットブレインが発生すると、以下のようになります。
ノードA:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’ノードB:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’これで、欠落しているデータをノードAから簡単にコピーできます:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’そして、それをノードBにロードして、最終的に次のデータセットを作成します。
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’確かに、行は元の順序ではありませんが、これは問題ないはずです。最悪のシナリオでは、クエリの「値」列で並べ替える必要があり、並べ替えを高速化するためにインデックスを追加する必要があります。
ここで、数百または数千の行と高度に正規化されたテーブル構造を想像してください。1つの行を復元するには、追加のテーブルでそれらのいくつかを復元する必要がある場合があります。関連するすべての行でIDを変更する必要があり(保護設定が設定されていないため)、これはすべて手作業であるため、これは最善の状況ではないことが想像できます。回復には時間がかかり、これはエラーが発生しやすいプロセスです。幸い、最初に説明したように、スプリットブレインがシステムに影響を与える可能性を最小限に抑えるか、ノードを同期するために実行する必要のある作業を減らす手段があります。必ずそれらを使用し、準備をしてください。