誰かが誤ってデータベースの一部を削除しました。誰かがDELETEクエリにWHERE句を含めるのを忘れたか、間違ったテーブルを削除しました。そのようなことが起こる可能性があり、起こるでしょう、それは避けられない人間です。しかし、その影響は悲惨なものになる可能性があります。このような状況から身を守るために何ができますか?また、どのようにしてデータを回復できますか?このブログ投稿では、データ損失の最も一般的なケースのいくつかと、それらから回復できるように自分で準備する方法について説明します。
準備
スムーズな回復を確実にするためにあなたがしなければならないことがあります。それらを見ていきましょう。これは「1つ選ぶ」状況ではないことに注意してください。理想的には、以下で説明するすべての対策を実装します。
バックアップ
あなたはバックアップを持っている必要があります、それから逃れることはありません。バックアップファイルをテストする必要があります。バックアップをテストしない限り、バックアップが適切かどうか、また復元できるかどうかはわかりません。災害復旧の場合、データセンター全体が使用できなくなった場合に備えて、バックアップのコピーをデータセンターの外部のどこかに保持する必要があります。リカバリを高速化するには、データベースノードにもバックアップのコピーを保持しておくと非常に便利です。データセットが大きい場合は、ネットワークを介してバックアップサーバーから復元するデータベースノードにデータセットをコピーすると、かなりの時間がかかる場合があります。最新のバックアップをローカルに保持すると、リカバリ時間が大幅に改善される可能性があります。
論理バックアップ
ほとんどの場合、最初のバックアップは物理バックアップになります。 MySQLまたはMariaDBの場合、xtrabackupまたはある種のファイルシステムスナップショットのようなものになります。このようなバックアップは、データセット全体を復元したり、新しいノードをプロビジョニングしたりするのに最適です。ただし、データのサブセットを削除する場合は、かなりのオーバーヘッドが発生します。まず、すべてのデータを復元することはできません。そうしないと、バックアップの作成後に発生したすべての変更が上書きされます。探しているのは、データのサブセットのみを復元する機能であり、誤って削除された行のみを復元する機能です。物理バックアップでこれを行うには、別のホストに復元し、削除された行を見つけてダンプしてから、運用クラスターに復元する必要があります。ほんの一握りの行を回復するためだけに数百ギガバイトのデータをコピーして復元することは、間違いなくかなりのオーバーヘッドと呼ばれるものです。これを回避するには、論理バックアップを使用できます。物理データを保存する代わりに、このようなバックアップはデータをテキスト形式で保存します。これにより、削除された正確なデータを簡単に見つけることができ、本番クラスターに直接復元できます。さらに簡単にするために、このような論理バックアップを部分的に分割し、すべてのテーブルを個別のファイルにバックアップすることもできます。データセットが大きい場合は、1つの巨大なテキストファイルを可能な限り分割するのが理にかなっています。これによりバックアップの一貫性が失われますが、ほとんどの場合、これは問題ではありません。データセット全体を一貫性のある状態に復元する必要がある場合は、物理バックアップを使用します。これは、この点ではるかに高速です。データのサブセットのみを復元する必要がある場合、一貫性の要件はそれほど厳しくありません。
ポイントインタイムリカバリ
バックアップはほんの始まりに過ぎません。バックアップが作成された時点までデータを復元できますが、ほとんどの場合、その時点以降にデータが削除されています。最新のバックアップから欠落しているデータを復元するだけで、バックアップ後に変更されたデータが失われる可能性があります。これを回避するには、ポイントインタイムリカバリを実装する必要があります。 MySQLの場合、基本的には、バックアップの瞬間とデータ損失イベントの間に発生したすべての変更を再生するためにバイナリログを使用する必要があることを意味します。以下のスクリーンショットは、ClusterControlがそれをどのように支援できるかを示しています。
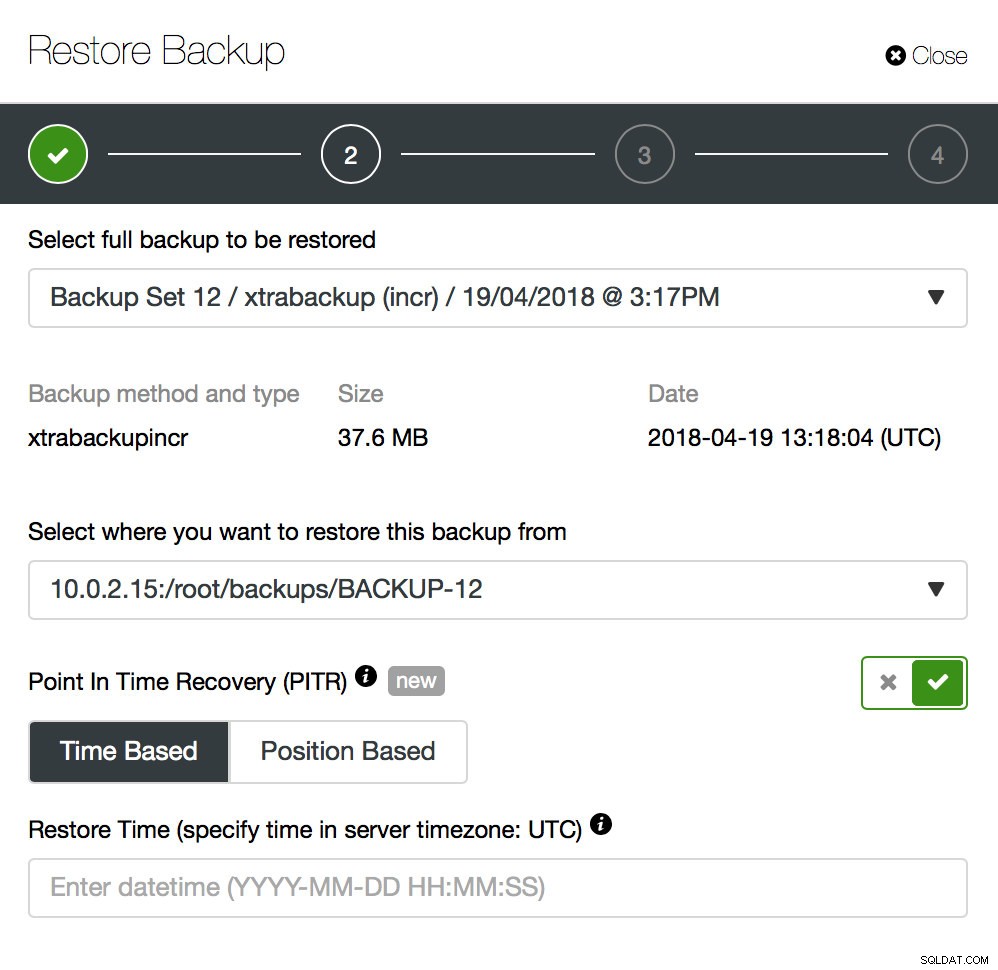
あなたがしなければならないことは、データが失われる直前までこのバックアップを復元することです。本番クラスターで変更を加えないようにするには、別のホストで復元する必要があります。バックアップを復元したら、そのホストにログインし、不足しているデータを見つけてダンプし、本番クラスターに復元できます。
遅延スレーブ
上記で説明したすべての方法には、共通の問題点が1つあります。それは、データの復元に時間がかかることです。すべてのデータを復元してから、対象の部分のみをダンプしようとすると、さらに時間がかかる場合があります。論理バックアップがあり、復元するデータにすばやくドリルダウンできる場合は、時間がかからない場合がありますが、これは決して簡単な作業ではありません。大きなテキストファイルでまだ数行を見つける必要があります。サイズが大きいほど、タスクは複雑になります。ファイルのサイズが非常に大きいと、すべてのアクションが遅くなることがあります。これらの問題を回避する1つの方法は、遅延スレーブを使用することです。スレーブは通常、マスターの最新情報を入手しようとしますが、マスターからの距離を保つように構成することもできます。以下のスクリーンショットでは、ClusterControlを使用してそのようなスレーブをデプロイする方法を確認できます。
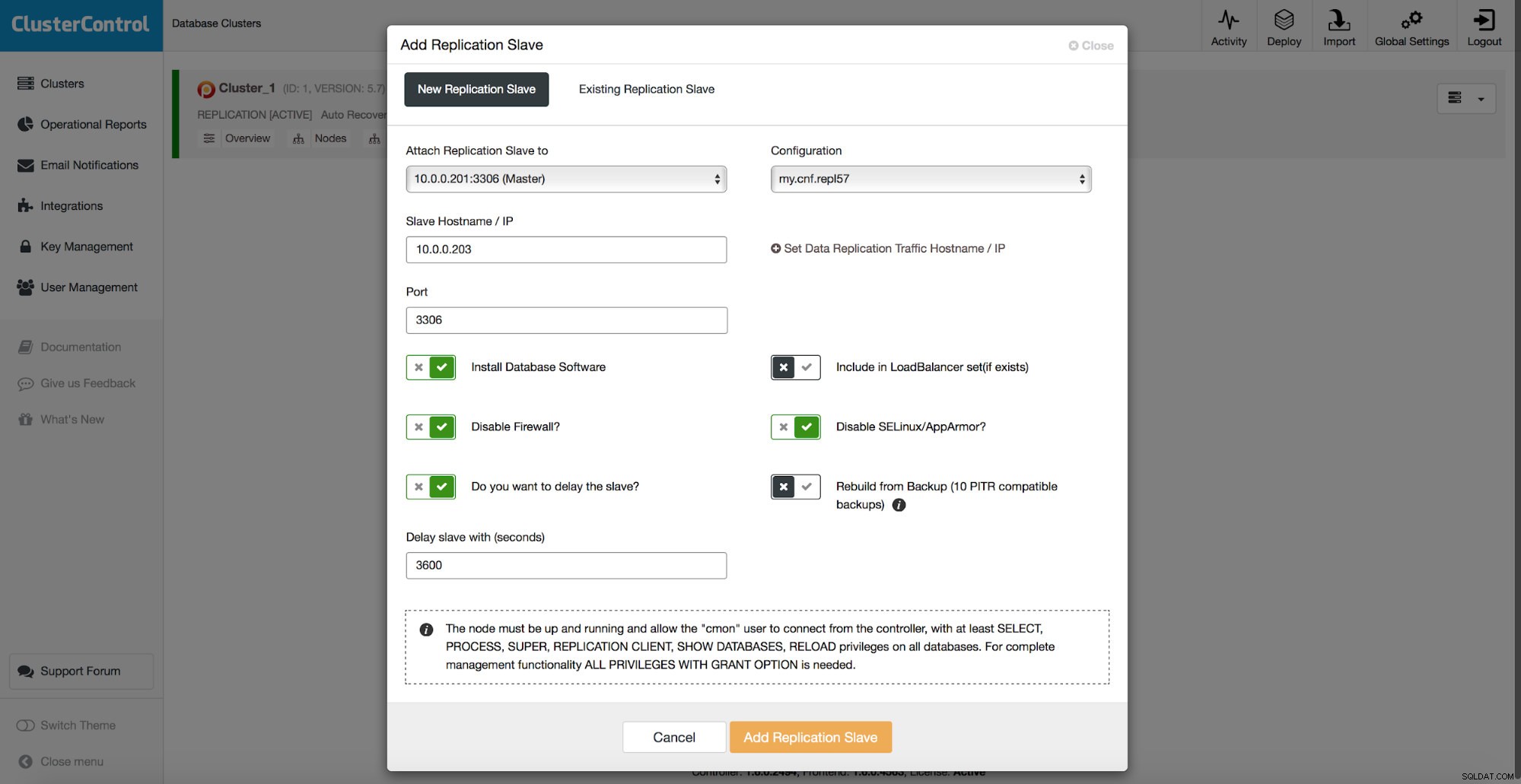
つまり、ここでは、レプリケーションスレーブをデータベースのセットアップに追加し、遅延するように構成するオプションがあります。上のスクリーンショットでは、スレーブは3600秒(1時間)遅れます。これにより、そのスレーブを使用して、データの削除から最大1時間で削除されたデータを回復できます。バックアップを復元する必要はありません。不足しているデータに対してmysqldumpまたはSELECT...INTO OUTFILEを実行するだけで十分であり、本番クラスターで復元するデータを取得できます。
データの復元
このセクションでは、偶発的なデータ削除の例と、それらから回復する方法について説明します。完全なデータ損失からの回復について説明し、物理的および論理的なバックアップを使用する場合の部分的なデータ損失からの回復方法も示します。最後に、セットアップで遅延スレーブがある場合に誤って削除された行を復元する方法を示します。
完全なデータ損失
偶発的な「rm-rf」または「DROPSCHEMAmyonlyschema;」が実行され、データがまったくない状態になりました。 MySQLデータディレクトリ以外のファイルも削除した場合は、ホストを再プロビジョニングする必要があります。物事を単純にするために、MySQLのみが影響を受けていると仮定します。遅延スレーブがある場合とない場合の2つのケースを考えてみましょう。
遅延スレーブなし
この場合、私たちができることは、最後の物理バックアップを復元することだけです。すべてのデータが削除されているため、データがないためアクティビティがないため、データが失われた後に発生したアクティビティについて心配する必要はありません。バックアップが行われた後に発生したアクティビティについて心配する必要があります。これは、ポイントインタイム復元を実行する必要があることを意味します。もちろん、バックアップからデータを復元するよりも時間がかかります。すべてのデータを復元するよりもデータベースをすばやく起動することが重要な場合は、バックアップを復元して問題なく使用することもできます。
まず、復元するサーバーのバイナリログにまだアクセスできる場合は、それらをPITRに使用できます。まず、バイナリログの関連部分をテキストファイルに変換して、さらに調査します。 13:00:00以降にデータが失われたことがわかっています。まず、調査する必要のあるbinlogファイルを確認しましょう。
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016ご覧のとおり、最後のbinlogファイルに関心があります。
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.out完了したら、このファイルの内容を見てみましょう。 vimで「ドロップスキーマ」を検索します。ファイルの関連部分は次のとおりです。
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
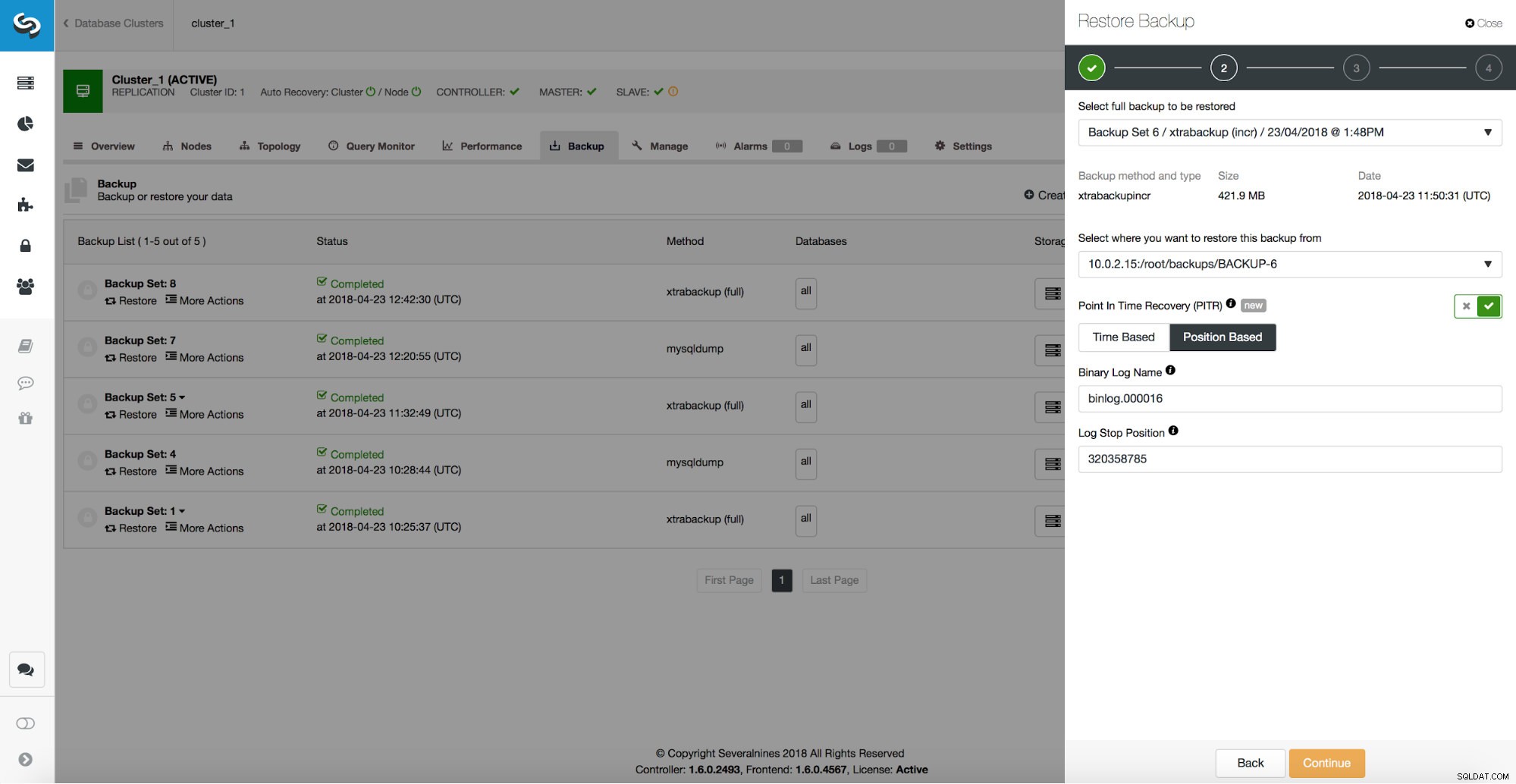
/*!*/;ご覧のとおり、320358785の位置まで復元したいと考えています。このデータをClusterControlUIに渡すことができます。
遅延スレーブ
遅延スレーブがあり、そのホストがすべてのトラフィックを処理するのに十分である場合、それを使用してマスターに昇格させることができます。ただし、最初に、データが失われるまで、古いマスターに追いついていることを確認する必要があります。ここでは、CLIを使用してそれを実現します。まず、データ損失が発生した位置を特定する必要があります。次に、スレーブを停止し、データ損失イベントまで実行します。前のセクションで、バイナリログを調べることによって正しい位置を取得する方法を示しました。その位置(binlog.000016、位置320358785)を使用するか、マルチスレッドスレーブを使用する場合は、データ損失イベントのGTID(52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415)を使用し、クエリを最大で再生する必要があります。そのGTID。
まず、スレーブを停止して遅延を無効にしましょう:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)次に、指定されたバイナリログ位置まで起動できます。
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)GTIDを使用する場合、コマンドは異なって見えます:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)レプリケーションが停止したら(つまり、要求したすべてのイベントが実行されたら)、ホストに不足しているデータが含まれていることを確認する必要があります。その場合は、マスターに昇格させてから、新しいマスターをデータのソースとして使用して他のホストを再構築できます。
これが常に最良のオプションであるとは限りません。すべては、スレーブの遅延に依存します。スレーブが数時間遅延した場合、特に書き込みトラフィックが環境内で重い場合は、スレーブが追いつくのを待つのは意味がない場合があります。このような場合、物理バックアップを使用してホストを再構築する方が速い可能性があります。一方、トラフィックの量がかなり少ない場合、これは、残りのノードがバックグラウンドで再構築されている間に、問題を実際にすばやく修正し、新しいマスターを昇格させ、トラフィックの処理を開始するための優れた方法になる可能性があります。
部分的なデータ損失-物理バックアップ
部分的なデータ損失の場合、物理バックアップは非効率になる可能性がありますが、これらは最も一般的なタイプのバックアップであるため、部分的な復元にそれらを使用する方法を知ることは非常に重要です。最初のステップは常に、データ損失イベントの前の時点までのバックアップを復元することです。別のホストに復元することも非常に重要です。 ClusterControlは物理バックアップにxtrabackupを使用するため、その使用方法を示します。次の誤ったクエリを実行したと仮定します:
DELETE FROM sbtest1 WHERE id < 23146;1つの行(WHERE句の「=」)だけを削除したかったので、代わりにそれらの束(WHERE句の<)を削除しました。バイナリログを見て、問題が発生した位置を見つけましょう。その位置を使用して、バックアップを復元します。
mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.outそれでは、出力ファイルを見て、そこに何が見つかるかを見てみましょう。行ベースのレプリケーションを使用しているため、実行された正確なSQLは表示されません。代わりに(mysqlbinlogに--verboseフラグを使用する限り)、次のようなイベントが表示されます。
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'ご覧のとおり、MySQLは非常に正確なWHERE条件を使用して削除する行を識別します。人間が読めるコメント「@1」、「@ 2」の不思議な記号は、「最初の列」、「2番目の列」を意味します。最初の列が「id」であることがわかっています。これは私たちが関心を持っているものです。「sbtest1」テーブルで大きなDELETEイベントを見つける必要があります。続くコメントには、IDが1、IDが「2」、「3」のように、すべて「23145」のIDまで記載する必要があります。すべてを単一のトランザクションで実行する必要があります(バイナリログの単一のイベント)。 「less」を使用して出力を分析したところ、次のことがわかりました。
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'これらのコメントが添付されているイベントは、次の場所で開始されました:
#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826したがって、位置29600687の前のコミットまでのバックアップを復元したいと思います。それを今すぐ実行しましょう。そのために外部サーバーを使用します。バックアップをその位置まで復元し、復元サーバーを稼働させたままにして、後で不足しているデータを抽出できるようにします。
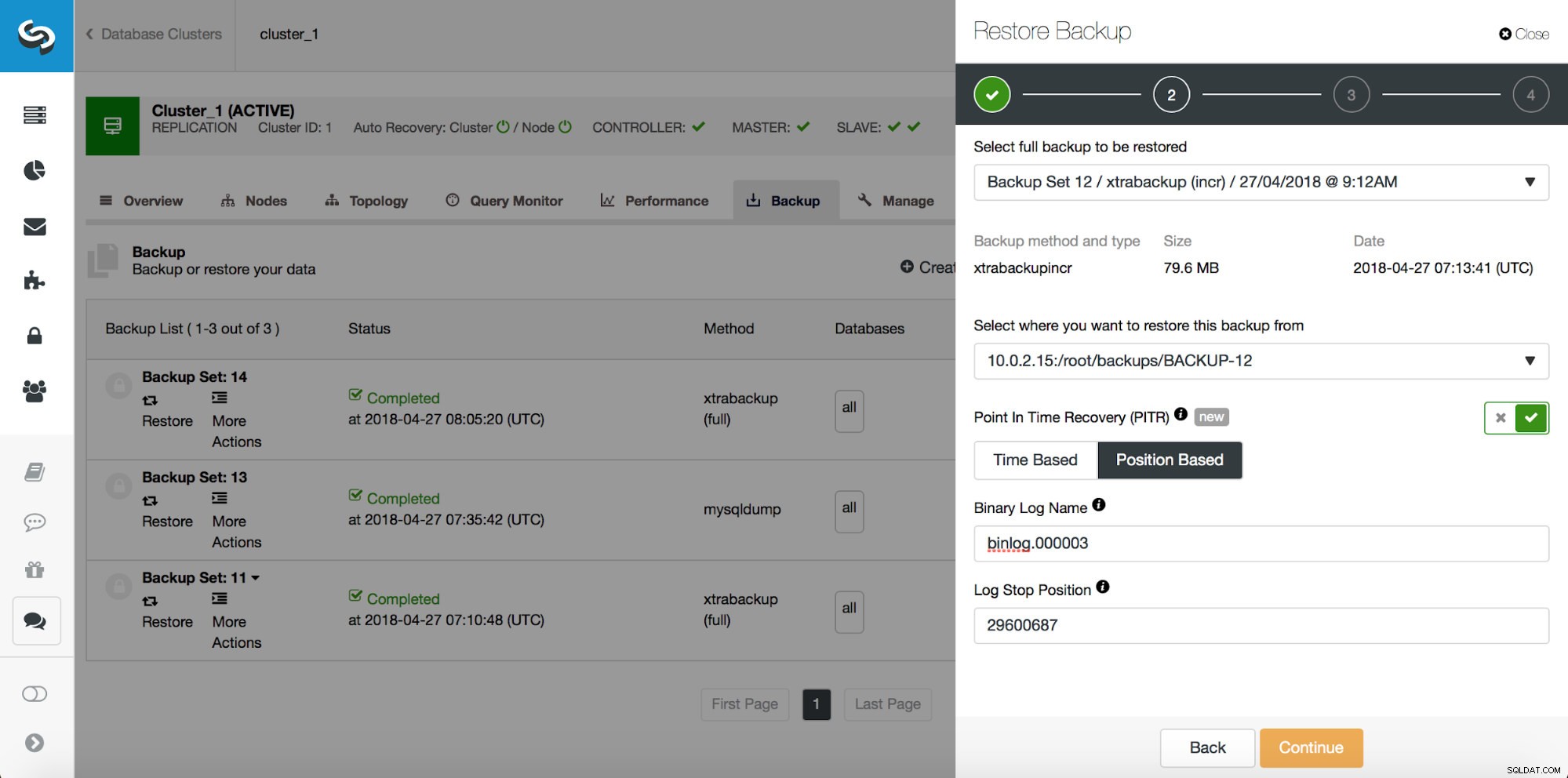
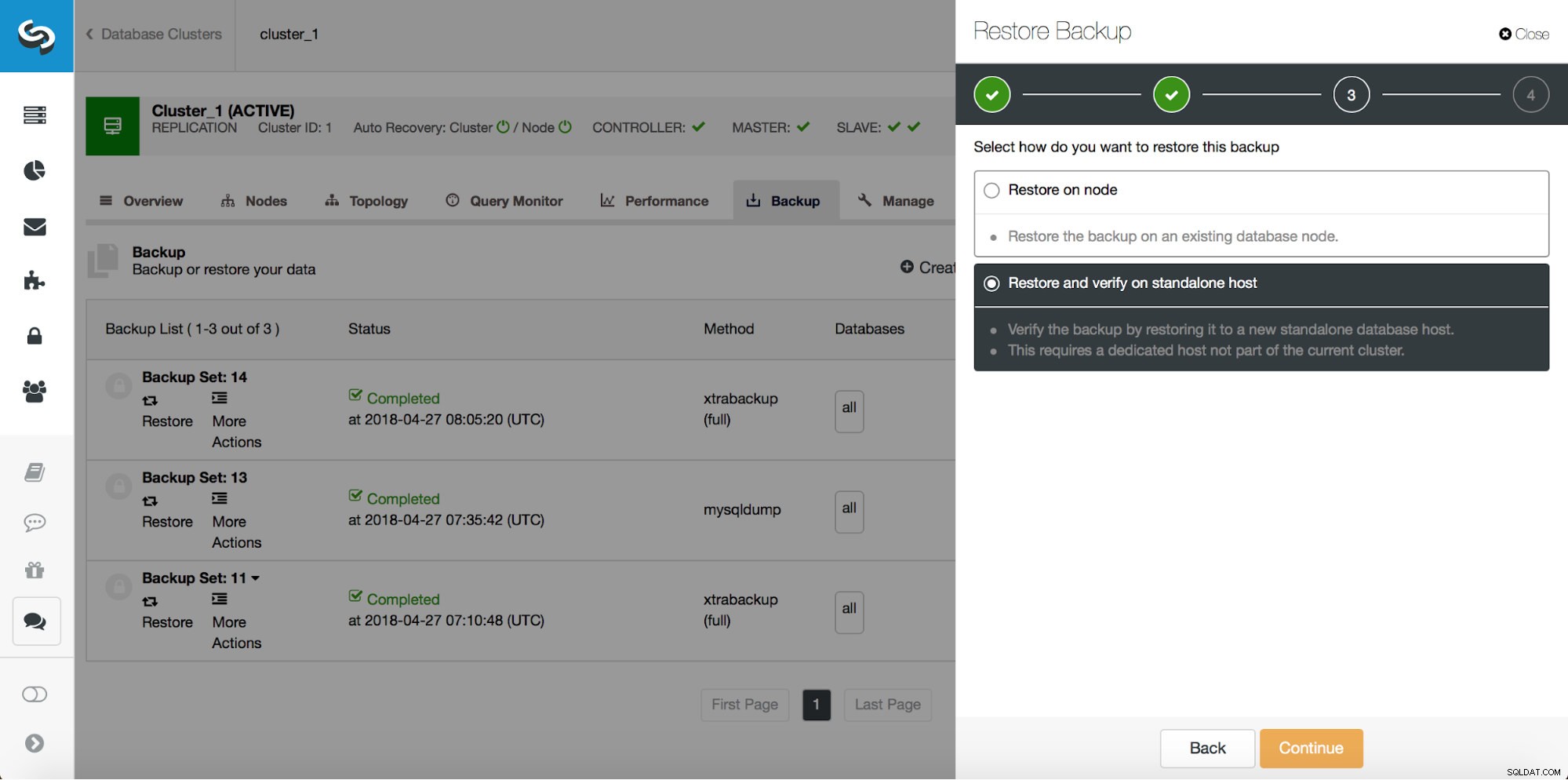
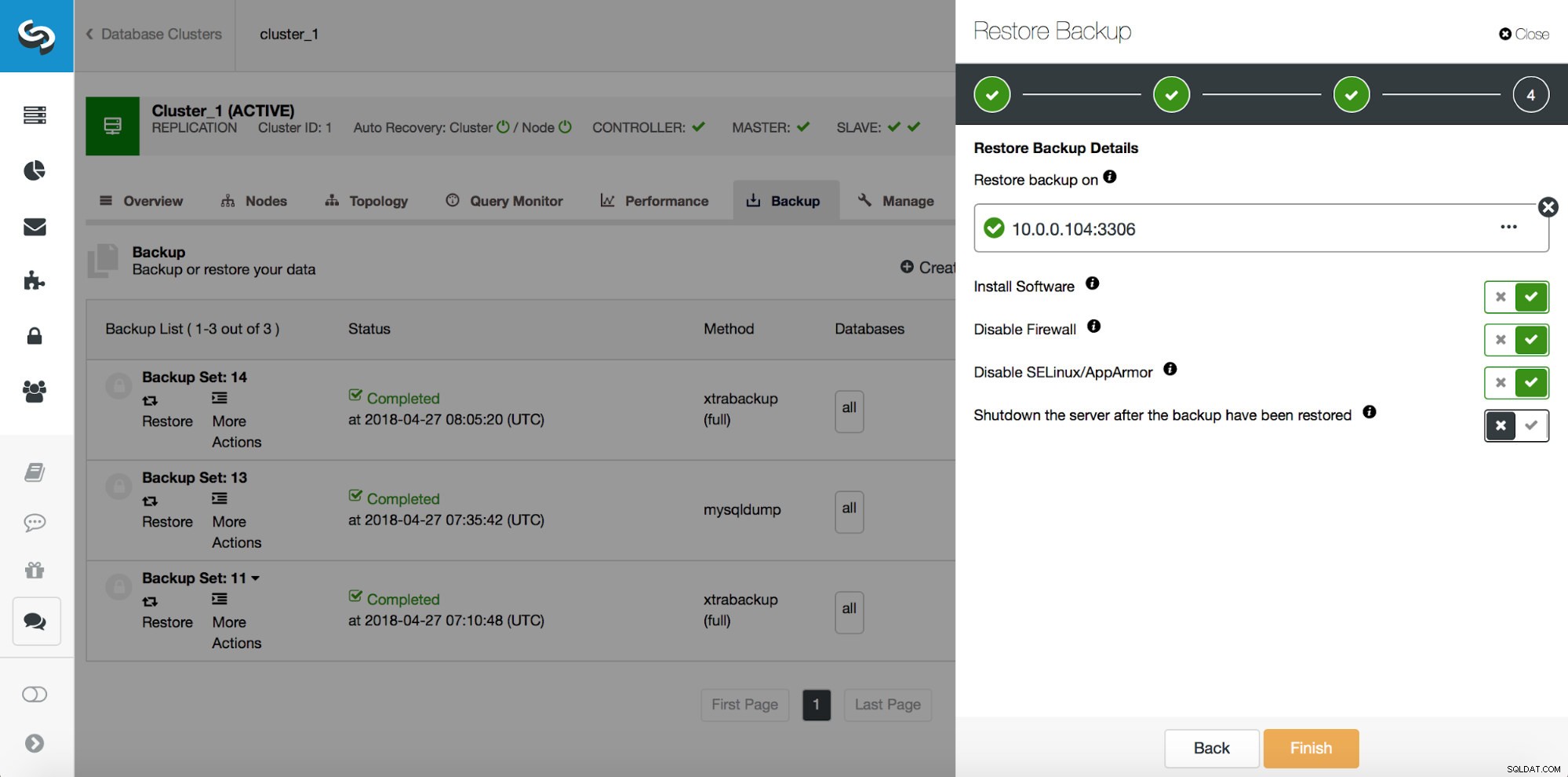
復元が完了したら、データが復元されたことを確認しましょう。
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)いいね。これで、このデータをファイルに抽出して、マスターにロードし直すことができます。
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement何かが正しくありません。これは、サーバーが特定の場所でのみファイルを書き込めるように構成されているためです。これはすべてセキュリティに関するものであり、ユーザーが好きな場所にコンテンツを保存できないようにする必要があります。ファイルを保存できる場所を確認しましょう:
mysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)では、もう一度試してみましょう:
mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)今でははるかに良く見えます。データをマスターにコピーしましょう:
example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00次に、不足している行をマスターにロードして、成功したかどうかをテストします。
mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)以上で、不足しているデータを復元しました。
部分的なデータ損失-論理バックアップ
前のセクションでは、物理バックアップと外部サーバーを使用して失われたデータを復元しました。論理バックアップを作成した場合はどうなりますか?見てみましょう。まず、論理バックアップがあることを確認しましょう:
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzはい、あります。それでは、解凍します。
example@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sql調べると、データが複数値のINSERT形式で格納されていることがわかります。例:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')ここで行う必要があるのは、テーブルが配置されている場所を特定し、次に、関心のある行が格納されている場所を特定することです。まず、mysqldumpパターン(テーブルの削除、新しいパターンの作成、インデックスの無効化、データの挿入)を理解して、「sbtest1」テーブルのCREATETABLEステートメントが含まれている行を特定しましょう。
example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (ここで、試行錯誤の方法を使用して、行を探す場所を見つける必要があります。思いついた最後のコマンドをお見せします。全体の秘訣は、sedを使用してさまざまな範囲の行を印刷してから、最新の行に検索対象に近いが、検索対象よりも遅い行が含まれているかどうかを確認することです。以下のコマンドでは、971(CREATE TABLE)と993の間の行を探します。また、ファイルの残りの部分は重要ではないため、行994に達したらsedに終了するように要求します。
example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | less出力は次のようになります:
INSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),これは、行範囲(IDが23145の行まで)が近いことを意味します。次に、ファイルを手動でクリーニングすることがすべてです。復元する必要がある最初の行から開始する必要があります:
INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')そして、復元する最後の行になります:
(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');不要なデータの一部をトリミングする必要がありましたが(複数行の挿入です)、このすべての後に、マスターにロードして戻すことができるファイルができました。
example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.最後に、最後のチェック:
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)すべてが順調で、データが復元されました。
部分的なデータ損失、遅延スレーブ
この場合、プロセス全体を実行することはありません。バイナリログでデータ損失イベントの位置を特定する方法については、すでに説明しました。また、遅延スレーブを停止し、データ損失イベントの前の時点までレプリケーションを再開する方法についても説明しました。また、SELECTINTOOUTFILEおよびLOADDATAINFILEを使用して、外部サーバーからデータをエクスポートし、マスターにロードする方法についても説明しました。必要なのはそれだけです。データが遅延スレーブ上にある限り、データを停止する必要があります。次に、データ損失イベントの前の位置を特定し、その時点までスレーブを起動する必要があります。これが完了したら、遅延スレーブを使用して削除されたデータを抽出し、ファイルをマスターにコピーしてロードし、データを復元します。 。
結論
失われたデータを復元するのは楽しいことではありませんが、このブログで行った手順に従うと、失われたデータを復元できる可能性が高くなります。