高可用性とは、システムが機能し、ビジネスニーズに応じて応答している時間の割合が高いことです。本番データベースシステムの場合、通常、100%近くに保つことが最優先事項です。データベースクラスターを構築して、すべての単一障害点を排除します。インスタンスが使用できなくなった場合、別のノードがワークロードを引き受け、そこから続行できるようにする必要があります。完璧な世界では、データベースクラスターがシステムの可用性の問題をすべて解決します。残念ながら、すべてが紙の上では見栄えがするかもしれませんが、現実はしばしば異なります。では、どこで問題が発生する可能性がありますか?
トランザクションデータベースシステムには、高度なストレージエンジンが付属しています。複数のノード間でデータの一貫性を保つと、このタスクが非常に難しくなります。クラスタリングにより、ネットワークと基盤となるインフラストラクチャに大きく依存する多くの新しい変数が導入されます。単一ノードで正常に実行されていたスタンドアロンデータベースインスタンスが、クラスタ環境で突然パフォーマンスが低下することは珍しくありません。
クラスターの可用性に影響を与える可能性のある多くの事柄の中で、レイテンシーの問題が重要な役割を果たします。しかし、待ち時間はどのくらいですか?ネットワークにのみ関連していますか?
「レイテンシー」という用語は、実際にはデータの処理で発生するいくつかの種類の遅延を指します。情報がステージから別のステージに移動するのにかかる時間です。
このブログ投稿では、MySQLとMariaDBの2つの主要な高可用性ソリューションと、それぞれがレイテンシーの問題によってどのように影響を受けるかについて説明します。
記事の最後に、最新のロードバランサーを見て、いくつかのタイプのレイテンシーの問題に対処するのにどのように役立つかについて説明します。
前回の記事で、私の同僚のKrzysztofKsiążekは、「MySQLまたはMariaDB用のHAソリューションを作成する際の信頼性の低いネットワークへの対処」について書いています。本番環境に対応したHAアーキテクチャを設計し、ここで説明する問題のいくつかを回避するのに役立つヒントが見つかります。
高可用性のためのマスタースレーブレプリケーション。
MySQLマスタースレーブレプリケーションは、おそらく地球上で最も人気のあるデータベースクラスタータイプです。マスター/スレーブレプリケーションクラスターの実行中に監視する主なものの1つは、スレーブラグです。アプリケーションの要件とデータベースの利用方法によっては、レプリケーションの待ち時間(スレーブラグ)によって、データをスレーブノードから読み取ることができるかどうかが決まる場合があります。マスターでコミットされたが非同期スレーブでまだ利用できないデータは、スレーブの状態が古いことを意味します。スレーブからの読み取りに問題がある場合は、マスターに移動する必要があり、それがアプリケーションのパフォーマンスに影響を与える可能性があります。最悪のシナリオでは、システムがマスター上のすべてのワークロードを処理できなくなります。
スレーブラグと古いデータ
マスタースレーブレプリケーションのステータスを確認するには、以下のコマンドから開始する必要があります。
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)上記の情報を使用して、全体的なレプリケーションの待機時間がどれだけ良好かを判断できます。 「Seconds_Behind_Master」に表示される値が低いほど、レプリケーションのデータ転送速度が向上します。
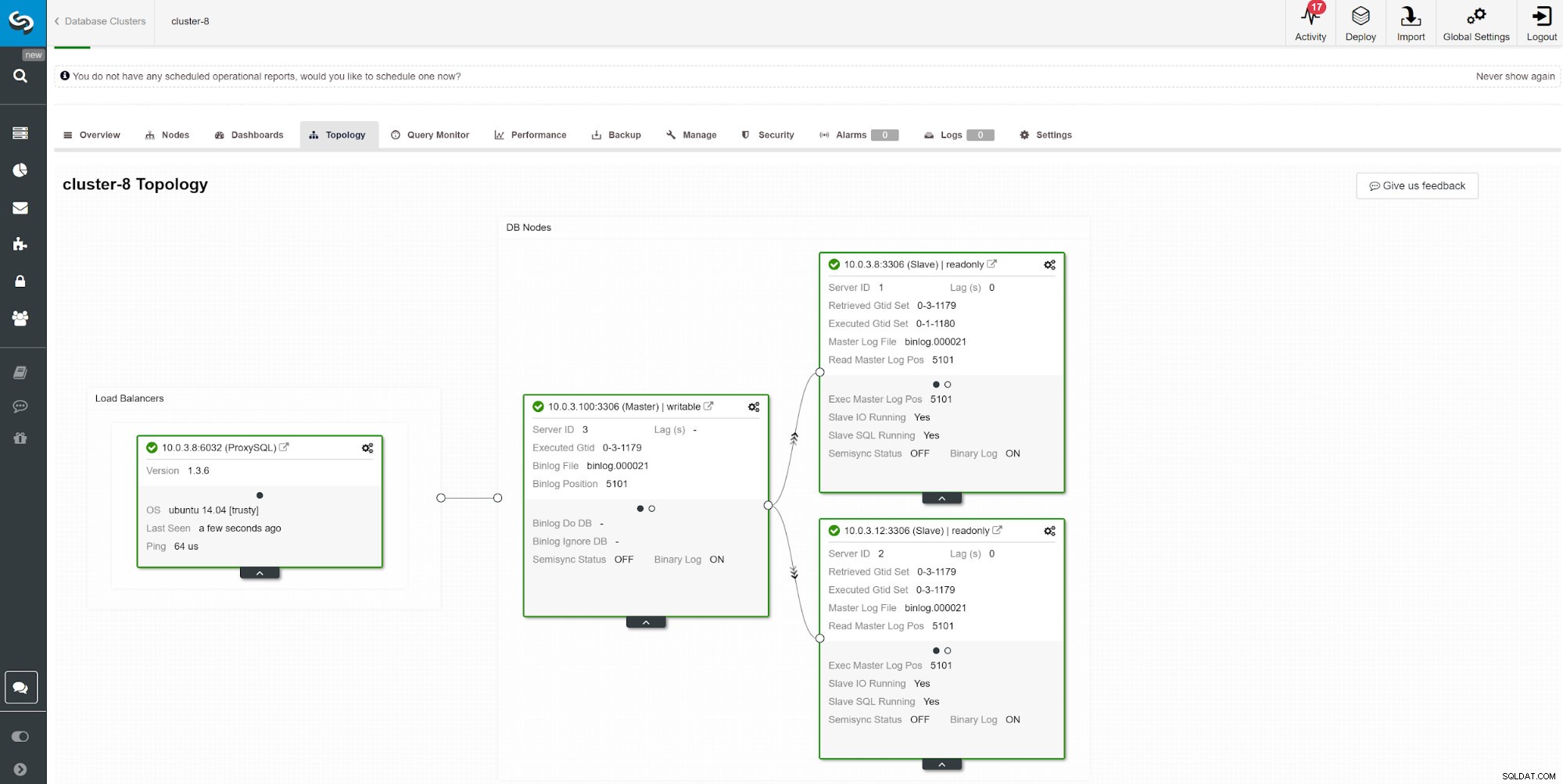 スレーブラグを監視する別の方法は、ClusterControlレプリケーション監視を使用することです。このスクリーンショットでは、ProxySQLを使用した非同期のマスタースレーブ(2x)クラスターのレプリケーションステータスを確認できます。
スレーブラグを監視する別の方法は、ClusterControlレプリケーション監視を使用することです。このスクリーンショットでは、ProxySQLを使用した非同期のマスタースレーブ(2x)クラスターのレプリケーションステータスを確認できます。 レプリケーション時間に影響を与える可能性のあるものはたくさんあります。最も明白なのは、ネットワークスループットと転送できるデータ量です。 MySQLには、レプリケーションプロセスを最適化するための複数の構成オプションが付属しています。レプリケーションに関連する重要なパラメータは次のとおりです。
- 並列適用
- 論理クロックアルゴリズム
- 圧縮
- 選択的なマスター/スレーブレプリケーション
- レプリケーションモード
並列適用
並列プロセスの適用を有効にしてレプリケーションの調整を開始することは珍しくありません。その理由は、デフォルトでは、MySQLはシーケンシャルバイナリログ適用を採用しており、一般的なデータベースサーバーには使用するCPUがいくつか付属しています。
シーケンシャルログの適用を回避するために、MariaDBとMySQLの両方が並列レプリケーションを提供しています。実装はベンダーやバージョンごとに異なる場合があります。例えば。 MySQL 5.6は、スキーマがクエリを分離している限り、並列レプリケーションを提供しますが、MariaDB(バージョン10.0以降)とMySQL 5.7は、どちらもスキーマ間の並列レプリケーションを処理できます。ベンダーやバージョンによって制限や機能が異なるため、常にドキュメントを確認してください。
書き込みが多い場合、並列スレーブスレッドを介してクエリを実行すると、レプリケーションストリームが高速化される可能性があります。ただし、そうでない場合は、従来のシングルスレッドレプリケーションに固執するのが最善です。並列処理を有効にするには、slave_parallel_workersをプロセスに関与させるCPUスレッドの数に変更します。使用可能なCPUスレッドの数よりも小さい値を維持することをお勧めします。
並列レプリケーションは、グループコミットで最適に機能します。グループコミットが発生しているかどうかを確認するには、次のクエリを実行します。
show global status like 'binlog_%commits';これら2つの値の比率が大きいほど良いです。
論理クロック
slave_parallel_type =LOGICAL_CLOCKは、Lamportクロックアルゴリズムの実装です。マルチスレッドスレーブを使用する場合、この変数は、スレーブで並列実行できるトランザクションを決定するために使用されるメソッドを指定します。この変数は、マルチスレッドが有効になっていないスレーブには影響しないため、slave_parallel_workersが0より大きく設定されていることを確認してください。
MariaDBユーザーは、バージョン10.1.3で導入された楽観的モードも確認する必要があります。これにより、より良い結果が得られる可能性もあります。
GTID
MariaDBには、GTIDの独自の実装が付属しています。 MariaDBのシーケンスは、ドメイン、サーバー、トランザクションで構成されています。ドメインにより、個別のIDを使用したマルチソースレプリケーションが可能になります。さまざまなドメインIDを使用して、データの一部を順不同で(並行して)複製できます。アプリケーションに問題がない限り、これによりレプリケーションの待ち時間を短縮できます。
同様の手法がMySQL5.7にも当てはまり、マルチソースマスターと独立したレプリケーションチャネルも使用できます。
圧縮
CPUパワーは時間の経過とともに安価になっているため、binlog圧縮に使用することは、多くのデータベース環境に適したオプションになる可能性があります。 slave_compressed_protocolパラメーターは、マスターとスレーブの両方が圧縮をサポートしている場合に圧縮を使用するようにMySQLに指示します。デフォルトでは、このパラメータは無効になっています。
MariaDB 10.2.3以降、バイナリログで選択したイベントをオプションで圧縮して、ネットワーク転送を保存できます。
複製フォーマット
MySQLはいくつかのレプリケーションモードを提供します。適切なレプリケーション形式を選択すると、クラスターノード間でデータを渡す時間を最小限に抑えることができます。
高可用性のためのマルチマスターレプリケーション
一部のアプリケーションは、古いデータを操作する余裕がありません。
このような場合、同期レプリケーションを使用してノード間で一貫性を確保することができます。データの同期を維持するには、追加のプラグインが必要です。そのための市場で最高のソリューションは、GaleraClusterです。
GaleraクラスターにはwsrepAPIが付属しており、すべてのノードにトランザクションを送信し、クラスター全体の順序に従ってそれらを実行します。これにより、ノードがアプライヤーキューからすべての書き込みセットを適用するまで、後続のクエリの実行がブロックされます。一貫性を保つための優れたソリューションですが、アーキテクチャ上の制限に直面する可能性があります。一般的なレイテンシの問題は、以下に関連している可能性があります:
- クラスター内で最も遅いノード
- 水平スケーリングおよび書き込み操作
- 地理的に配置されたクラスター
- ハイピン
- トランザクションサイズ
クラスター内で最も遅いノード
設計上、クラスターの書き込みパフォーマンスは、クラスター内で最も遅いノードのパフォーマンスより高くすることはできません。マシンリソースをチェックしてクラスターレビューを開始し、構成ファイルを検証して、すべてが同じパフォーマンス設定で実行されることを確認します。
並列化
並列スレッドはパフォーマンスの向上を保証するものではありませんが、新しいノードとクラスターの同期を高速化する可能性があります。ステータスwsrep_cert_deps_distanceは、可能な並列化の程度を示します。これは、並列に適用できる可能性のある最高と最低のseqno値の間の平均距離の値です。 wsrep_cert_deps_distanceステータス変数を使用して、可能なスレーブスレッドの最大数を決定できます。
水平スケーリング
クラスタにノードを追加することで、失敗する可能性のあるポイントが少なくなります。ただし、情報はコミットされるまで複数のインスタンスにまたがる必要があります。これにより、応答時間が倍増します。スケーラブルな書き込みが必要な場合は、シャーディングに基づくアーキテクチャを検討してください。優れたソリューションは、スパイダーストレージエンジンです。
場合によっては、クラスターノード間で共有される情報を減らすために、一度に1人のライターを使用することを検討できます。ロードバランサーを使用している間は、比較的簡単に実装できます。これを手動で行う場合は、ライターノードがダウンしたときにDNS値を変更する手順があることを確認してください。
地理的に配置されたクラスター
Galera Clusterは同期していますが、GaleraClusterをデータセンター全体に展開することは可能です。 MySQL Cluster(NDB)のような同期レプリケーションは、2フェーズコミットを実装します。この場合、メッセージは「準備」フェーズでクラスター内のすべてのノードに送信され、別のメッセージセットは「コミット」フェーズで送信されます。このアプローチは、ノード間でメッセージを送信する際に遅延が発生するため、通常、地理的に異なるノードには適していません。
ハイピン
デフォルト設定のGaleraClusterは、高いネットワーク遅延を十分に処理しません。 ping時間が長いノードを持つネットワークがある場合は、evs.send_windowパラメーターとevs.user_send_windowパラメーターを変更することを検討してください。これらの変数は、一度にレプリケーションされるデータパケットの最大数を定義します。 WAN設定の場合、変数はデフォルト値の2よりもかなり高い値に設定できます。512に設定するのが一般的です。これらのパラメータはwsrep_provider_optionsの一部です。
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"トランザクションサイズ
Galera Clusterの実行中に考慮する必要があることの1つは、トランザクションのサイズです。トランザクションのサイズ、パフォーマンス、Galera認定プロセスのバランスを見つけることは、アプリケーションで見積もる必要があります。詳細については、AshrafSharifによるMySQLまたはMariaDBのGaleraClusterのパフォーマンスを向上させる方法の記事を参照してください。
ロードバランサーの因果整合性の読み取り
データ遅延の問題のリスクを最小限に抑えても、標準のMySQL非同期レプリケーションは一貫性を保証できません。アプリケーションがそこからデータを読み取っている間、データがまだスレーブに複製されていない可能性があります。同期レプリケーションはこの問題を解決できますが、アーキテクチャの制限があり、アプリケーションの要件に適合しない場合があります(集中的な一括書き込みなど)。では、それを克服する方法は?
古いデータの読み取りを回避するための最初のステップは、アプリケーションにレプリケーションの遅延を認識させることです。通常、アプリケーションコードでプログラムされます。幸い、GTID追跡に基づく適応型クエリルーティングをサポートする最新のデータベースロードバランサーがあります。最も人気のあるのはProxySQLとMaxscaleです。
ProxySQL 2.0
ProxySQL Binlog Readerを使用すると、ProxySQLは、すべてのMySQLサーバー、スレーブ、およびマスター自体で実行されたGTIDをリアルタイムで知ることができます。このおかげで、クライアントが因果整合性の読み取りを提供する必要のある読み取りを実行すると、ProxySQLはクエリを実行できるサーバーをすぐに認識します。何らかの理由で書き込みがまだどのスレーブでも実行されていない場合、ProxySQLはライターがマスターで実行されたことを認識し、そこに読み取りを送信します。
Maxscale 2.3
MariaDBは、Maxscale2.3.0でカジュアルリードを導入しました。動作方法はProxySQL2.0に似ています。基本的に、causal_readsが有効になっている場合、スレーブサーバーで実行される後続の読み取りは、レプリケーションの遅延が結果に影響を与えないように実行されます。設定された時間内にスレーブがマスターに追いつかなかった場合、クエリはマスターで再試行されます。