この設定を実現するための主な課題は、ネットワークのパーティション分割に関連する問題の可能性を減らす方法でデータベースを設計することです。解決策の1つは、通常の非同期(または半同期)レプリケーションの代わりにGaleraClusterを使用することです。このブログでは、このアプローチの長所と短所について説明します。これは、一連の2つのブログの最初の部分です。第2部では、地理的に分散したGalera Clusterを設計し、ClusterControlがそのような環境の展開にどのように役立つかを確認します。
地理分散クラスターの非同期レプリケーションではなく、Galeraクラスターを使用する理由
これは、多くの問題につながります。まず、WAN全体で複数の接続を確立する必要があります。これにより、遅延が増加し、プロキシが実行されている可能性のあるチェックが遅くなります。さらに、これにより、プロキシとデータベースに不要なオーバーヘッドが追加されます。ほとんどの場合、トラフィックをローカルデータベースノードにルーティングすることだけに関心があります。唯一の例外はマスターであり、このプロキシがローカルデータセンターにある部分だけでなくインフラストラクチャ全体を監視することを余儀なくされているためです。もちろん、プロキシを使用してSELECTのみをルーティングし、他の方法(DNSによって管理されるマスターの専用ホスト名)を使用してアプリケーションをマスターにポイントすることでこれを克服することができますが、これにより、不必要なレベルの複雑さと可動部分が追加されます。データの一貫性を失うことなく、複数のノードとネットワークの障害を処理する能力に深刻な影響を与える可能性があります。
Galera Clusterは、複数のライターをサポートできます。レイテンシーも要因です。Galeraクラスター内のすべてのノードがライトセットを認証するために調整および通信する必要があるため、レイテンシーが高すぎる場合にGaleraを使用しないことを決定する理由になることもあります。これはレプリケーションクラスターの問題でもあります。レプリケーションクラスターでは、レイテンシーはリモートデータセンターからの書き込みにのみ影響しますが、マスターが配置されているデータセンターからの接続は、レイテンシーの低いコミットの恩恵を受けます。
MySQLレプリケーションでは、最悪のシナリオを念頭に置いて、アプリケーションが書き込みの遅延に問題がないことを確認する必要があります。マスターはいつでも変更でき、常にローカルノードに書き込むことを確信できません。
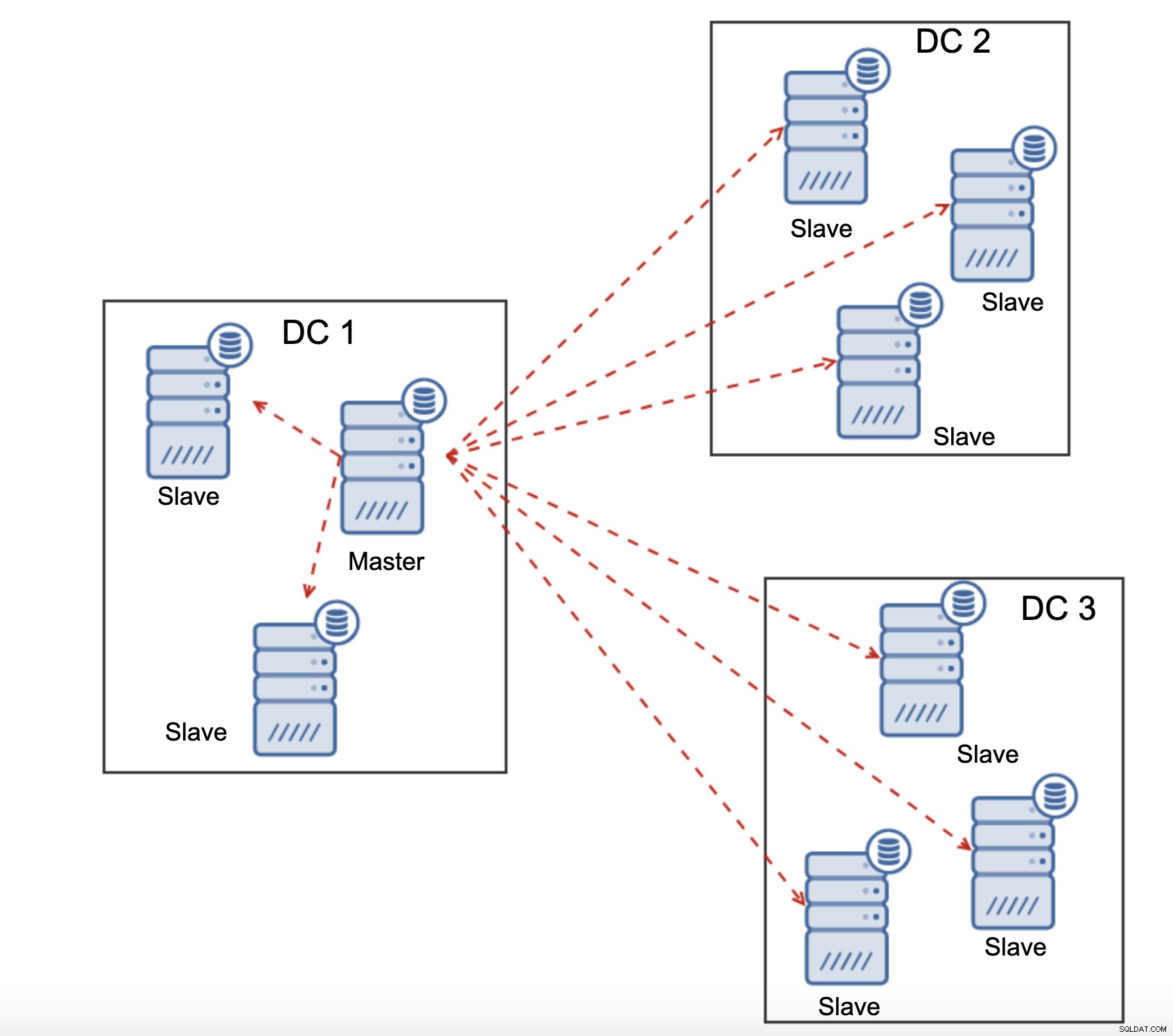
すべてのスレーブは、レプリケーショントラフィック全体(データ量)を受信する必要がありますWAN経由でリモートスレーブに送信する回数は、リモートスレーブを追加するたびに増加します。これにより、WANリンクが飽和状態になる可能性があります。特に、多くの変更を行い、WANリンクのスループットが低い場合はなおさらです。上の図からわかるように、3つのデータセンターとそれぞれに3つのノードがある場合、マスターはWAN接続を介して6倍のレプリケーショントラフィックを送信する必要があります。
Galeraクラスターでは、状況が少し異なります。手始めに、Galeraはフロー制御を使用してノードの同期を維持します。ノードの1つが遅れ始めた場合、クラスターの残りの部分に速度を落とし、追いつくように要求する機能があります。確かに、これによりクラスター全体のパフォーマンスが低下しますが、SELECTにスレーブを実際に使用できない場合よりも優れています。スレーブは時々遅れる傾向があるためです。このような場合、取得する結果は古く、正しくない可能性があります。
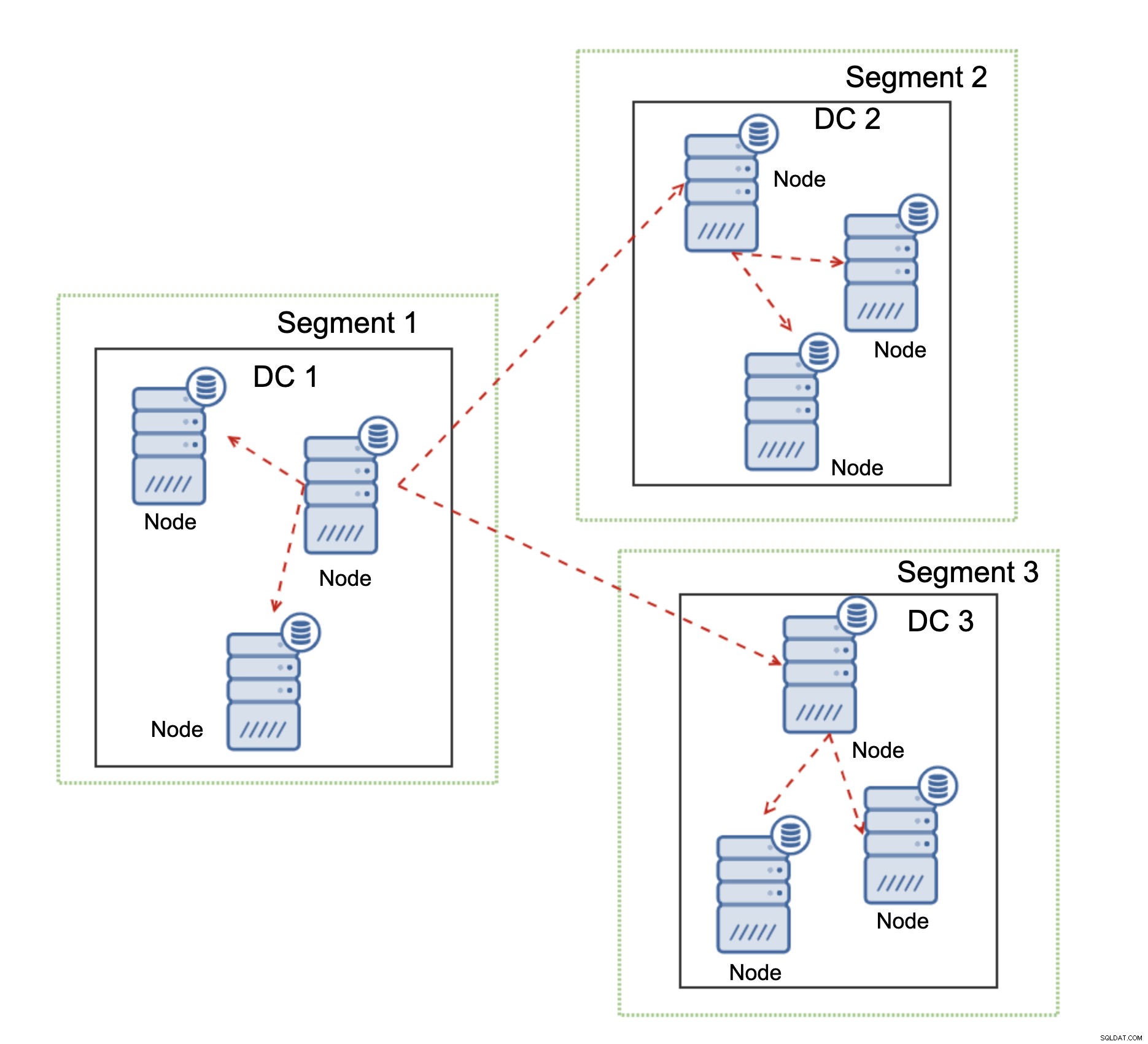
Galera Clusterのもう1つの機能で、使用するとパフォーマンスが大幅に向上します。 WANはセグメントです。デフォルトでは、Galeraはall to all通信を使用し、すべての書き込みセットはノードによってクラスター内の他のすべてのノードに送信されます。この動作は、セグメントを使用して変更できます。セグメントを使用すると、ユーザーはGaleraクラスターをいくつかの部分に分割できます。各セグメントには複数のノードが含まれる場合があり、そのうちの1つをリレーノードとして選択します。このようなノードは、他のセグメントからライトセットを受信し、セグメントにローカルなガレラノード全体にそれらを再配布します。その結果、上の図からわかるように、WANを介して送信されるレプリケーショントラフィックを3回減らすことができます。レプリケーションストリームの2つの「レプリカ」のみがWANを介して送信されます。データセンターごとに1つ、スレーブごとに1つです。 MySQLレプリケーションで。
Galera Clusterが優れているのは、ネットワークパーティショニングの処理です。 Galera Clusterは、クラスター内のノードの状態を常に監視しています。すべてのノードは、そのピアと接続してクラスターの状態を交換しようとします。ノードのサブセットに到達できない場合、Galeraは通信を中継しようとするため、それらのノードに到達する方法があれば、それらに到達します。

上の図に例を示します:DC1が接続を失いましたDC2を使用しますが、DC2とDC3は接続できます。この場合、DC3のノードの1つを使用して、DC1からDC2にデータを中継し、クラスター内通信を維持できるようにします。
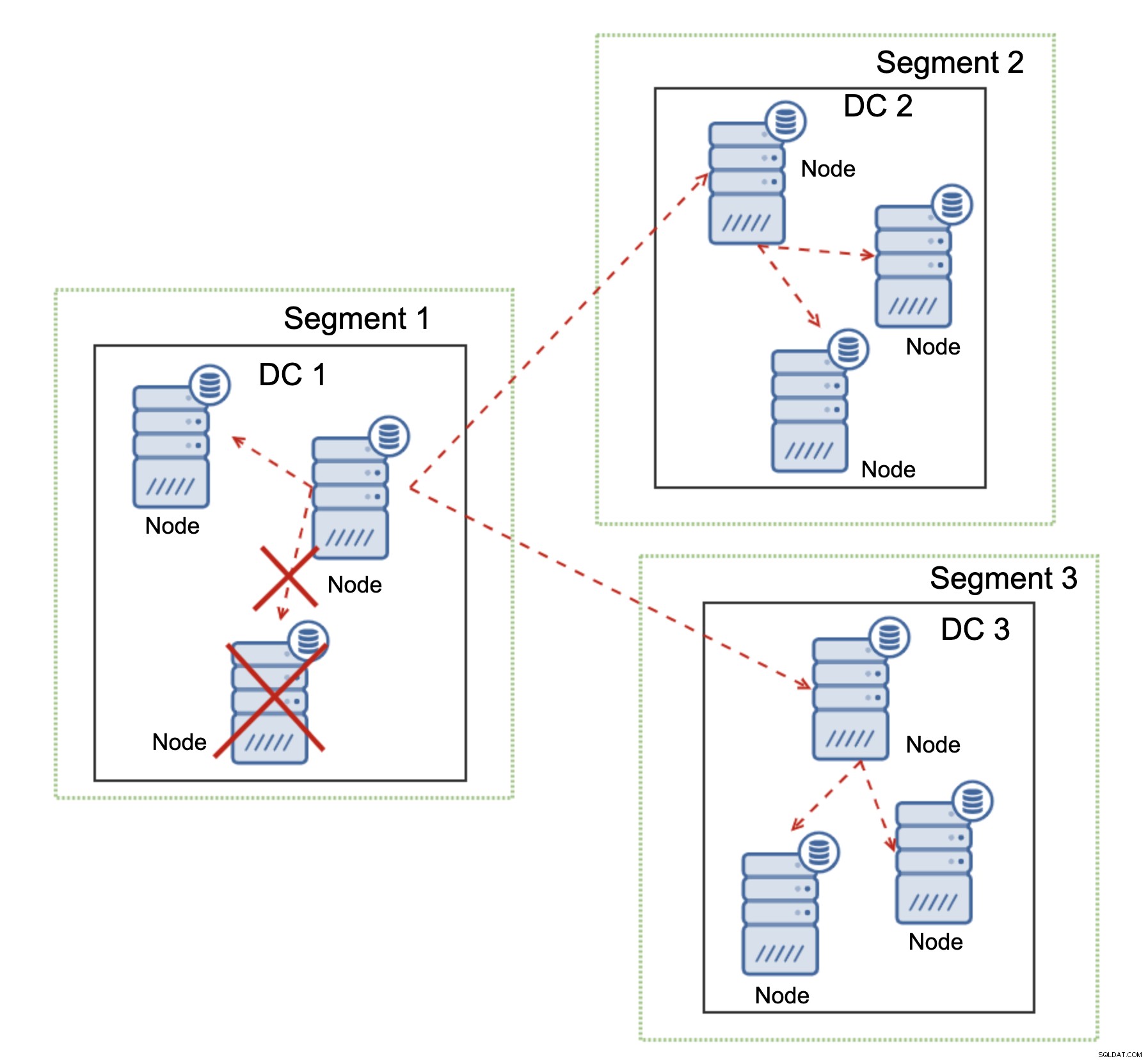
Galera Clusterは、クラスターの状態に基づいてアクションを実行できます。クォーラムを実装します。クラスターが動作できるようにするには、ノードの大部分が使用可能である必要があります。ノードがクラスターから切断され、他のノードに到達できない場合、ノードは動作を停止します。
上の図に示されているように、DC1のネットワーク通信が部分的に失われ、影響を受けるノードがクラスターから削除され、アプリケーションが古いデータにアクセスしないようにします。
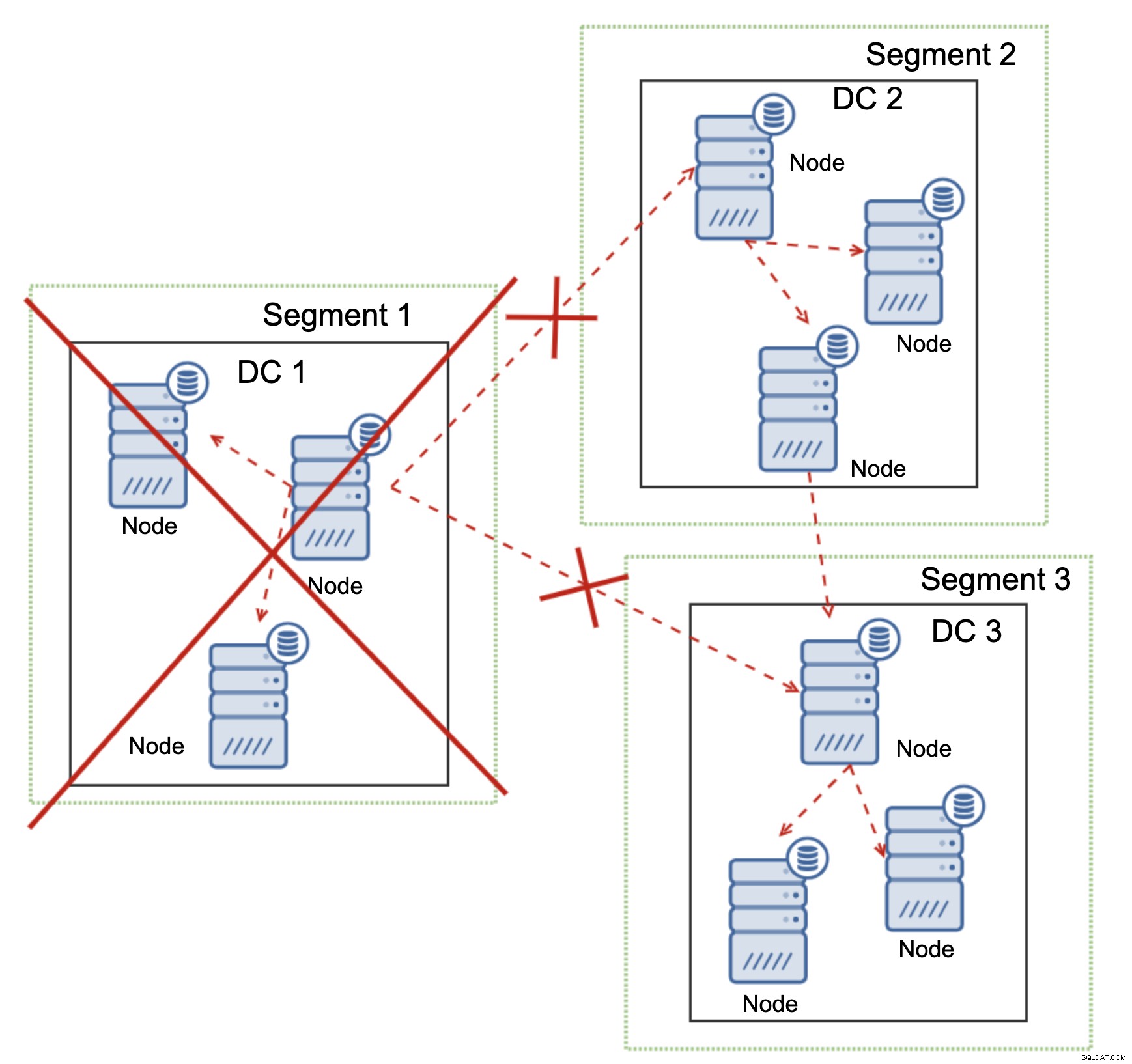
これは大規模にも当てはまります。 DC1はすべての通信を遮断しました。その結果、データセンター全体がクラスターから削除され、そのノードのどちらもトラフィックを処理しなくなりました。クラスターの残りの部分は過半数を維持し(9ノードのうち6ノードが使用可能)、DC2とDC3の間の接続を維持するようにクラスター自体を再構成しました。上の図では、書き込みがDC2のノードにヒットすると想定していますが、Galeraは複数のライターで実行できることに注意してください。
MySQLレプリケーションにはクラスター認識がないため、ネットワークの問題を処理するのに問題があります。他のノードとの接続が失われたときに自身をシャットダウンすることはできません。ネットワーク分割後に古いマスターが表示されないようにする簡単な方法はありません。
唯一の可能性は、プロキシ層以上に限定されています。クラスターの状態を理解し、必要なアクションを実行しようとするシステムを設計する必要があります。考えられる方法の1つは、Orchestratorなどのクラスター対応ツールを使用してから、Orchestrator RAFTクラスターの状態をチェックし、この状態に基づいてデータベースレイヤーで必要なアクションを実行するスクリプトを実行することです。これは、データベースより上位のレイヤーで実行されるアクションによって遅延が追加されるため、理想からはほど遠いものです。これにより、問題が発生し、正しいアクションを実行する前にデータの整合性が損なわれる可能性があります。一方、Galeraはデータベースレベルでアクションを実行し、可能な限り最速の反応を保証します。