はじめに
この記事では、 nvarcharの使用について説明します。 データ・タイプ。 SQL Serverがこのデータ型をディスクに格納する方法と、RAMで処理される方法について説明します。また、nvarcharのサイズがパフォーマンスにどのように影響するかを調べます。
実際のデータサイズ:ncharとnvarchar
nvarcharを使用します 列データエントリのサイズがおそらく大幅に変化する場合。ストレージサイズ(バイト単位)は、入力されたデータの実際の長さの2倍+2バイトです。これにより、 nchar を使用する場合と比較して、ディスクストレージを節約できます。 データ・タイプ。次の例を考えてみましょう。 2つのテーブルを作成しています。 1つのテーブルにはnvarchar列が含まれ、別のテーブルにはnchar列が含まれます。列のサイズは2000文字(4000バイト)です。
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
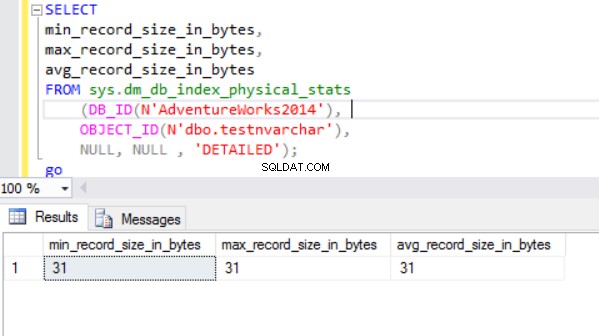
実際の行サイズは次のとおりです。
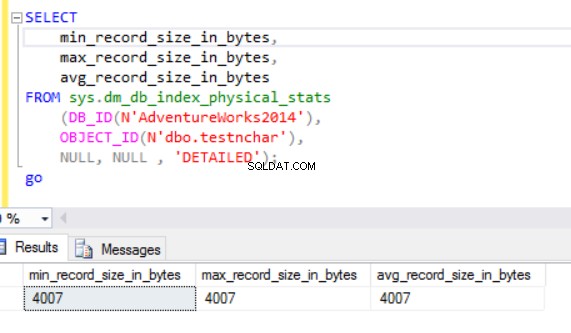
ご覧のとおり、nvarcharデータ型の実際の行サイズはncharデータ型よりもはるかに小さくなっています。 ncharデータ型の場合、約4000バイトを使用して10個の記号の文字列を格納します。 nvarcharデータ型の場合、同じ文字列を格納するために最大20バイトを使用します。
SQL Serverエンジンは、データをRAM(バッファープール)に処理します。メモリ内の行サイズはどうですか?
実際のデータサイズ:HDDとRAM
次のクエリを実行してみましょう:
SELECT col1 FROM dbo.testnchar;

固定長の文字列の場合、ディスクとRAMの使用率に違いはありません。
SELECT col1 FROM dbo.testnvarchar;

SQL Serverエンジンが、宣言された行サイズの半分(実際の20バイトではなく2000バイト)と追加情報のために数バイトのメモリを要求したことがわかります。一方からはディスクスペースの使用量を減らしますが、もう一方からは要求されたRAMを膨らませることができます。これは、さまざまな文字データ型を使用した場合の副作用です。この副作用は、場合によってはリソースに大きな影響を与える可能性があります。
FORMAT():要求されたRAMと使用されたRAM
FORMAT関数を使用します。この関数は、指定された形式とオプションのカルチャでフォーマットされた値を返します。戻り値はnvarcharです。 またはnull。戻り値の長さは、形式によって決定されます。 。 FORMAT(getdate()、‘yyyyMMdd’、’en-US’)は、「20170412」になります。この結果をディスクの列に格納するには16バイトが必要です(結果はnvarchar(8)になります)。特定のデータのRAMのデータサイズはどれくらいですか?
次のクエリを実行してみましょう。次の環境を使用します:
- AdventureWorks2014
- MSSQL2016開発版
- dbo.Customer(19'820'000レコード)にはSales.Customerからのデータが含まれています(19'820レコードは1000回アップロードされています)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
クエリ実行プランは非常に単純です:

最初の操作は、dbo.Customerテーブルでの「クラスター化インデックススキャン」です。 〜19000000レコードが読み取られました。推定データサイズは435Mbです。
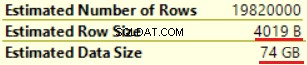
次の操作は「ComputeScalar」(FORMAT()関数の計算)です。 16バイトの文字列をフォーマットするため、結果はまったく予想外です。行サイズは23バイトから4019バイトに劇的に増加しました。推定データサイズと同じ—435MBから74GB。 FORMAT()がNVARCHAR(4000)を返すことがわかります。
MS SQL Server 2016には、過剰なメモリ許可を表示する優れた機能があります。最後の操作(T-SQL SELECT INTO)で警告を確認できます:
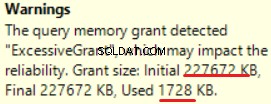
これはメモリの「過剰付与」です。付与されたメモリの90%以上が使用されていません。
クエリ時間の統計は次のとおりです。
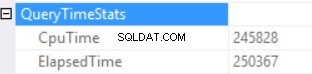
実行時間が長くなるのは、効果のないスカラー関数の実行と、過剰なメモリ付与–ハッシュ一致(右外部結合)の逆効果に依存します。複数のスカラー関数の実行と過剰なメモリの付与という2つの異なる原因の累積的な影響があります。
SQL Serverエンジンは、クエリごとに許可されたメモリの25%以下を許可できます。リソースガバナーを使用して、MSSQLServerのエンタープライズエディションでこの量を変更できます。付与されたメモリは、必須と追加の2つの部分で構成されます。必要なメモリは、内部のニーズ(並べ替えおよびハッシュ結合操作)に使用されます。追加のメモリは、推定データサイズに基づいています。必要なメモリと追加のメモリの両方が25%の制限を超える場合、SQL Serverエンジンは使用可能なメモリのさらに25%を許可します。詳細については、SQLServerメモリ付与の投稿をお読みください。
FORMAT()関数を使用せずに同じクエリを実行してみましょう。
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
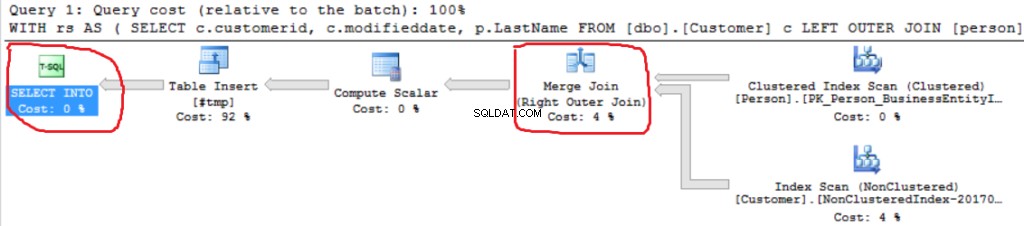
別の右外部結合の実装を見ることができます(ハッシュ結合の代わりにマージ結合)。
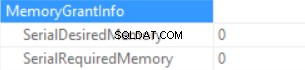
メモリ付与情報は次のとおりです(並べ替えがなく、ハッシュ結合SQL Serverがメモリを付与できない場合):
クエリ時間の統計は次のとおりです(時間は予想どおりに減少します。スカラー関数の実行はありません。推定データサイズは前のサンプルよりも小さくなっています):

そのため、FORMAT()関数を使用して、「許可されたメモリ」を最大222 MBまで膨らませています(使用しているのは2 MB未満です)。この例のデータ量は少ないです。
長時間実行クエリ
本番環境からの実際のSQLクエリについて考えてみます。このクエリは、バッチロードプロセス中に実行されました(従来のトランザクションシナリオではありません)。アマゾンウェブサービス(AWS、アマゾンリレーショナルデータベースサービス)で起動したMSSQLServerを使用します。 DBインスタンスの特性は、160 GBのRAM(クエリごとに最大30 GBのRAMを付与できます)と40vCPUです。 SQLクエリは上記の例とほぼ同じでした(違いはテーブルの量とデータサイズにあります):CTEには6つのテーブル間の結合が含まれています。 「マスターテーブル」(FROM句のテーブル)には、最大175,000,000のレコードが含まれ、データサイズは20GBです。ルックアップテーブル(JOIN句の右側のテーブル)は(メインテーブルと比較して)小さいです。 SQLクエリには、FORMAT()関数の2つの呼び出しが含まれています(「マスターテーブル」テーブルの2つの列がこの関数のパラメーターです)。
本番クエリは次のようになります:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
実行プランの「図」は以下のとおりです(実行プランは単純です。上部に順次結合と並べ替え(DISTINCTキーワード)があります):

情報を詳しく調べてみましょう。
最初の操作は「テーブルスキャン」です(すべてが正しく、驚くことではありません):

「スカラー計算」操作により、推定行サイズと推定行サイズが大幅に増加します(19GBから最大1.3TB)。 FORMAT()関数を2回呼び出すと、推定行サイズに約8000バイトが追加されました(ただし、実際のデータサイズは小さくなります)。

JOIN操作の1つ(ハッシュ一致、右外部結合)は、右のテーブルの一意でない列を使用します。少数のレコードの場合は問題ではありません。これは私たちの場合ではありません。その結果、推定データサイズは最大2,4TBまで増加しています。

警告もあります(この操作を処理するのに十分なRAMがありません):
SQLクエリの上部には「個別の並べ替え」操作が含まれています。これは、ケーキの上部にある桜のように見えます。そこにも同じ警告が表示されます。
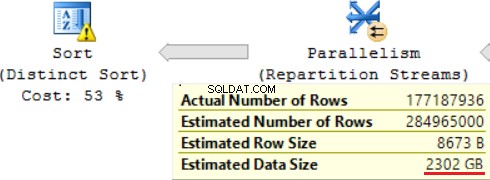
スカラー関数を使用した結果、クエリの実行に長い時間がかかります:24時間。この問題の原因の1つは、「推定データサイズ」に基づいて要求されたデータサイズが正しく推定されていないことです。 FORMAT()関数を使用しない場合、MSSQLServerはこのクエリを2時間で実行します。
結論
開発者は、nvarcharおよびvarcharデータ型を使用するときに注意する必要があります。列に冗長データ型を選択すると、必要なメモリが不足する可能性があります。その結果、RAMが無駄になり、データベースのパフォーマンスが低下します。