はじめに
この記事では、SQLServerのメモリ最適化テーブルのさまざまな種類のインデックスがパフォーマンスにどのように影響するかについて説明します。さまざまなインデックスタイプがメモリ最適化テーブルのパフォーマンスにどのように影響するかの例を検討します。
トピックの議論を容易にするために、かなり大きな例を使用します。簡単にするために、この例では、単一のテーブルのさまざまなレプリカを取り上げ、それに対してさまざまなクエリを実行します。これらのレプリカは、異なるインデックスを使用するか、インデックスをまったく使用しません(もちろん、主キー– PKを除く)。
この記事の実際の目的は、SQLServer自体のディスクベースのテーブルとメモリ最適化テーブルのパフォーマンスを比較することではないことに注意してください。その目的は、インデックスがメモリ最適化テーブルのパフォーマンスにどのように影響するかを調べることです。ただし、実験の全体像を把握するために、対応するディスクベースのテーブルクエリのタイミングも提供され、ディスクベースのテーブルの最適な構成をベースラインとして使用してスピードアップが計算されます。
シナリオ
このシナリオのサンプルデータは、次のように定義された単一のテーブルに基づいています。
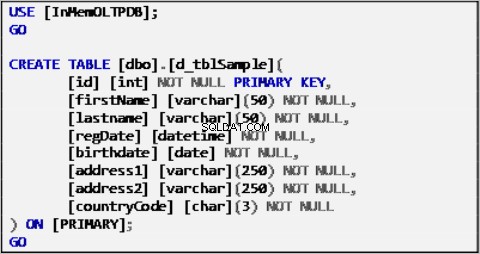
リスト1:サンプルデータソーステーブル。
上記の表にはサンプルデータが入力されており、残りの表のデータソースとして機能します。
したがって、上記の表に基づいて、次の9つの表のバリエーションを作成し、同じサンプルデータを入力します。
- 3つのディスクベースのテーブル:
- d_tblSample1
- 「id」列のクラスター化インデックス–主キー(PK)
- d_tblSample2
- 「id」列(PK)のクラスター化インデックス
- 「countryCode」列の非クラスター化インデックス
- d_tblSample3
- 「id」列(PK)のクラスター化インデックス
- 「regDate」列の非クラスター化インデックス
- 「countryCode」列の非クラスター化インデックス
- d_tblSample1
- 3つのメモリ最適化テーブル(セット1:ハッシュインデックス):
- m1_tblSample1
- 「id」列の非クラスター化ハッシュインデックス–主キー(PK)
- m1_tblSample2
- 「id」列(PK)の非クラスター化ハッシュインデックス
- 「countryCode」列のハッシュインデックス
- m1_tblSample3
-
- 「id」列(PK)の非クラスター化ハッシュインデックス
- 「regDate」列のハッシュインデックス
- 「countryCode」列のハッシュインデックス
-
- 3つのメモリ最適化テーブル(セット2:非クラスター化インデックス):
- m2_tblSample1
- 「id」列の非クラスター化インデックス–主キー(PK)
- m2_tblSample2
- 「id」列(PK)の非クラスター化インデックス
- 「countryCode」列の非クラスター化インデックス
- m2_tblSample3
- 「id」列(PK)の非クラスター化インデックス
- 「regDate」列の非クラスター化インデックス
- 「countryCode」列の非クラスター化インデックス
- m2_tblSample1
- m1_tblSample1
以下のリストで、上記の表の定義を見つけることができます。
シナリオロジックでは、同じテーブルのバリエーション(ただしインデックスは異なる)に対してさまざまなデータベース操作を実行し、それぞれの場合にパフォーマンスがどのように影響を受けるかを観察します。
定義
ディスクベースのテーブル
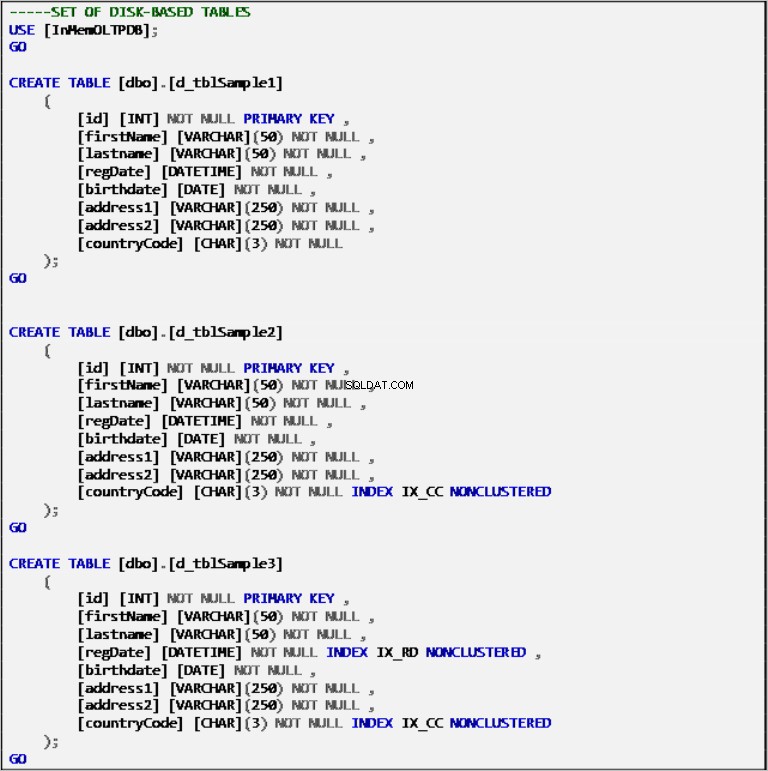
リスト2:ディスクベースのテーブルの定義。
メモリ最適化テーブル(セット1:ハッシュインデックス)

リスト3:メモリ最適化テーブル–セット1(ハッシュインデックス)
メモリ最適化テーブル(セット2:非クラスター化インデックス)

リスト4:メモリ最適化テーブル–セット2(非クラスター化インデックス)。
次に、上記のすべてのテーブルに同じサンプルデータを入力します。これは、各テーブルに合計500万レコードあります。
テーブルの各セットに対するcountコマンドの出力は次のとおりです。
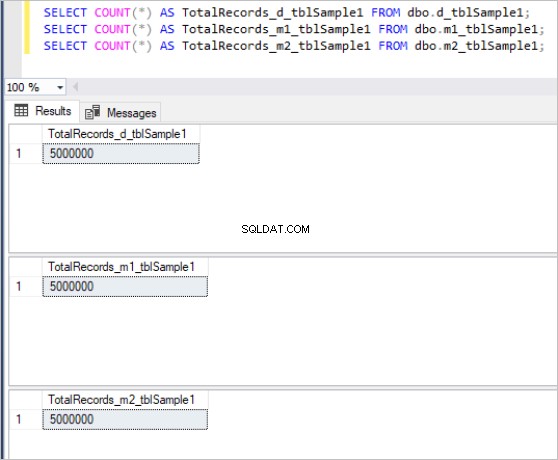
図1:最初のテーブルセットのレコードの総数。
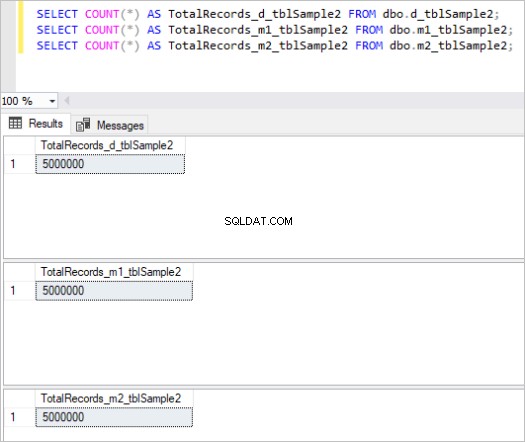
図2:2番目のテーブルセットのレコードの総数。
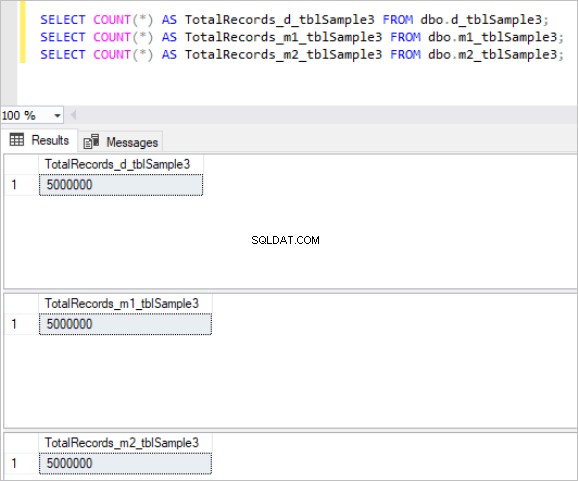
図3:3番目のテーブルセットのレコードの総数。
クエリとシナリオの実行
次に、上記のテーブルに対して一連のクエリを実行し、各テーブルのパフォーマンスを確認します。
これらのクエリは、次の操作を実行します。
- クエリ1:集計(GROUP BY)
- クエリ2:同等性述語のインデックスシーク
- クエリ3:等式および不等式述語のインデックスシーク
計画は、以下のようにクエリを実行することです:
クエリ1–次のテーブルに対する実行:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1(ターゲット列にインデックスがありません)
- m2_tblSample1(ターゲット列にインデックスがありません)
クエリ2–次のテーブルに対する実行:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1(ターゲット列にインデックスがありません)
- m2_tblSample1(ターゲット列にインデックスがありません)
クエリ3–次のテーブルに対する実行:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1(ターゲット列にインデックスがありません)
- m2_tblSample1(ターゲット列にインデックスがありません)
注 : d_tblSample1の定義は ディスクベースのテーブルは上記のテーブル定義に含まれており、この記事で提供されるクエリでは使用されません。その理由は、メモリ最適化テーブルのパフォーマンスと比較するときにベースラインをできるだけ高速にするために、各シナリオで、ディスクベースのテーブルに最適な構成が使用されるためです。この目的のために、 d_tblSample1 表は情報提供のみを目的として提示されています。
以下に、3つのクエリのT-SQLスクリプトと、実行時間の測定メカニズムを示します。

リスト5:クエリ1 –集計(インデックス付き)。
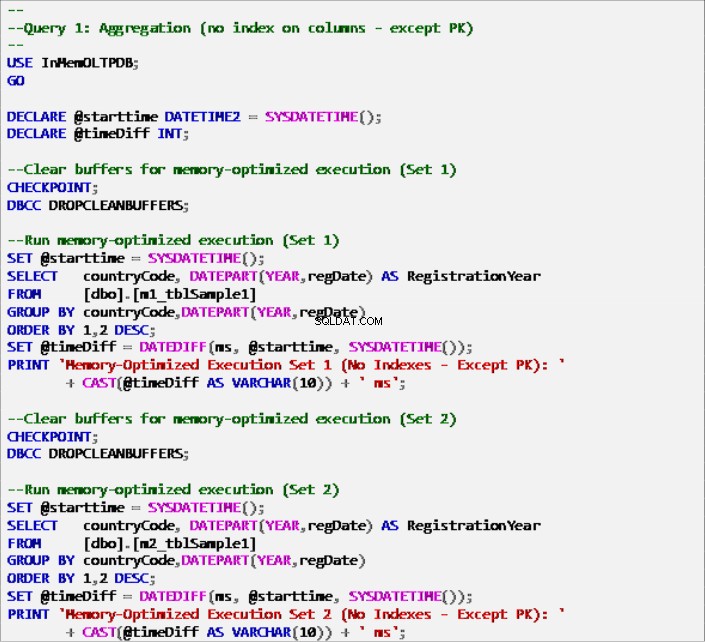
リスト6:クエリ1 –集計(インデックスなし–主キーを除く)
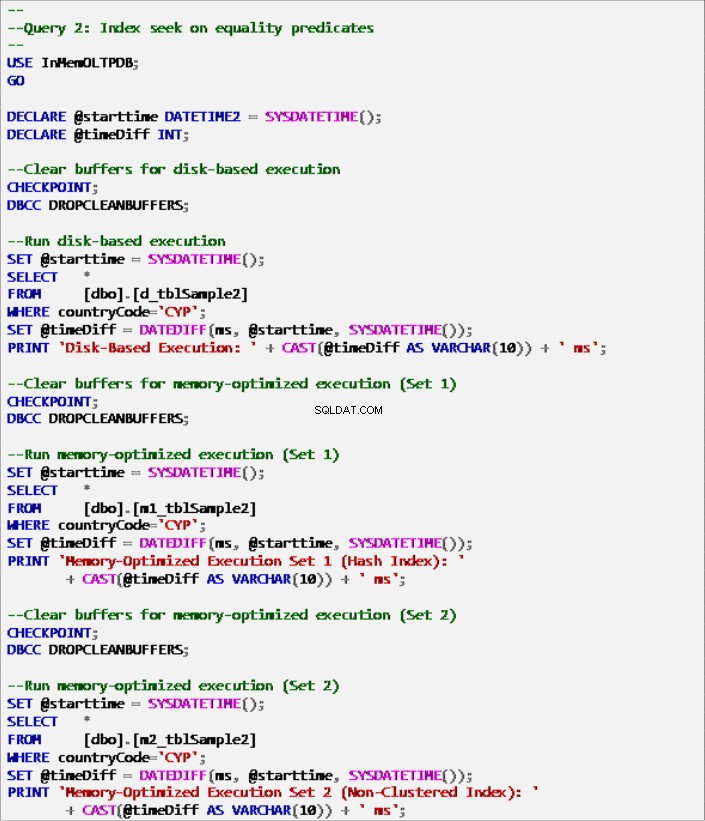
リスト7:クエリ2 –等価述語のインデックスシーク(インデックス付き)

リスト8:クエリ2 –等価述語のインデックスシーク(インデックスなし–主キーを除く)
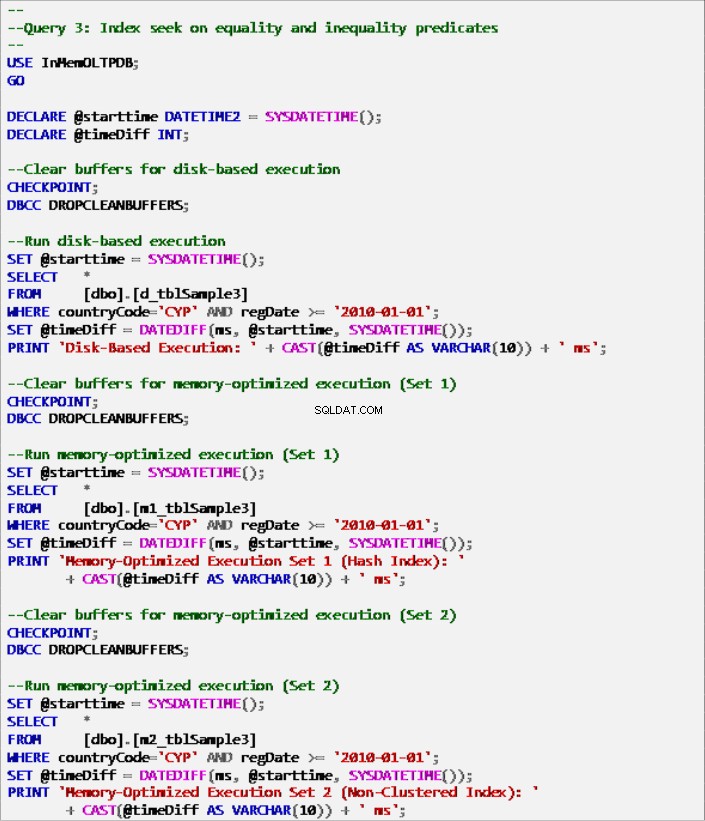
リスト9:クエリ3 –等式および不等式述語のインデックスシーク(インデックス付き)。

リスト10:クエリ3 –等式および不等式述語のインデックスシーク(インデックスなし–主キーを除く)
以下のスクリーンショットは、各クエリ実行の出力を示しています。
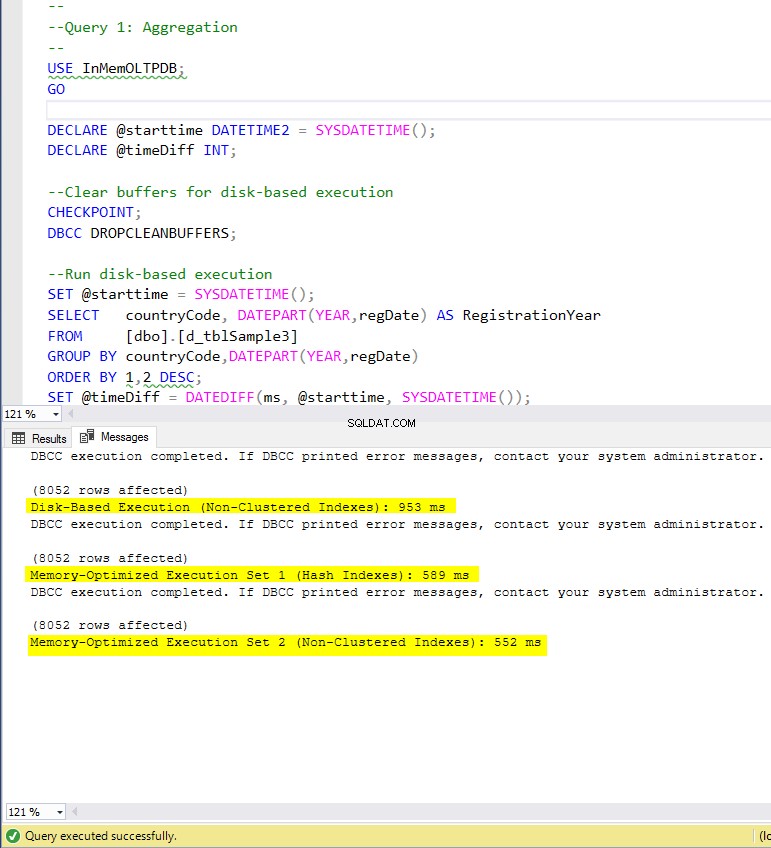
図4:クエリ1の実行時間(インデックス付き)
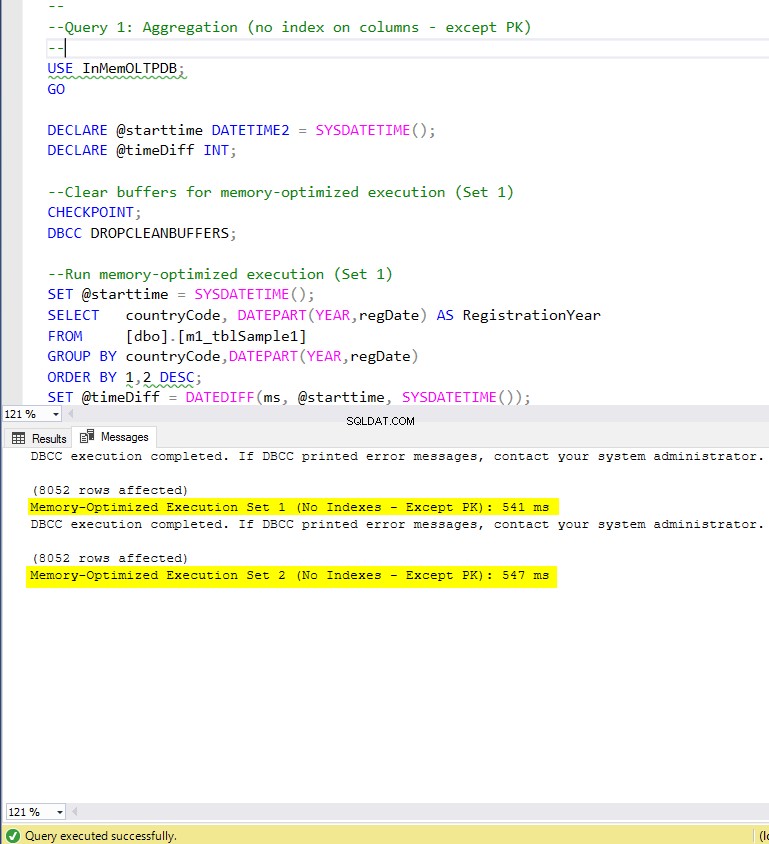
図5:クエリ1の実行時間(インデックスなし– PKを除く)
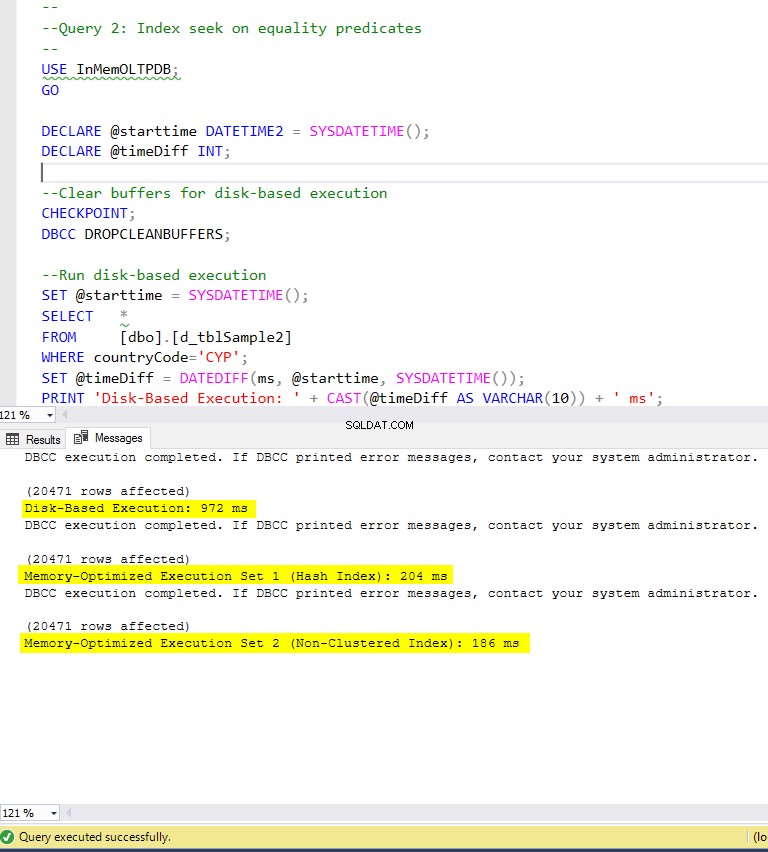
図6:クエリ2の実行時間(インデックス付き)
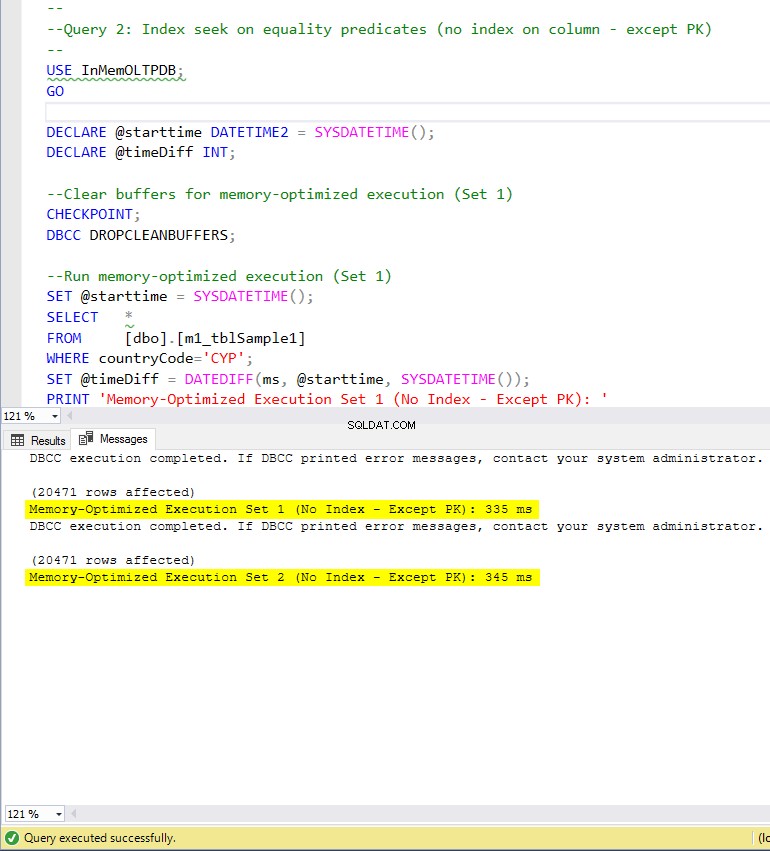
図7:クエリ2の実行時間(インデックスなし– PKを除く)
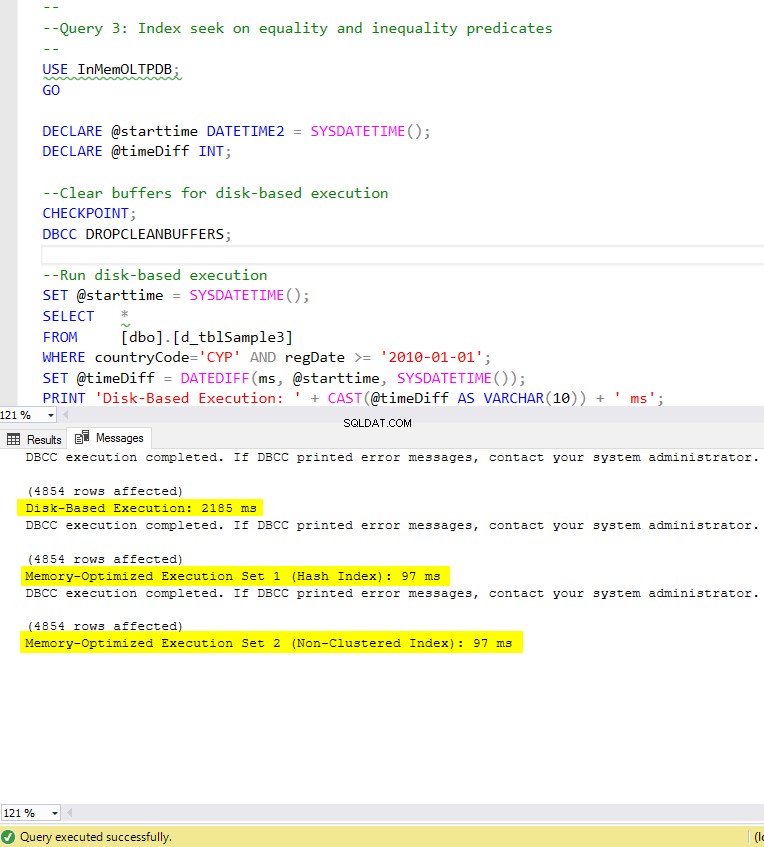
図8:クエリ3の実行時間(インデックス付き)
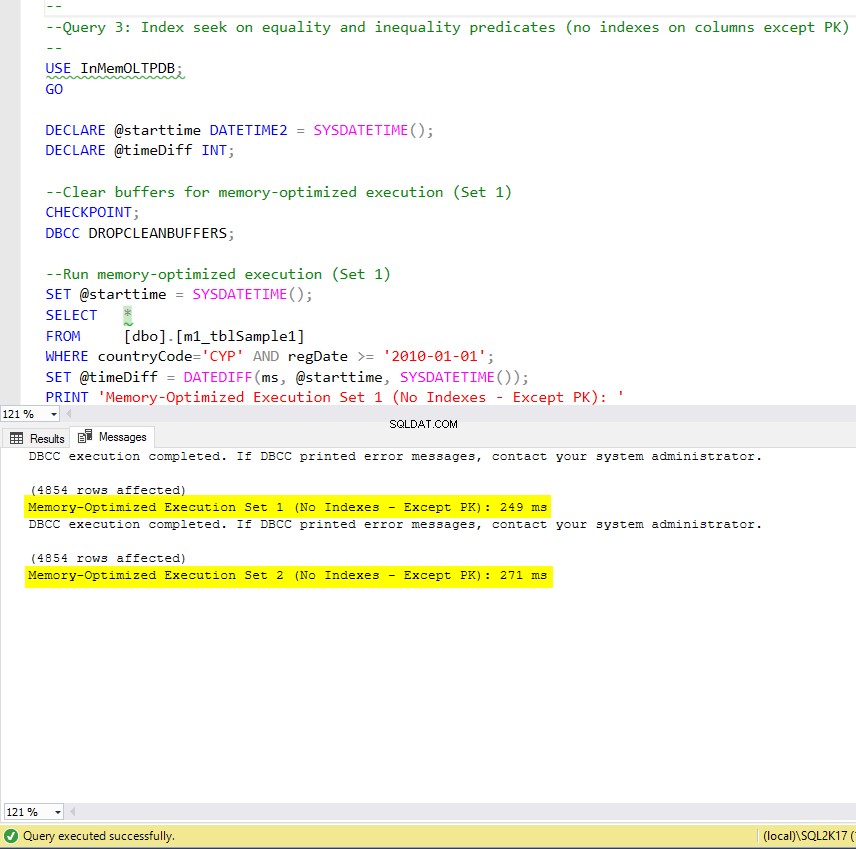
図9:クエリ3の実行時間(インデックスなし– PKを除く)
それでは、上記で得られた結果を要約しましょう。次の表は、上記のすべてのクエリとテーブル/インデックスの組み合わせについて測定された実行時間を示しています。
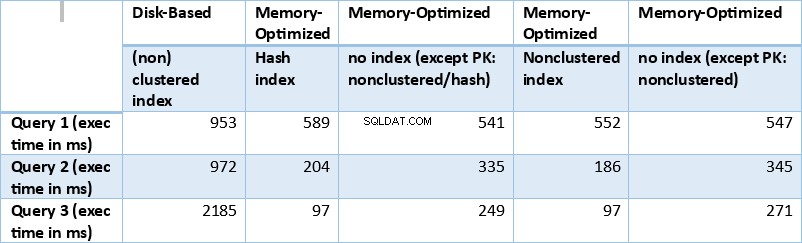
表1:すべてのクエリの実行時間(ミリ秒)の概要。
ディスカッション
上記の表に要約されている実行結果を調べると、特定の結論に達することができます。各クエリ結果をグラフにプロットしてみましょう。以下のグラフは、実行時間と、ディスクベースのテーブルよりもメモリが最適化されたテーブルの高速化を示しています。
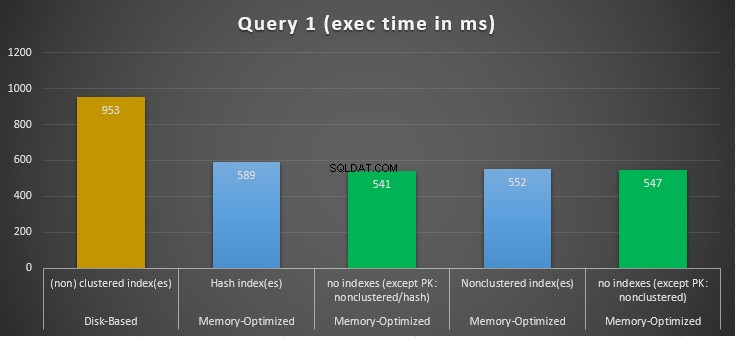
図10:クエリ1の実行時間の比較。
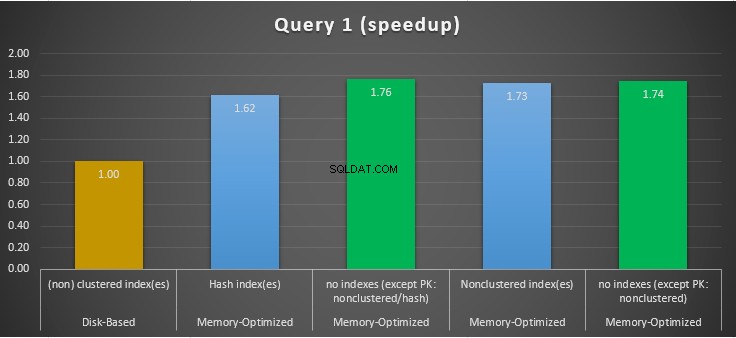
図11:クエリ1の高速化の比較。
GROUP BY集計であるクエリ1に関しては、メモリ最適化テーブルの両方のバージョン(インデックスとインデックスなし)がほぼ同じように実行され、ディスクベースのテーブル(インデックスが有効)よりも
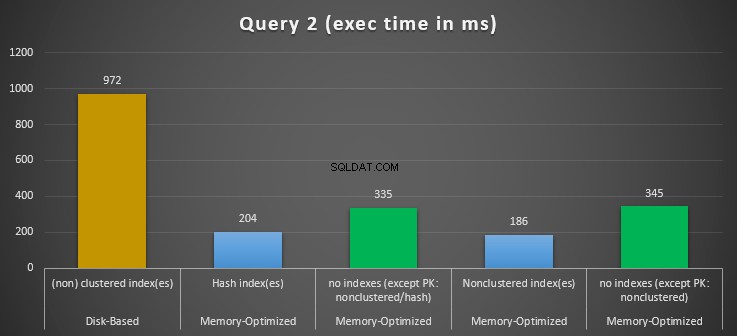
図12:クエリ2の実行時間の比較。
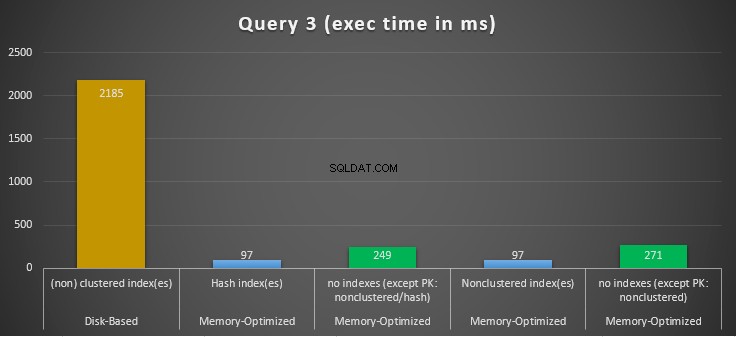
図13:クエリ2の高速化の比較。
等価述部のインデックスシークを含むクエリ2に関しては、インデックスのあるメモリ最適化テーブルの方が、インデックスのないメモリ最適化テーブルよりもパフォーマンスがはるかに優れていることがわかります。さらに、述語として使用される列に非クラスター化インデックスを使用したメモリ最適化テーブルは、ハッシュインデックスを使用したテーブルよりもパフォーマンスが優れていることがわかります。
したがって、クエリ2の場合、勝者は非クラスター化インデックスを使用したメモリ最適化テーブルであり、全体的な速度が 5.23になります。 ディスクベースの実行よりも2倍高速です。
図14:クエリ3の実行時間の比較。
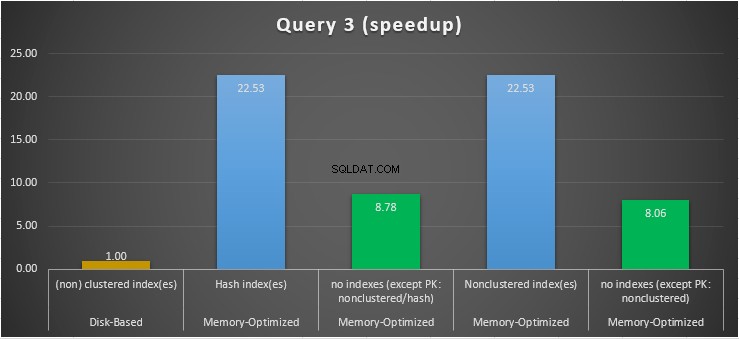
図15:クエリ3の高速化の比較。
等式と不等式の述語を組み合わせたインデックスシークを含むクエリ3に関しては、インデックスのあるメモリ最適化テーブルの方が、インデックスのないメモリ最適化テーブルよりもパフォーマンスが優れていることがわかります。さらに、述語として使用される列に非クラスター化インデックスを使用したメモリ最適化テーブルは、ハッシュインデックスを使用したテーブルと同じように機能することがわかります。
この目的のために、述語として使用される列のインデックスを使用する両方のメモリ最適化テーブルは、インデックスのないテーブルよりも高速に実行され、22.53倍高速を達成したことがわかります。 ディスクベースの実行で。
結論
この記事では、SQLServerのメモリ最適化テーブルでのインデックスの使用法について説明しました。各クエリのベースラインとして、可能な限り最良のディスクベースのテーブル構成を使用し、次に3つのクエリのパフォーマンスをディスクベースのテーブルおよびメモリ最適化テーブルの4つのバリエーションと比較しました。メモリ最適化テーブルの4つのうち2つはインデックス(ハッシュ/非クラスター化)を使用し、他の2つは主キーに使用されるものを除いてインデックスを使用しませんでした。
全体的な結論として、メモリ最適化テーブルだけでなくディスクベースのテーブルでも、インデックスがパフォーマンスにどのように影響するかを常に調べる必要があります。また、インデックスがパフォーマンスを向上させることがわかった場合は、それらを使用する必要があります。この記事の例の結果は、メモリ最適化テーブルで適切なインデックスを使用すると、インデックスなしでメモリ最適化テーブルを使用する場合と比較して、この記事で使用したものと同様のクエリのパフォーマンスを大幅に向上できることを示しています。 。
参考資料と参考資料:
- Microsoft Docs:メモリ最適化テーブル
- Microsoft Docs:メモリ最適化テーブルでインデックスを使用するためのガイドライン
- Microsoft Docs:メモリ最適化テーブルのインデックス
便利なツール:
dbForge Index Manager – SQLインデックスのステータスを分析し、インデックスの断片化に関する問題を修正するための便利なSSMSアドイン。