この記事では、セマンティック検索の完全なウォークスルーを含む、セマンティック検索の基本について説明します。最初から始めて、すぐに使用できる機能で終了します。
さらに、読者は、セマンティック検索など、SQL Serverで利用できる非常に便利で一般的には知られていない検索機能のいくつかについて学習します。これについては、いくつかの基本的な例で説明します。
この記事では、通常の検索では実行できない特定の形式の分析に対するセマンティック検索の重要性も強調しています。
セマンティック検索とは
まず、セマンティック検索とは何か、および全文検索との違いを理解しましょう。
Microsoftの定義
Microsoftのドキュメントによると、セマンティック検索は非構造化ドキュメントへの深い洞察を提供します。
代替定義
セマンティック検索は、非構造化データがSQL Serverデータベース内に保存されている場合に、主に非構造化データまたはMSWordドキュメントなどのドキュメントで包括的な検索または比較分析を実行するために使用される特別な検索テクノロジまたは機能です。
互換性
セマンティック検索は、SQLServer2012以降のバージョンとのみ互換性があります。
セマンティック検索は、AzureSQLデータベースまたはAzureデータウェアハウスクラウドソリューションと互換性がないことに注意してください。
つまり、この強力な機能を利用するには、Azure上のVMまたはオンプレミスのSQLServerインスタンスのいずれかで作業する必要があります。
セマンティック検索と全文検索
Microsoftのドキュメントによると、全文検索ではドキュメント内の単語をクエリできます。セマンティック検索では、ドキュメントの意味を照会できます。
セマンティック検索と全文検索は、Microsoft SQL Serverが提供する1つの共同機能であり、SQL Serverインスタンスのインストール中にインストールするか、既存のSQLインスタンスに新しい機能を追加することで後でインストールするかを選択できます。
前提条件
この記事のウォークスルーに従うために必要ないくつかの事項とともに、セマンティック検索の一般的な使用の前提条件を確認しましょう。
全文検索がインストールされています
全文検索とセマンティック検索は両方とも共同機能として提供されているため、全文検索の設定方法を知っておく必要があります。
初心者がフルテキスト検索を設定するには、SQL Server 2016でのフルテキスト検索の実装の記事を参照してください。これは、SQLServerにセマンティック検索をインストールするための前提条件です。
この記事では、SQLServerインスタンスに全文検索がインストールされていることを前提としています。
dbForge Studio for SQL Server
セマンティック検索(この記事のウォークスルー)を使用するには、非構造化データをSQL Serverデータベースに保存する必要があります。この記事では、非構造化データをSQL Serverに直接保存するのではなく、dbForge Studio forSQLServerを使用してこれを行いました。
SQL Server 2016
この記事ではSQLServer2016を使用していますが、他の互換性のあるバージョンでも手順はほぼ同じです。
セマンティック検索の設定
セマンティック検索または統計セマンティック検索を使用するには、全文検索のインストール中またはインストール後に、全文検索とセマンティック検索を新機能として追加することでインストールできます。
全文検索チェック
マスターデータベースに対して次のスクリプトを実行して、全文検索とセマンティック検索のインストールステータスを確認してください。
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO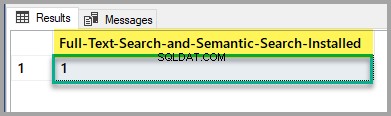
出力が1の場合は問題ありませんが、0の場合は、上記の記事を参照して、SQLServerのセットアップを使用して全文検索とセマンティック検索機能をインストールしてください。
意味言語統計データベースのインストール
Microsoft®SQLServer®2016SemanticLanguageStatistics を検索して、Semantic LanguageStatisticsDatabaseをインストールします。 インターネット上で、または次のリンクをクリックしてください。
Windowsエディションに基づいてダウンロードを選択する:
言語データベースをインストールします:
次へをクリックします ライセンス契約の条件に問題がない場合は、次の手順に進みます。
デフォルトのオプションはそのままにしておきますが、以下に示すようにディスクコストを確認することをお勧めします。
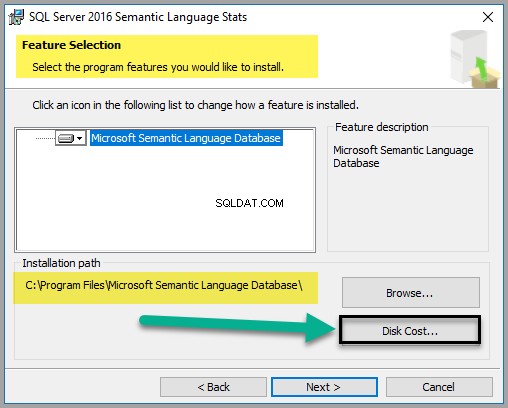
ファイルは約747MBのスペースしか必要としませんが(この記事の執筆時点)、ディスクのコストをチェックして、十分なスペースがあることを確認してください。
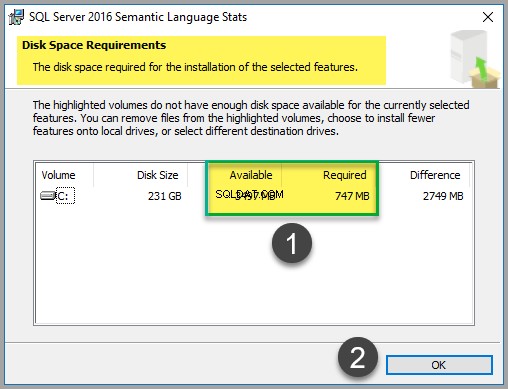
ディスクコストのチェックが完了したら、[ OK]をクリックします 次に、[次へ]をクリックします 。
ファイルをインストールするように求められます。インストールをクリックしてください。 (興味がある場合):
完了をクリックします インストールが正常に完了すると、次のスクリーンショットのようになります。
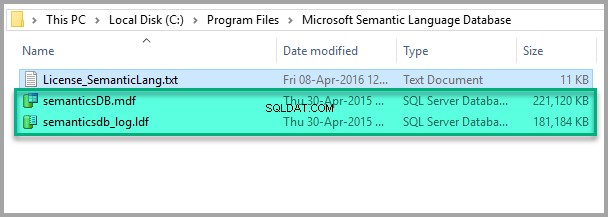
Semantic Language Databaseがデフォルトでインストールされているフォルダー(C:\ Program Files \ Microsoft Semantic Language Database)を見つけます:
すべてが良さそうなので、以下に示すように、データとログファイルをSQLインスタンスのデータフォルダにコピーします。
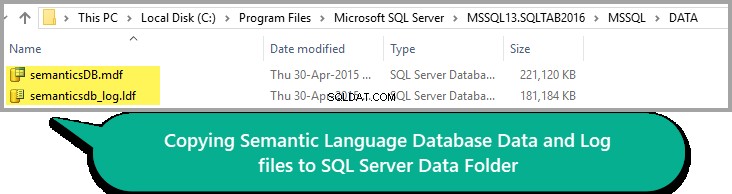
DATAフォルダのパスはSQLServerのバージョンによって異なる場合があることに注意してください。
セマンティック言語データベースをSQLインスタンスにアタッチする
データベースを右クリックします SSMS(SQL Server Management Studio)のオブジェクトエクスプローラーの下のノード 添付をクリックします :
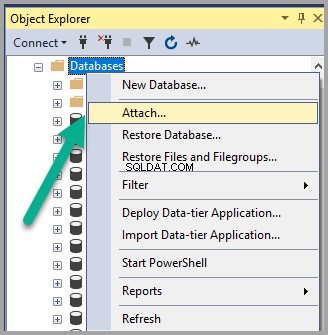
Semanticsdb.mdfを追加します [OK]をクリックします :
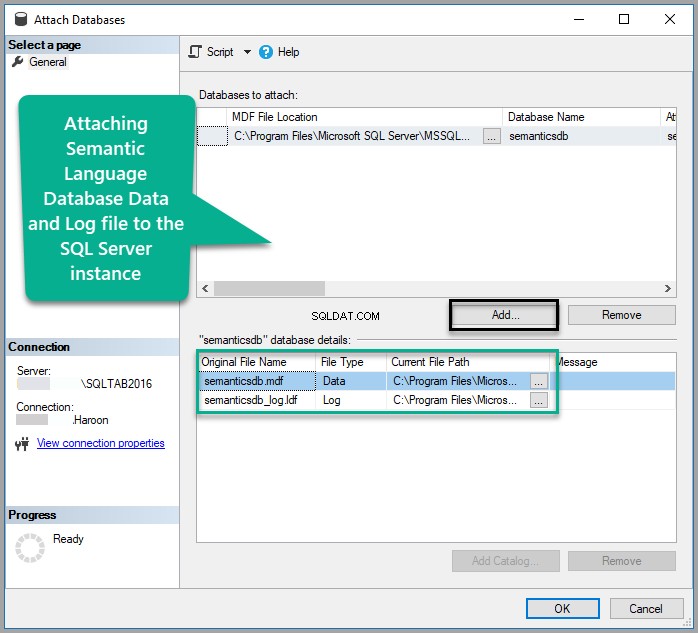
データベースを表示する:
セマンティックデータベースの登録
マスターデータベースに対して次のスクリプトを入力して、セマンティック言語統計データベースを登録します。
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOセマンティックデータベースのステータスを確認する
マスターデータベースに対して次のスクリプトを実行して、セマンティック言語統計データベースのステータスを確認します。
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GO出力は空であってはならず、次のようになります。

上記の値はマシンによって異なる場合があることに注意してください。これは、行が表示されている限り正常です。これは、セマンティック言語統計データベースがSQLインスタンスに正常にインストールされたことを意味します。
セマンティック検索の使用
セマンティック検索がすべてセットアップされると、SQLServerで使用できるようになります。
セマンティック検索シナリオ
従業員のドキュメント(サンプル)をリッチテキスト形式でSQL Serverデータベースに保存し、後でセマンティック検索を使用して検索および比較できるようにします。
EmployeesSampleデータベースを設定する
次のようにマスターデータベースに対してT-SQLスクリプトを実行して、単一のテーブルでサンプルデータベースを作成します。
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOサンプルデータベースを確認する
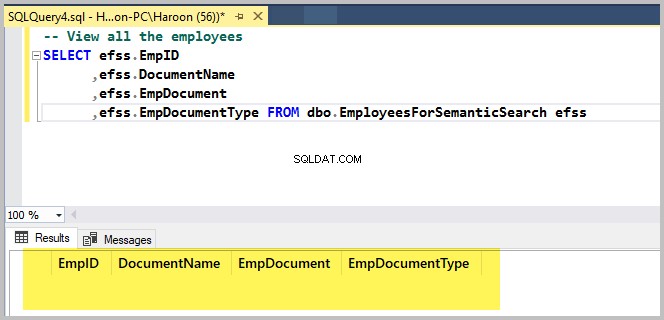
サンプルデータベーステーブルを確認するために、次のスクリプトを実行します。
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efss出力は次のとおりです。
dbForge Studio forSQLServerを使用して最初のリッチテキストファイルを追加する
dbForge Studio for SQL Server を使用して、リッチテキストファイルで表されるバイナリデータをテーブルに追加します。 。
サンプルデータベースを開きますEmployeesSample dbForge Studio forSQLServerで。
EmployeesForSemanticSearchを右クリックします 表をクリックし、[データの取得:]をクリックします
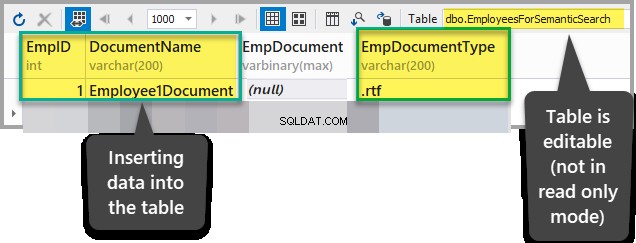
次のデータをEmployeesForSemanticSearchに追加します EmpDocumentを除くテーブル テーブルが読み取り専用モードでないことを確認した後の列:
EmpID:1
DocumentName:Employee1Document
EmpDocument:(null)
EmpDocumentType:.rtf
リッチテキスト形式のドキュメントをEmpDocumentに挿入します 次のテキストをテーブルに追加して列を作成します(楕円をクリックしてデータを追加します):
This is a research based article and it is a new research which is in process but this is superb in the field of research.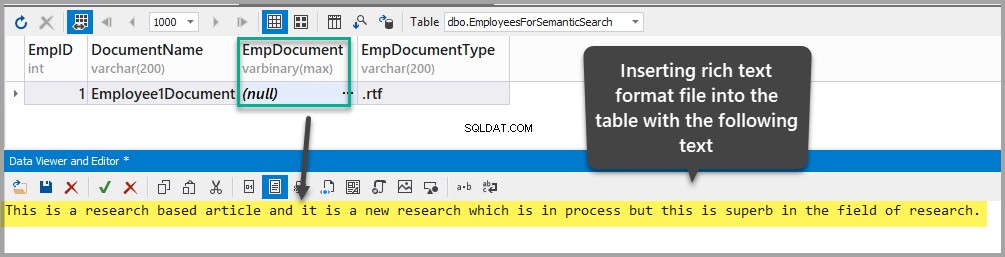
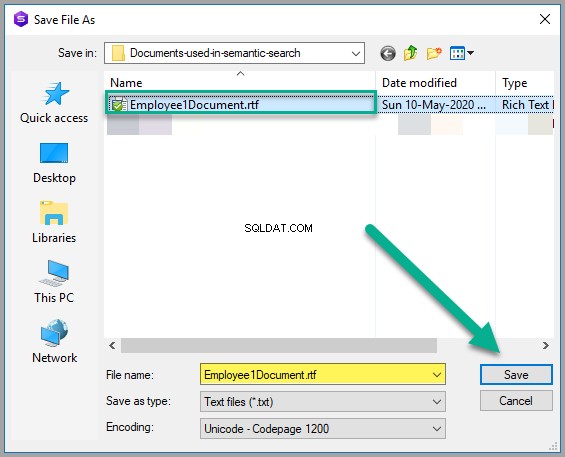
ドキュメントをEmployee1Document.rtfとして保存します 適切なWindowsフォルダ内:
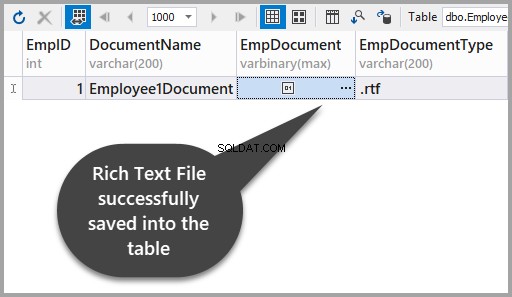
変更を適用して、リッチテキストファイルがテーブルに正常に保存されたことを確認してください:
dbForge Studio forSQLServerを使用して2番目のリッチテキストファイルを追加する
次に、別のリッチテキストファイルを EmployeesForSemanticSearchに追加します 次の情報を使用して、上記と同じ方法でテーブルを作成します。
EmpID:2
DocumentName:Employee2Document
EmpDocument:(null)
EmpDocumentType:.rtf
次のテキストを含む別のリッチテキストファイルを追加します:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.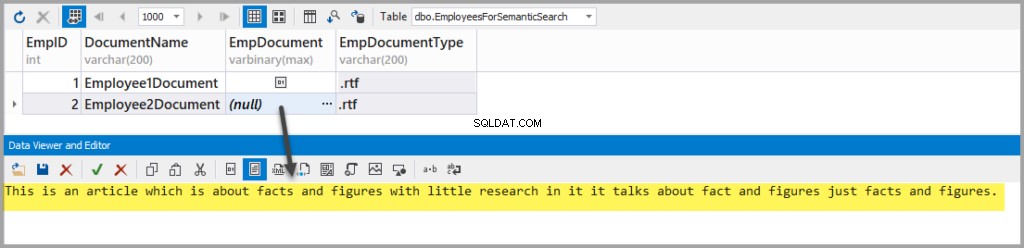
次のように、ドキュメントを同じフォルダに保存します。
テーブルを更新し、[はい]をクリックして変更を確認してデータを保存します:
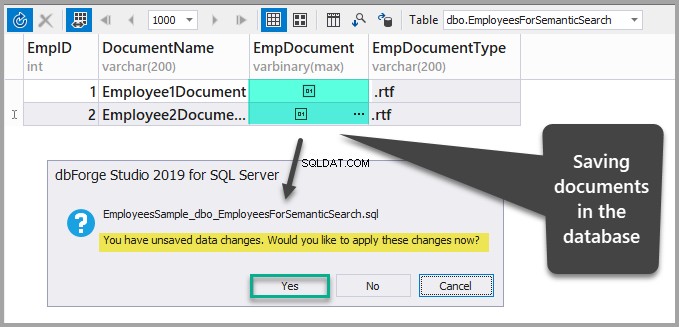
ウィザードを使用して、一意のインデックス、フルテキストインデックス、およびセマンティックインデックスを作成します
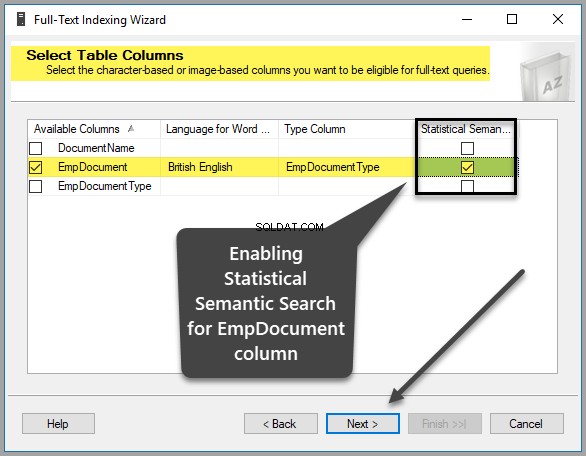
SSMS(SQL Server Management Studio)に戻り、テーブルを右クリックして、フルテキストインデックスをクリックします。 次に、フルテキストインデックスの定義…をクリックします。 以下に示すように:
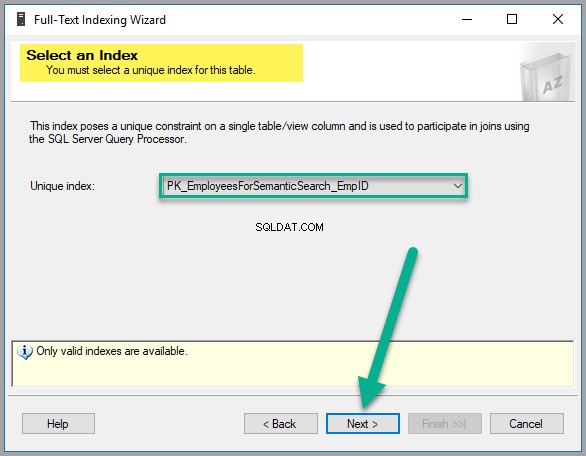
次に、 EmpID を作成したため、実際にはデフォルトで選択されている一意のインデックスを選択する必要があります。 以下に示すように、前の主キー列は、次へをクリックします。 続行するには:
EmpDocumentを選択してください 使用可能な列から 、イギリス英語 ワードブレーカーの言語として 、 EmpDocumentType タイプ列として 統計的セマンティック検索を確認してください 次のように同じ行のボックス:
これらの設定を変更する明確な理由がない限り、変更追跡オプションをデフォルト設定のままにして選択します。
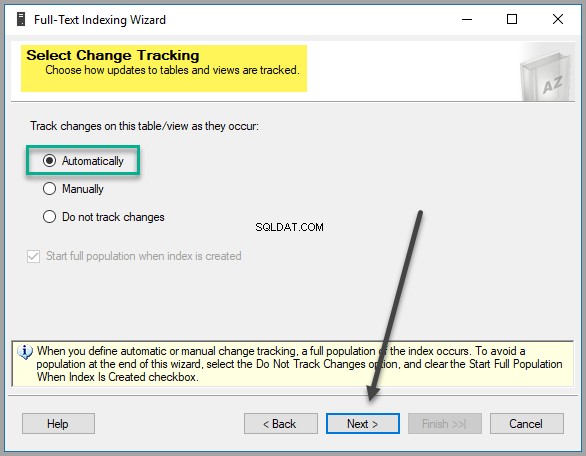
EmployeeCatalogとして新しいカタログを作成します :
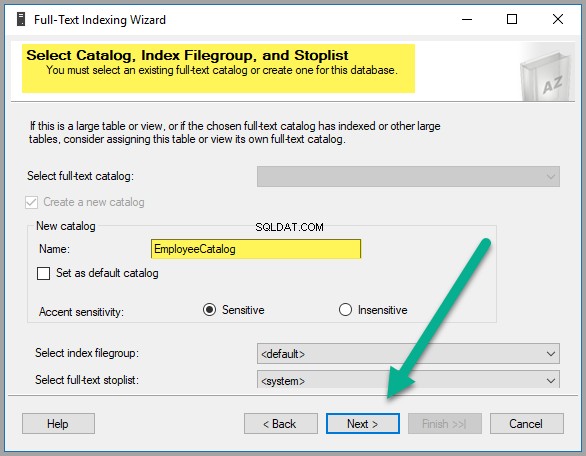
次へをクリックします もう一度:
最後に、さらに数回クリックした後(次へをクリックします) )、必要なテーブルはセマンティック検索でクエリできるようになっています:
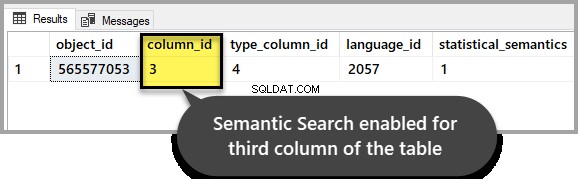
テーブルに対してセマンティック検索が有効になっているかどうかを確認します
サンプルデータベースに対して次のスクリプトを実行して、対象のテーブルのセマンティック検索がそのまま残っているかどうかを確認してください。
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GOウォークスルーの最初に設定したように、出力は3番目の列で有効になっていることを示しているはずです:
例1:セマンティック検索スコアを使用して関連ドキュメントを検索する
これで、セマンティック検索を使用して2つのドキュメントを比較し、関心のあるキーワードとその相対スコアを見つけることができます。これにより、より関連性の高いドキュメントを見つけることができます。
「調査」という単語が含まれているドキュメントを表示することに関心がある場合 」は他のドキュメントと比較して頻繁に言及されるため、次のT-SQLスクリプトを実行するときは、各ドキュメントのスコアを監視する必要があります。
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;上記のクエリの結果は次のとおりです。
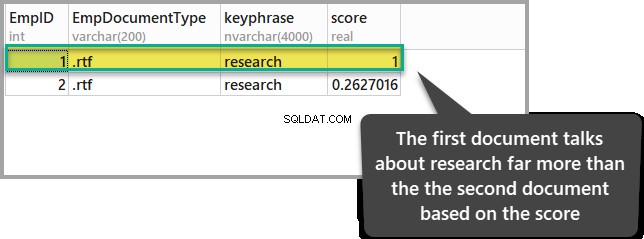
スコアが最も高いドキュメントは、関心のあるポイント(調査)に関する限り、他のドキュメントと比較して関連性が高いことを示しています。
例2:セマンティック検索スコアを使用して関連ドキュメントを検索する
以下のスクリプトを実行すると、他のドキュメントと比較して「事実」という単語が支配的なドキュメントを見つけることもできます。
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;結果は次のとおりです。
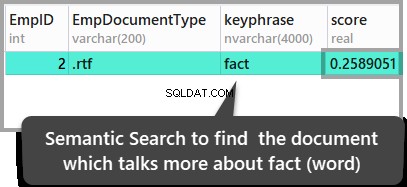
上記の結果は、2番目に保存されたドキュメントが事実という単語が含まれる唯一のドキュメントであるという結論につながります。 が記載されていますが、これらの結果を確認したい場合は、保存されているドキュメントを開いて確認してください。
おめでとう! SQL Serverでセマンティック検索を設定する方法を習得しただけでなく、セマンティック検索を実際に使用した経験も得られました。
やるべきこと
基本的なセマンティック検索クエリを設定して作成できるようになったので、スキルをさらに向上させるために次のことを試してください。
- 調査について説明している別のドキュメントを追加してみてください 次に、最初の例のスクリプトを実行して、スコアを比較することにより、どのドキュメントが最も関連性の高いドキュメントであるかを確認します。
- この記事を念頭に置いて、事実という単語が含まれる別のドキュメントを追加します を数回言及してから、この記事の例2でT-SQLを実行して、結果が同じままか変化するかを確認します。
- 既存のドキュメントと新しいドキュメントの両方にドキュメントとテキストを追加してセマンティック検索を使用し、関心のある単語に一致するドキュメントを見つけてみてください。
- 例をさらに詳しく調べて、セマンティック検索で大文字と小文字が区別されるか大文字と小文字が区別されないかを自分で確認します(ヒント:例を少し変更できます)。