SQL Serverのクエリ最適化とは何ですか?それは大きなトピックです。それぞれのテクニックや問題は、ベースをカバーするために別々の記事を必要とします。ただし、クエリを使用してゲームをレベルアップし始めたばかりの場合は、より簡単な信頼できるものが必要です。これがこの記事の目標です。
クエリが最適で、すべてがうまく機能し、ユーザーが満足していると言うかもしれません。もちろん、パフォーマンスがすべてではありません。結果も正しいはずです。結合、サブクエリ、同義語、CTE、ビューなど、どのようなものであっても、許容範囲内で実行する必要があります。
そして、一日の終わりに、あなたはあなたのユーザーと一緒に家に帰ることができます。実行の遅いクエリを一晩で修正するためにオフィスに留まりたくない。
始める前に、旅は荒くならないことを保証しておきましょう。これは単なる入門書になります。あなたにとっても異質ではない例を紹介します。最後に、より深い研究の準備ができたら、チェックアウトできるリンクをいくつか紹介します。
始めましょう。
1。 SQLクエリの最適化は設計とアーキテクチャから始まります
驚いた? SQLクエリの最適化は、何かが壊れたときの後付けやバンドエイドではありません。クエリは、デザインが許す限り迅速に実行されます。正規化されたテーブル、適切なデータ型、インデックスの使用、古いデータのアーカイブ、および考えられるベストプラクティスのいずれかについて話し合っています。
優れたデータベース設計は、適切なハードウェアおよびSQLServerの設定と相乗効果を発揮します。数年間スムーズに動作し、それでも新しいと感じるように設計しましたか?それは大きな夢ですが、それについて考える時間は一定の(通常は–短い)時間しかありません。
プロダクションの初日は完璧ではありませんが、ベースをカバーする必要がありました。技術的負債を最小限に抑えます。チームで作業している場合、それは1人でのショーと比較して素晴らしいことです。ベルやホイッスルの多くをカバーできます。
それでも、データベースがライブで実行されていて、パフォーマンスの壁にぶつかった場合はどうなりますか? SQLクエリの最適化のヒントとコツをいくつか紹介します。
2。 SQLServer標準レポートで問題のあるクエリを特定する
コーディングするときは、長い一連のコードやストアドプロシージャを簡単に見つけることができます。行ごとにデバッグできます。遅れている線が修正されます。
しかし、ヘルプデスクが遅いために数十枚のチケットを投げた場合はどうなるでしょうか。ユーザーはコード内の正確な場所を特定することはできず、ヘルプデスクも特定できません。時間はあなたの最悪の敵です。
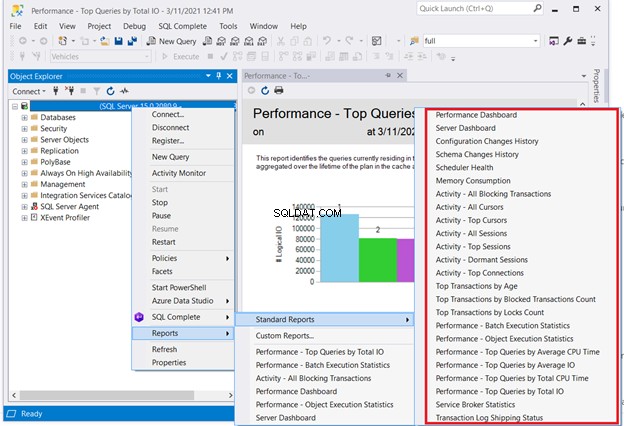
コーディングを必要としないソリューションの1つは、SQLServerの標準レポートを確認することです。 SQL Server Management Studioで必要なサーバーを右クリックします>レポート>標準レポート 。私たちの関心のあるポイントは、パフォーマンスダッシュボードかもしれません またはパフォーマンス–合計I/O別の上位クエリ 。パフォーマンスが悪い最初のクエリを選択します。次に、そこからSQLクエリの最適化またはSQLパフォーマンスの調整を開始します。
3。 STATISTICSIOを使用したSQLクエリの調整
問題のクエリを特定した後、STATISTICSIOで論理読み取りのチェックを開始できます。これはSQLクエリ最適化ツールの1つです。
I / Oポイントはいくつかありますが、論理読み取りに焦点を当てる必要があります。論理読み取りが高いほど、クエリのパフォーマンスに問題が生じます。
次の3つの要素を減らすことで、SQLでのパフォーマンス調整クエリを高速化できます。
- 高い論理読み取り
- 高LOB論理読み取り
- または高いWorkTable/WorkFile論理読み取り。
論理読み取りに関する情報を取得するには、SQL ServerManagementStudioのクエリウィンドウでSTATISTICSIOをオンにします。
統計IOをオンに設定
クエリが完了した後、[メッセージ]タブで出力を取得できます。図2は、出力例を示しています。
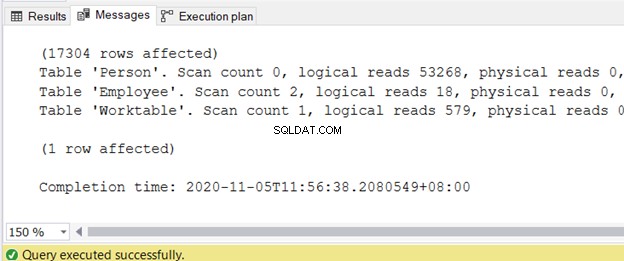
SQLクエリのパフォーマンスを遅らせる3つの厄介なI/O統計で、論理読み取りの削減に関する別の記事を書きました。高い論理読み取りを備えた正確な手順とコードサンプル、およびそれらを減らす方法については、これを参照してください。
4。実行プランを使用したSQLクエリの調整
論理的な読み取りだけでは、全体像を把握することはできません。クエリオプティマイザによって選択された一連の手順により、結果セットのストーリーがわかります。クエリを実行した後、すべてはどのように開始されますか?
以下の図3は、実行をトリガーしてから結果セットを取得するまでの様子を示しています。
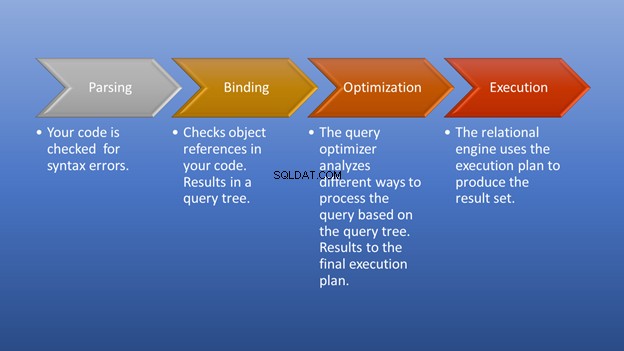
解析とバインドはすぐに実行されます。素晴らしい部分は、私たちの焦点である最適化段階です。この段階で、クエリオプティマイザは、可能な限り最良の実行プランを選択する上で極めて重要な役割を果たします。この部分にはいくらかのリソースが必要ですが、効率的な実行プランを選択することで多くの時間を節約できます。データベースは時間の経過とともに変化するため、これは動的に発生します。このようにして、プログラマーは最終結果を形成する方法に集中できます。
クエリオプティマイザが検討する各プランには、クエリコストがあります。多くのオプションの中で、オプティマイザーは最も妥当なコストのプランを選択します。 注 :リーズナブルなコストは最小コストと同じではありません。また、どのプランが最速の結果を生み出すかを考慮する必要があります。コストが最小のプランが常に最速のプランであるとは限りません。たとえば、オプティマイザは複数のプロセッサコアを利用することを選択できます。これを並列実行と呼びます。これにより、より多くのリソースが消費されますが、シリアル実行と比較して実行速度が速くなります。
考慮すべきもう1つのポイントは統計です。クエリオプティマイザは、実行プランを作成するためにこれに依存しています。統計が古くなっている場合は、クエリオプティマイザからの最良の決定を期待しないでください。
計画が決定され、実行が進むと、結果が表示されます。今何?
SQLServerでクエリ実行プランを検査する
クエリを作成するときは、最初に結果を確認する必要があります。結果は正しくなければなりません。完了したら、完了です。
そうですか?
時間が足りず、仕事が危機に瀕している場合は、それに同意することができます。その上、あなたはいつでも戻ってくることができます。ただし、他の問題が発生した場合は、何度も忘れることができます。そして、過去の幽霊があなたを追い詰めます。
さて、正しい結果を得た後、何をするのが最善ですか?
実際の実行計画を確認します またはライブクエリ統計 !
後者は、クエリの実行が遅く、行が処理されるときに毎秒何が起こるかを確認したい場合に適しています。
時々、状況はあなたに計画をすぐに検査することを強いるでしょう。開始するには、 Control-Mを押します または、実際の実行プランを含めるをクリックします SQL ServerManagementStudioのツールバーから。 dbForge Studio for SQL Serverを使用する場合は、クエリプロファイラーにアクセスしてください。 –SSMSでは見つけることができないのと同じ情報といくつかのベルとホイッスルを提供します。
実際の実行計画を見てきました 。さらに進みましょう。
不足しているインデックスまたはインデックスの推奨事項はありますか?
欠落しているインデックスは簡単に見つけることができます。すぐに警告が表示されます。
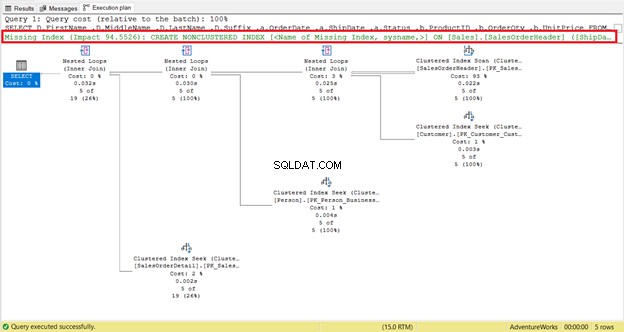
インデックスを作成するためのインスタントコードを取得するには、不足しているインデックスを右クリックします メッセージ(赤で囲まれています)。次に、不足しているインデックスの詳細を選択します 。欠落しているインデックスを作成するためのコードを含む新しいクエリウィンドウが表示されます。インデックスを作成します。
この部分は簡単に理解できます。より高速な実行を実現するための良い出発点です。ただし、効果がない場合もあります。なんで?クエリに必要な一部の列がインデックスに含まれていません。したがって、クラスター化インデックススキャンに戻ります。
インデックスを作成した後、実行プランを再検査して、インクルード列が必要かどうかを確認する必要があります。次に、それに応じてインデックスを調整し、クエリを再実行します。その後、実行計画を再度確認します。
しかし、欠落しているインデックスがない場合はどうなりますか?
実行計画を読む
始めるには、いくつかの基本的なことを知っておく必要があります。
- オペレーター
- プロパティ
- 読み方
- 警告
オペレーター
クエリオプティマイザは、演算子と呼ばれるある種のミニプログラムを使用します。それらのいくつかを図4で確認しました–クラスター化されたインデックスシーク 、クラスター化インデックススキャン 、ネストされたループ 、および選択 。
名前、アイコン、および説明を含む包括的なリストを取得するには、Microsoftのこのリファレンスを確認してください。
プロパティ
グラフィカルな図は、舞台裏で何が起こっているかを理解するのに十分ではありません。各オペレーターのプロパティをより深く掘り下げる必要があります。たとえば、クラスター化インデックススキャン 図4には、次のプロパティがあります。
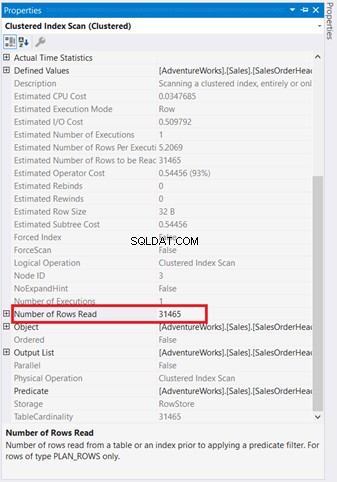
注意深く調べると、クラスター化インデックススキャン オペレーターはひどいです。図5に示すように、31,465行を読み取りましたが、最終的な結果セットは5行にすぎません。そのため、図4には、読み取られる行数を減らすためのインデックスの推奨事項があります。クエリの論理読み取りも高く、これが理由を説明しています。
これらのプロパティの詳細については、一般的なオペレータープロパティとプランプロパティのリストを確認してください。
読み方
一般的に、それは日本のマンガを右から左に読むようなものです。左向きの矢印に従ってください。これは、dbForge Studio forSQLServerの簡単な例です。
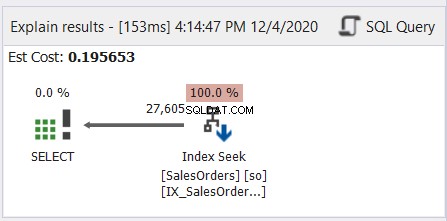
図6に示すように、矢印はIndexSeek演算子からSELECT演算子への左向きです。
ただし、右から左に読むことは必ずしも正しいとは限りません。 SSMSの例を含む図7を参照してください:
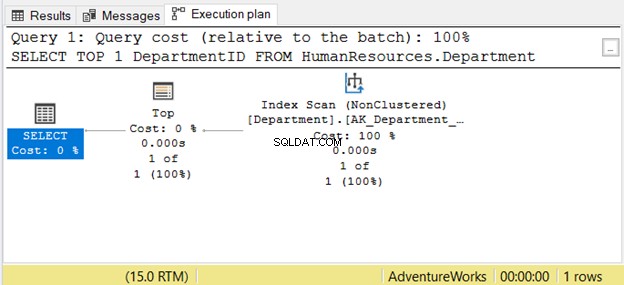
右から左に読むと、インデックススキャンが表示されます。 オペレーター出力は1行のうちの1つです。フェッチする行を1つだけ知るにはどうすればよいでしょうか。 トップのせいです オペレーター。右から左に読むと混乱します。
このケースをよりよく理解するには、「SELECT演算子はTopを使用して、インデックススキャンを使用して1行をフェッチする」と読みます。それは左から右です。
何を使うべきですか?右から左または左から右?
どちらも計画を理解するのに役立ちます。
矢印はデータフローの方向を示していますが、その太さはデータのサイズに関するヒントを示しています。もう一度図4を参照してみましょう。
クラスター化インデックススキャン ネストされたループに移動します 他のものに比べて太い矢印があります。 プロパティ インデックススキャンの詳細 図5で、なぜそれが厚いのかを示しています(5行の最終結果に対して31,465行が読み取られました)。
警告
実行プランオペレーターに表示される警告アイコンは、そのオペレーターで何か問題が発生したことを示しています。これにより、より多くのリソースを消費するため、SQLクエリの最適化が妨げられる可能性があります。
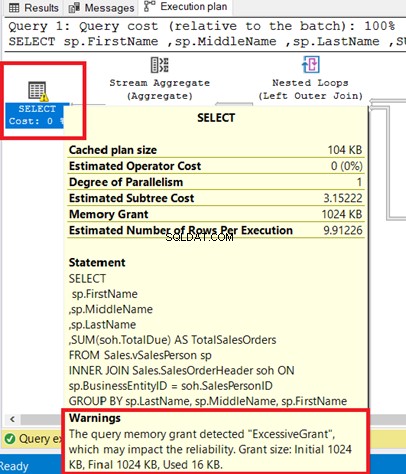
SELECT演算子で警告を確認できます。そのオペレーターにカーソルを合わせると、警告メッセージが表示されます。 ExcessiveGrant この警告が発生しました。
ExcessiveGrant クエリ用に予約されているよりも少ないメモリが使用されている場合に発生します。詳細については、このMicrosoftのドキュメントを参照してください。
図8は、テーブルへのビューの内部結合として使用されるクエリを示しています。ビューの代わりにベーステーブルを結合することで、警告を削除できます。
実行計画を読むための基本的な考え方がわかったので、クエリを遅くする原因を定義する方法を教えてください。
5つの一般的な計画オペレーターの不正を知る
クエリ実行の遅れは犯罪のようなものです。これらの悪党を追いかけて逮捕する必要があります。
1。クラスター化または非クラスター化インデックススキャン
誰もが最初に学ぶ不正はクラスター化です または非クラスター化インデックススキャン 。スキャンは悪く、シークは良いというSQLクエリ最適化の一般的な知識。図4に1つあります。インデックスがないため、クラスター化インデックススキャン 31,465を読み取り、5行を取得します。
ただし、常にそうであるとは限りません。図9の同じテーブルに対する2つのクエリについて考えてみます。1つにはシークがあり、もう1つにはスキャンがあります。
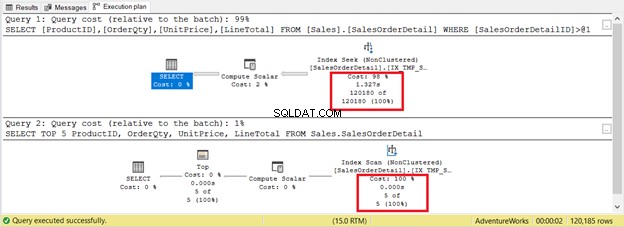
レコード数のみに基づいて基準を設定すると、インデックススキャンは5レコードのみで勝ちますが、120,180レコードで勝ちます。インデックスシークの実行には時間がかかります。
これは、スキャンまたはシークのどちらもほとんど問題にならない別の例です。それらは同じテーブルから同じ6つのレコードを返します。論理読み取りは同じであり、経過時間はどちらの場合もゼロです。テーブルは非常に小さく、6レコードのみです。 実際の実行計画を含める 以下のステートメントを実行します。
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
次に、後で比較するために実行プランを保存します。実行プランを右クリック>名前を付けて実行プランを保存 。
次に、以下のクエリを実行します。
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
次に、実行プランを右クリックして、[ショープランの比較]を選択します。 。次に、前に保存したファイルを選択します。下の図10と同じ出力が得られるはずです。
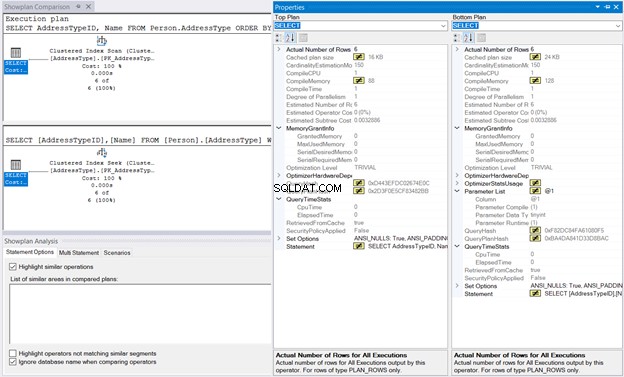
MemoryGrant およびQueryTimeStats 同じだ。 128KBのCompileMemory クラスター化インデックスシークで使用 クラスター化インデックススキャンの88KBと比較 ほとんど無視できます。これらの数字を比較しなければ、実行は同じように感じられます。
2。テーブルスキャンの回避
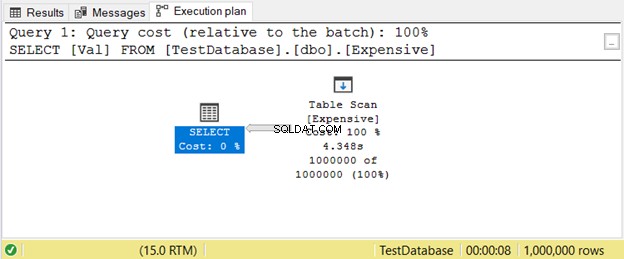
これは、インデックスがない場合に発生します。 SQL Serverは、インデックスを使用して値を探す代わりに、クエリで必要なものが得られるまで行を1つずつスキャンします。これは大きなテーブルではかなり遅れます。簡単な解決策は、適切なインデックスを追加することです。
これは、テーブルスキャンを使用した実行プランの例です。 図11の演算子。
3。ソートパフォーマンスの管理
名前から来ているので、行の順序を変更します。これは費用のかかる操作になる可能性があります。
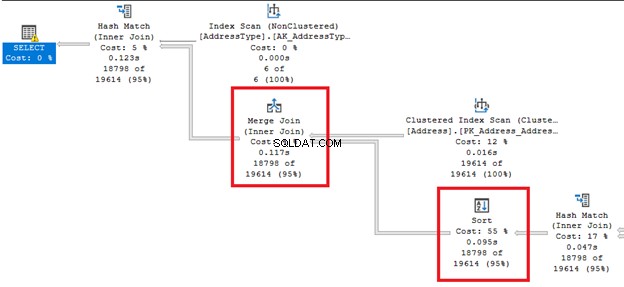
並べ替えの左右から太い矢印の線を見てください オペレーター。クエリオプティマイザがマージ結合を実行することを決定したため 、並べ替え 必要とされている。また、すべてのオペレーターの中で最も高いパーセンテージのコスト(55%)を持っていることにも注意してください。
SQL Serverが行を数回並べ替える必要がある場合、並べ替えはさらに厄介になる可能性があります。テーブルがクエリ要件に基づいて事前にソートされている場合は、この演算子を回避できます。または、1つのクエリを複数のクエリに分割することもできます。
4。キールックアップを排除する
前の図4では、SQLServerは別のインデックスを追加することを推奨していました。私はそれをしました、しかしそれは私が望んでいたものを正確に私に与えませんでした。代わりに、インデックスシークが表示されました キールックアップとペアになっている新しいインデックスに オペレーター。
そのため、新しいインデックスは追加のステップを追加しました。
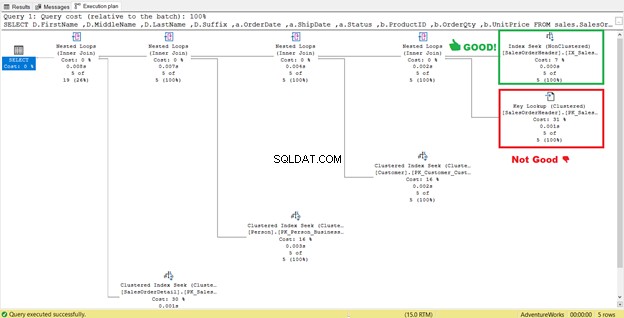
このキールックアップは何ですか オペレーターはしますか?
クエリプロセッサは、図13で緑色のボックスで囲まれた新しい非クラスター化インデックスを使用しました。クエリには新しいインデックスにない列が必要なため、キールックアップを使用してそれらのデータを取得する必要があります。 クラスタ化されたインデックスから。どうやってこれを知るのですか? キールックアップにマウスを合わせる その特性のいくつかを明らかにし、私たちの主張を証明します。
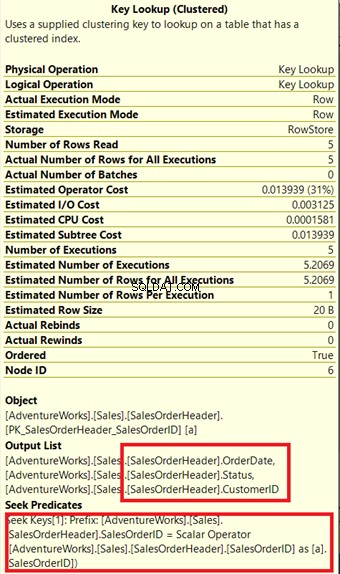
図14で、出力リストに注目してください。 PK_SalesOrderHeader_SalesOrderIDを使用して3つの列を取得する必要があります クラスター化されたインデックス。これを削除するには、これらの列を新しいインデックスに含める必要があります。これらの列が含まれた後の新しい計画は次のとおりです。
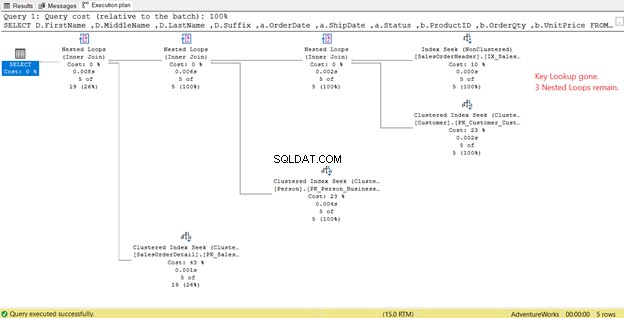
図14では、4つのネストされたループが見られました。 。追加されたキールックアップには4つ目が必要です 。ただし、新しいインデックスに包含列として3列を追加した後、ネストされたループは3つだけになります。 残り、キールックアップ 削除されます。追加の手順は必要ありません。
5。 SQLServer実行プランの並列処理
これまで、シリアル実行で実行プランを見てきました。しかし、これが並列実行を活用する計画です。これは、クエリを実行するためにクエリオプティマイザによって複数のプロセッサが使用されることを意味します。並列実行を使用すると、並列処理が表示されます 計画のオペレーター、およびその他の変更も。
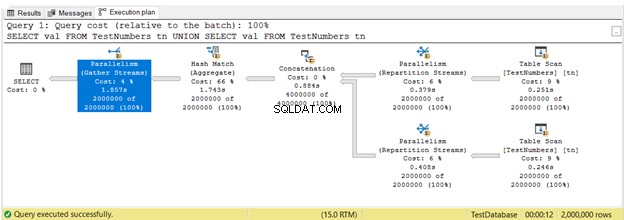
図16では、3並列処理 演算子が使用されました。 テーブルスキャンにも注意してください オペレーターアイコンは少し異なります。これは、並列実行が使用されている場合に発生します。
並列処理は本質的に悪いことではありません。より多くのプロセッサコアを利用することにより、クエリの速度が向上します。ただし、より多くのCPUリソースを使用します。多くのクエリで並列処理を使用すると、サーバーの速度が低下します。 SQLServerの並列処理設定のコストしきい値を確認することをお勧めします。
5。 SQLクエリ最適化のベストプラクティス
これまで、見つけにくい問題を発掘するメソッドを使用してSQLクエリの最適化を扱ってきました。しかし、コードでそれを見つける方法があります。 SQLのコードの臭いは次のとおりです。
SELECT *
の使用急いで?次に、列名を指定するよりも*を入力する方が簡単です。ただし、落とし穴があります。不要な列はクエリより遅れます。
証拠があります。図15で使用したサンプルクエリは次のとおりです。
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
すでに最適化しています。ただし、SELECT *
に変更しましょう。USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
短いですが、以下の実行計画を確認してください:
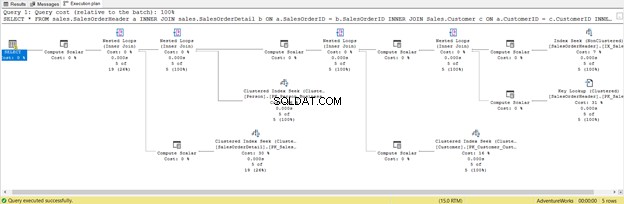
これは、不要な列も含め、すべての列を含めることの結果です。 キールックアップを返しました とたくさんの計算スカラー 。つまり、このクエリは負荷が高く、結果として遅れます。 SELECT演算子の警告にも注意してください。以前はありませんでした。なんて無駄だ!
WHERE句またはJOINの関数
別のコードの臭いは、WHERE句に関数があることです。同じ結果セットを持つ次の2つのSELECTステートメントについて考えてみます。違いはWHERE句にあります。
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
最初のSELECTは、YEARおよびMONTH日付関数を使用して、2011年7月内の出荷日を示します。2番目のSELECTステートメントは、日付リテラルとともにBETWEEN演算子を使用します。
最初のSELECTステートメントには、図4と同様の実行プランがありますが、インデックスの推奨はありません。 2つ目は、図15と同様のより適切な実行プランを持ちます。
最適化された方が明らかです。
ワイルドカードの使用
ワイルドカードはSQLクエリの最適化にどの程度影響しますか?例を挙げましょう。
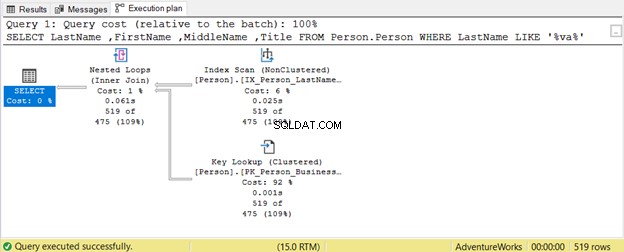
クエリは、姓内の文字列の存在を検索しようとします 任意の位置で。したがって、 Lastname LIKE‘%va%’ 。大きなテーブルでは、その文字列の存在について行が1つずつ検査されるため、これは非効率的です。そのため、インデックススキャン 使用されている。インデックスにタイトルが含まれていないため 列、キールックアップ も使用されます。
これは設計により修正できます。
呼び出し元のアプリはそれを必要としますか?それとも、LIKE‘va%’を使用するだけで十分ですか?
LIKE‘va%’はインデックスシークを使用します テーブルには姓のインデックスがあるためです 、名 、およびミドルネーム 。
また、WHERE句にフィルターを追加して、レコードの読み取りを減らすことはできますか?
これらの質問に対する回答は、このクエリを修正する方法に役立ちます。
暗黙の変換
SQL Serverは、値を比較するときにデータ型を調整するために、バックグラウンドで暗黙的な変換を行います。たとえば、引用符なしで文字列列に番号を割り当てると便利です。しかし、落とし穴があります。 WHERE句で関数を使用した場合の効果も同様です。
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner NVARCHAR(15)ですが、数値と同等です。暗黙的な変換のため、正常に実行されます。ただし、以下の図19の実行プランに注意してください。
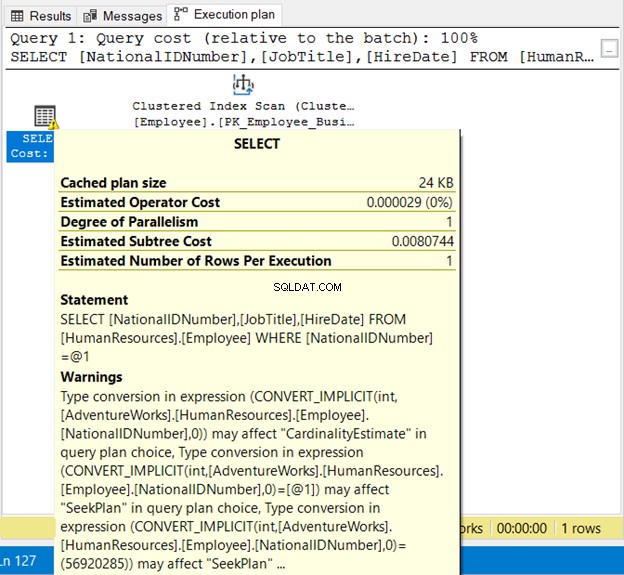
ここに2つの悪いことがあります。まず、警告。次に、インデックススキャン 。暗黙の変換が原因でインデックススキャンが発生しました。したがって、文字列を引用符で囲むか、列と同じデータ型のリテラル値をテストしてください。
SQLクエリ最適化のポイント
それでおしまい。 SQLクエリ最適化の基本により、クエリの準備が少しできたと感じましたか?まとめましょう。
- クエリを最適化する場合は、適切なデータベース設計から始めてください。
- データベースがすでに本番環境にある場合は、SQLServer標準レポートを使用して問題のあるクエリを特定します。
- STATISTICSIOからの論理読み取りを使用した低速クエリの影響の大きさを確認してください。
- 実行計画を使用して、低速クエリのストーリーを深く掘り下げます。
- クエリの速度を低下させる4つのコードの臭いを監視します。
遅いクエリを高速に実行するためのSQLクエリ最適化のヒントは他にもあります。最初に言ったように、これは大きなトピックです。ですから、コメントセクションで他に見逃したことを教えてください。
この投稿が気に入ったら、お気に入りのソーシャルメディアプラットフォームで共有してください。
以前の記事からのSQLクエリ最適化の詳細
さらに例が必要な場合は、SQLServerのクエリ最適化手法に関連するいくつかの役立つ投稿をご覧ください。
- サブクエリはパフォーマンスに悪影響を及ぼしますか? SQLServerでサブクエリを使用する方法に関する簡単なガイドをご覧ください。 。
- HierarchyIDと親/子の設計を使用する–どちらが速いですか? 簡単な例でSQLServerHierarchyIDを使用する方法にアクセスしてください 。
- グラフデータベースクエリは、リアルタイムレコメンデーションシステムで同等のリレーショナルクエリよりも優れたパフォーマンスを発揮できますか? SQLServerグラフデータベースの機能を利用する方法をご覧ください。 。
- どちらが速いですか:COALESCEまたはISNULL? SQLCOALESCE関数に関する5つの質問に対する上位の回答をご覧ください。 。
- SELECTFROMビューとSELECTFROMベーステーブル–どちらが高速に実行されますか? より高速なSQLビューを作成するために知っておく必要のある3つのヒントにアクセスしてください。 。
- CTE対一時テーブル対サブクエリ。 SQLCTEについて知っておくべきことすべてでどちらが勝つかを知る 。
- WHERE句でSQLSUBSTRINGを使用する–パフォーマンストラップ? SQL SUBSTRING()関数を使用してプロのように文字列を解析する方法の例で、それが正しいかどうかを確認してください。
- SQLUNIONALLはUNIONよりも高速です。 SQLUNIONチートシートと10の簡単で便利なヒントで理由を理解してください 。