ROLLUP演算子とCUBE演算子は、GROUPBY句の列によって集計された結果を返すために使用されます。
GROUPING関数とGROUPING_ID関数は、GROUP BYリストの列が(ROLLUPまたはCUBE演算子を使用して)集約されているかどうかを識別するために使用されます。
GROUPING関数とGROUPING_ID関数には2つの大きな違いがあります。
それらは次のとおりです:
- GROUPING関数は単一の列に適用できますが、GROUPING_ID関数の列リストはGROUPBY句の列リストと一致する必要があります。
- GROUPING関数は、GROUPBYリストの列が集約されているかどうかを示します。結果セットが集約されている場合は1を返し、結果セットが集約されていない場合は0を返します。
一方、GROUPING_ID関数も整数を返します。ただし、すべてのGROUPING関数の結果を連結した後、2進数から10進数への変換を実行します。
この記事では、例を使用してGROUPING関数とGROUPING_ID関数の動作を確認します。
ダミーデータの準備
いつものように、この記事で使用する例で使用するダミーデータを作成しましょう。
次のスクリプトを実行します。
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
上記のスクリプトでは、「Company」という名前のデータベースを作成しました。次に、Companyデータベース内にテーブル「Employee」を作成しました。最後に、いくつかのダミーレコードをEmployeeテーブルに挿入しました。
グループ化機能
上記のように、GROUPING関数は、結果セットが集約されている場合は1を返し、結果セットが集約されていない場合は0を返します。
次のスクリプトを見て、GROUPING関数の動作を確認してください。
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
上記のスクリプトは、すべての男性と女性の従業員の給与の合計をカウントします。これらは、最初に部門の列でグループ化され、次に性別の列でグループ化されます。部門と性別の列に適用されたGROUPING関数の結果を表示するために、さらに2つの列が追加されています。
ROLLUP演算子は、給与の合計を総計と小計の形式で表示するために使用されます。
上記のスクリプトの出力は次のようになります。
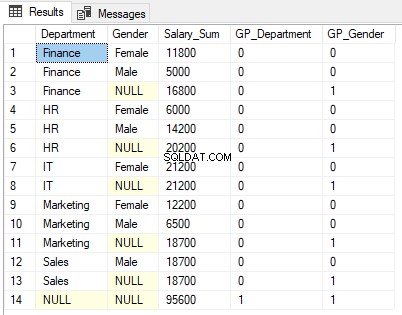
出力を注意深く見てください。給与の合計は、部門の性別(行1、2、4、5、7、9、10、および12)ごとに性別に表示されます。次に、性別のみで集計されます(行3、6、8、11、および13)。最後に、部門と性別の両方で集計された給与の総計が行14に表示されます。
1は、結果が性別ごとに集計される行、つまり行3、6、8、11、および13のGROUPING関数列GP_Genderに表示されます。これは、GP_Gender列にGender列に適用されたGROUPING関数の結果が含まれているためです。
同様に、行14には、すべての部門とすべての列の合計が含まれています。したがって、GP_Department列とGP_Gender列の両方に1が返されます。
結果が集計される出力のDepartment列とGender列にNULLが表示されていることがわかります。たとえば、行3では、結果が性別列ごとに集計され、表示する列値がないため、[性別]列にNULLが表示されます。ユーザーにNULLが表示されないようにするため、ここでのより適切な言葉は「すべての性別」です。
これを行うには、スクリプトを次のように変更する必要があります。
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
上記のスクリプトで、Department列に適用されたGROUPING関数が1を返し、Department列に「AllDepartments」が表示されている場合。それ以外の場合、Department列に値NULLが含まれていると、「Unknown」と表示されます。性別の列も同じように変更されています。
上記のスクリプトを実行すると、次の結果が返されます。
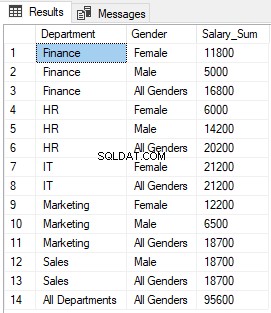
GROUPING関数が1を返すDepartment列とGender列のNULLが、それぞれ「AllDepartments」と「AllGenders」に置き換えられていることがわかります。
GROUPING_ID関数
GROUPING_ID関数は、GROUPBY句で指定されたすべての列に適用されたGROUPING関数の出力を連結します。次に、最終出力を返す前に、2進数から10進数への変換を実行します。
まず、Department列とGender列に適用されたGROUPING関数によって返される出力を連結しましょう。次のスクリプトを見てください:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
出力には、GROUPING関数によって返される0と1が連結されて表示されます。出力は次のようになります:
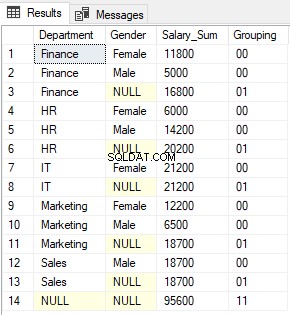
GROUPING_ID関数は、GROUPING関数によって返された値の連結の結果として形成されたバイナリ値に相当する10進数を返すだけです。
次のスクリプトを実行して、GROUPINGID関数の動作を確認します。
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
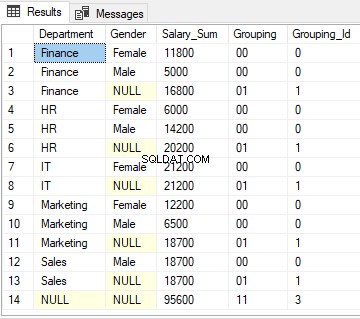
行1の場合、「00」に相当する10進数がゼロであるため、GROUPINGID関数は0を返します。
行3、6、8、11、および13の場合、「01」に相当する10進数は1であるため、GROUPING_ID関数は1を返します。
最後に、行14の場合、「11」に相当するバイナリは3であるため、GROUPIND_ID関数は3を返します。
上記のスクリプトの出力は次のようになります:
関連項目:
Microsoft:Grouping_IDの概要
Microsoft:グループ化の概要
YouTube:Grouping&Grouping_ID