はじめに
テーブルは論理構造です。テーブルを作成するときは、通常、どのドライブがストレージレイヤーに配置されているかは気にしません。ただし、データベース管理者の場合、特定のデータベース部分を別のストレージまたはボリュームに移動する必要がある場合は、この知識が不可欠になる可能性があります。次に、特定のボリュームまたはディスクのセットに明確なテーブルを配置する必要がある場合があります。
SQL Serverのファイルグループは、その抽象化レイヤーを提供し、テーブル、インデックスなどの論理構造の物理的な場所を制御できるようにします。
ファイルグループ
ファイルグループは、SQLServerでデータファイルをグループ化するための論理構造です。ファイルグループを作成し、それをデータファイルのセットに関連付けると、そのファイルグループで作成された論理オブジェクトはすべて、その物理ファイルのセットに物理的に配置されます。
このような物理ファイルのグループ化の主な目的は、データの割り当てと配置です。たとえば、トランザクションデータを1セットの高速ディスクに保存する必要があります。同時に、より安価なディスクの別のセットに保存された履歴データが必要です。このようなシナリオでは、トランを作成します。 TXNファイルグループとTranHistのテーブル 別のHISTファイルグループのテーブル。さらにこの記事では、これがさまざまなディスクにデータを持つことにどのように変換されるかを見ていきます。
ファイルグループの作成
ファイルグループを作成するための構文は、リスト1に示されています。 。 注 :データベースコンテキストはマスター データベース。ステートメントを発行する際に、新しいファイルグループを追加することにより、DB2データベースを変更しています。基本的に、これらのファイルグループは、現時点では単なる論理構造にすぎません。データは含まれていません。
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
ファイルグループへのファイルの追加
次のステップは、各ファイルグループにファイルを追加することです。複数のファイルを追加できますが、デモンストレーション用にシンプルにしています。各ファイルは完全に異なるドライブ上にあり、構文により、目的のファイルグループを指定できることに注意してください。
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
ファイルグループへのテーブルの作成
ここでは、テーブルが目的のディスク上にあることを確認します。テーブルを作成するための構文により、必要なファイルグループを指定できます。
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
一歩後退して、次のことを達成したことに注意してください。
- 2つのファイルグループを作成しました。
- 各ファイルグループに関連付けられているデータファイル(およびディスク)を決定しました。
- 各ファイルグループに関連付けられているテーブルを決定しました。
本質的に、ファイルグループは抽象化レイヤーです 。
テーブルが置かれているファイルグループの確認
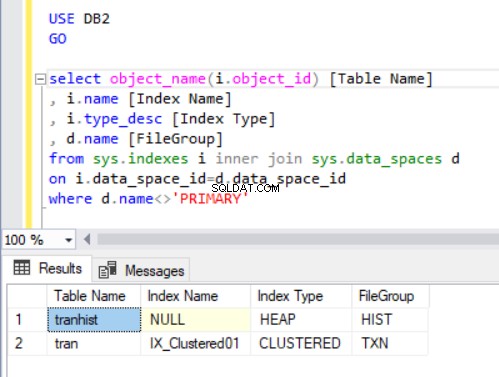
各テーブルがどのファイルグループに属しているかを確認するために、リスト4のコードを実行します。2つのメインシステムカタログビューを使用します: sys.indexes およびsys.data_spaces 。 sys.data_spaces カタログビューには、ファイルグループとパーティション、およびテーブルとインデックスが格納されている主な論理構造に関する情報が含まれています。
注: sys.tablesは使用しませんでした 。 SQL Serverは、直感的に考えるように、テーブル内のインデックスをテーブルではなくデータスペースに関連付けます。
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
リスト4のクエリの出力には、作成した2つのテーブルが表示されます。 tranhist テーブルにはインデックスがありません。それでも、結果セットに表示され、ヒープとして識別されます。 。
ヒープ テーブルに物理的に格納されている注文データを決定するクラスター化インデックスを持たないテーブルです。 1つのテーブルに存在できるクラスター化されたインデックスは1つだけです。
トランテーブルへの入力
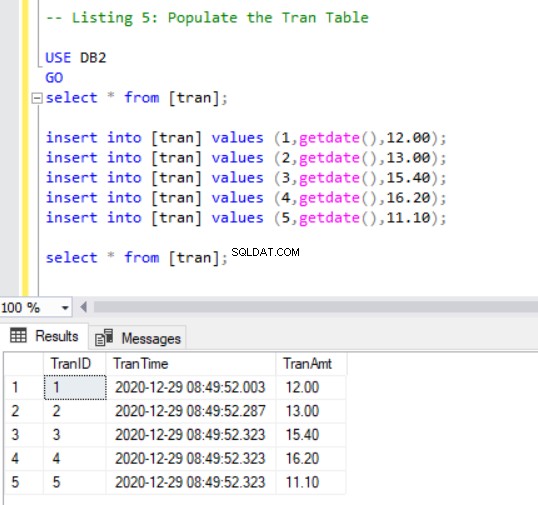
ここで、 tranにいくつかのレコードを追加する必要があります 次のコードを使用したテーブル:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
テーブルを別のファイルグループに移動する
トランを移動するには テーブルを別のファイルグループに追加する場合は、クラスター化インデックスを再構築するだけで済みます。 この再構築を実行するときに、新しいファイルグループを指定します。リスト5はこのアプローチを示しています。
2つのステップを実行します。最初にインデックスを削除し、次にインデックスを再作成します。その間に、前に作成した2つのテーブルのデータと場所がそのまま残っていることを確認します。
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
tranからクラスター化されたインデックスを削除する場合 テーブル、ヒープに変換しました :
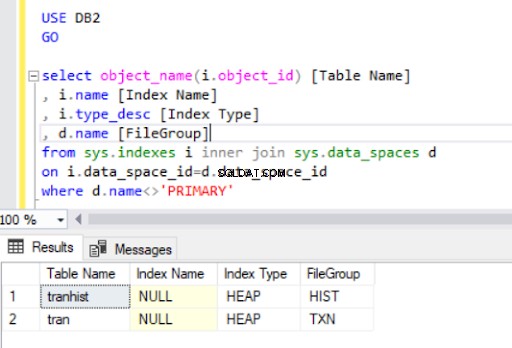
クラスタ化されたインデックスを再作成すると、リスト4の出力にも示されます。
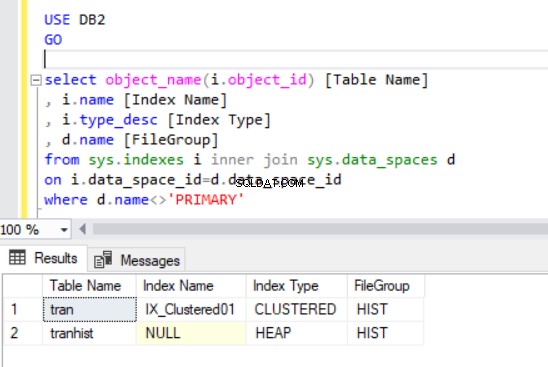
これでtranができました HISTファイルグループのテーブル。
結論
この記事では、SQL Serverデータの保存に関して、テーブル、インデックス、ファイル、およびファイルグループ間の関係を示しました。また、クラスター化されたインデックスを再作成することにより、あるファイルグループから別のファイルグループにテーブルを移動する方法についても説明しました。
このスキルは、データを新しいストレージ(アーカイブ用の高速ディスクまたは低速ディスク)に移行する必要がある場合に役立ちます。より高度なシナリオでは、ファイルグループを使用して、テーブルパーティションを実装することでデータライフサイクルを管理できます。
参照
- データベースファイルとファイルグループ
- テーブルパーティションの切り替え–ウォークスルー