テーブルのインデックス作成戦略は、最も重要なパフォーマンスの調整と最適化の鍵の1つです。 SQL Serverでは、インデックス(クラスター化インデックスと非クラスター化インデックスの両方)はBツリー構造を使用して作成されます。この構造では、各ページが二重にリンクされたリストノードとして機能し、前のページと次のページに関する情報があります。フォワードスキャンと呼ばれるこのBツリー構造により、ページを最初から最後までスキャンまたはシークすることで、インデックスから行を簡単に読み取ることができます。フォワードスキャンはデフォルトでよく知られているインデックススキャン方法ですが、SQL Serverには、Bツリー構造内のインデックス行を最後から最初までスキャンする機能があります。この機能はバックワードスキャンと呼ばれます。この記事では、これがどのように発生するか、および後方スキャン方法の長所と短所を確認します。
SQL Serverには、フォワードスキャン方式を使用してインデックスBツリー構造ノードを最初から最後までスキャンするか、Bツリー構造ノードを最後から最初まで読み取ることにより、テーブルインデックスからデータを読み取る機能があります。後方スキャン方式。名前が示すように、逆方向スキャンは、インデックスに含まれる列の順序とは逆の読み取り中に実行されます。これは、スキャン操作の方向を指定するORDERBYT-SQLソートステートメントのDESCオプションを使用して実行されます。
特定の状況では、SQL Serverエンジンは、逆方向スキャン方式でインデックスデータを最後から最初まで読み取る方が、順方向スキャン方式で通常の順序で読み取るよりも高速であることを検出します。これには、SQLによる高価な並べ替えプロセスが必要になる場合があります。エンジン。このような場合には、MAX()集計関数の使用や、クエリ結果の並べ替えがインデックスの順序と逆になる状況が含まれます。バックワードスキャン方式の主な欠点は、SQL Serverクエリオプティマイザーが、並列実行プランのメリットを享受できずに、常にシリアルプラン実行を使用して実行することを選択することです。
次の表に、会社の従業員に関する情報が含まれていると仮定します。テーブルは、以下のCREATETABLET-SQLステートメントを使用して作成できます。
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
テーブルを作成したら、以下のINSERTステートメントを使用して、テーブルに10Kのダミーレコードを入力します。
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 以下のSELECTステートメントを実行して、以前に作成したテーブルからデータを取得すると、行はID列の値に従って昇順で並べ替えられます。これは、クラスター化されたインデックスの順序と同じです。
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
次に、そのクエリの実行プランを確認し、クラスター化インデックスに対してスキャンを実行して、以下の実行プランに示すように、インデックスから並べ替えられたデータを取得します。
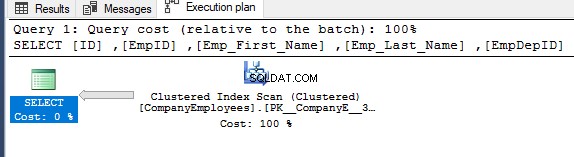
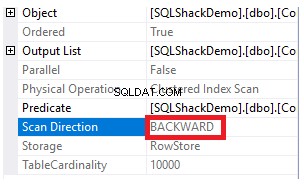
クラスタ化されたインデックスで実行されるスキャンの方向を取得するには、インデックススキャンノードを右クリックしてノードのプロパティを参照します。 Clustered Index Scanノードのプロパティから、Scan Directionプロパティは、そのクエリ内のインデックスで実行されるスキャンの方向を表示します。これは、以下のスナップショットに示すように、フォワードスキャンです。

以下に示すように、インデックススキャン方向は、IndexScanノードの下のScanDirectionプロパティのXML実行プランから取得することもできます。
以下のT-SQLクエリを使用して、前に作成したCompanyEmployeesテーブルから最大ID値を取得する必要があると想定します。
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
次に、そのクエリの実行から生成された実行プランを確認します。以下の実行プランに示すように、クラスター化インデックスに対してスキャンが実行されることがわかります。
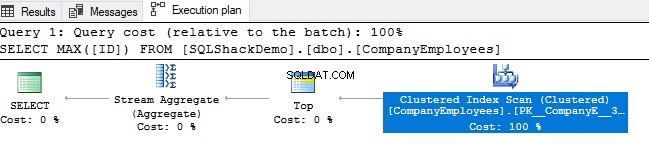
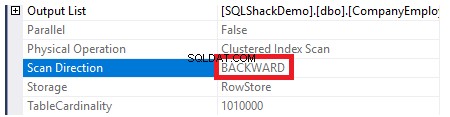
インデックススキャンの方向を確認するために、クラスター化インデックススキャンノードのプロパティを参照します。結果は、SQL Serverエンジンがクラスター化インデックスを最後から最初までスキャンすることを好むことを示しています。この場合、ID列の最大値を取得するために、より高速になります。以下に示すように、インデックスはすでにID列に従ってソートされています。
また、次のSELECTステートメントを使用して以前に作成したテーブルデータを取得しようとすると、レコードはID列の値に従って並べ替えられますが、今回は、クラスター化されたインデックスの順序とは逆に、ORDERでDESC並べ替えオプションを指定します。以下に示すBY句:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
前のSELECTクエリの実行後に生成された実行プランを確認すると、以下に示すように、テーブルの要求されたレコードを取得するために、クラスター化インデックスに対してスキャンが実行されることがわかります。
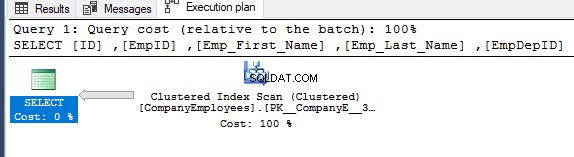
クラスター化インデックススキャンノードのプロパティは、SQL Serverエンジンが実行するスキャンの方向が逆方向スキャン方向であることを示します。これは、クラスター化インデックスの実際の並べ替えとは逆にデータを並べ替えるため、この場合はより高速です。以下に示すように、インデックスはID列に従って昇順で既に並べ替えられていることを考慮に入れてください。
パフォーマンスの比較
2010年以降に2回採用されたすべての従業員に関する情報を取得する、以下のSELECTステートメントがあるとします。 1回目は、返された結果セットがID列の値に従って昇順で並べ替えられ、2回目は、以下のT-SQLステートメントを使用して、返された結果セットがID列の値に従って降順で並べ替えられます。
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
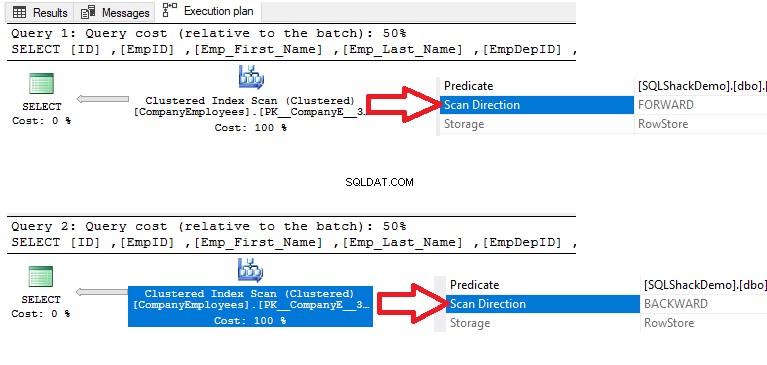
2つのSELECTクエリを実行して生成された実行プランを確認すると、2つのクエリのクラスター化インデックスに対してスキャンが実行されてデータが取得されますが、最初のクエリのスキャンの方向は順方向になります。以下に示すように、ASCデータの並べ替えによるスキャンと、DESCデータの並べ替えを使用した2番目のクエリの逆方向スキャンにより、データを並べ替える必要がなくなります。
また、2つのクエリのIOおよびTIME実行統計を確認すると、両方のクエリが同じIO操作を実行し、実行時間とCPU時間の値に近い値を消費していることがわかります。
これらの値は、以下の統計から明らかなように、ユーザーのデータを取得するために最も適切で最速のインデックススキャン方向を選択するときにSQL Serverエンジンがどれほど賢いかを示しています。最初のケースではフォワードスキャン、2番目のケースではバックワードスキャンです。 :

前のMAXの例にもう一度アクセスしてみましょう。 2010年以降に雇用された従業員の最大IDを取得する必要があると想定します。このために、次のSELECTステートメントを使用して、最初のクエリでASCソートを使用し、2番目のクエリでDESCソートを使用して、ID列の値に従って読み取りデータをソートします。
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO>
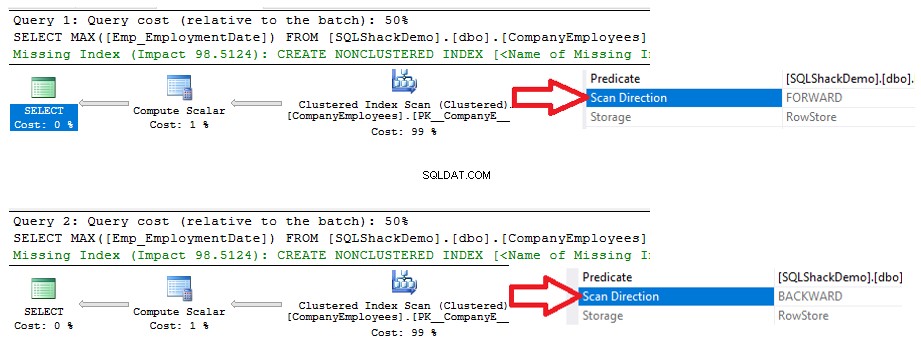
2つのSELECTステートメントの実行から生成された実行プランから、両方のクエリがクラスター化インデックスに対してスキャン操作を実行して最大ID値を取得することがわかりますが、スキャン方向は異なります。以下に示すように、ASCおよびDESCの並べ替えオプションにより、最初のクエリでフォワードスキャン、2番目のクエリでバックワードスキャンが実行されます。
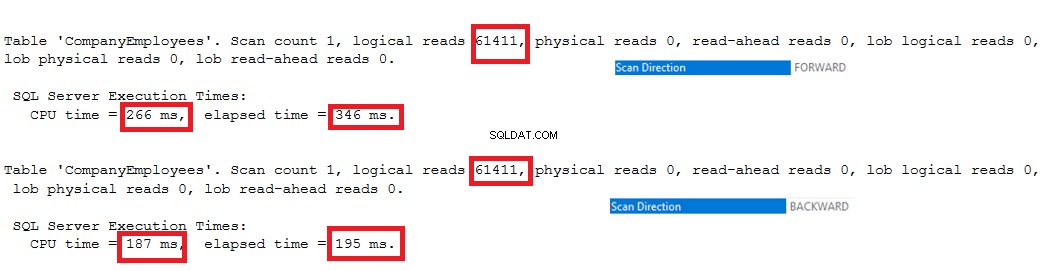
2つのクエリによって生成されたIO統計は、2つのスキャン方向の間に違いを示しません。ただし、TIME統計は、これらの行が順方向スキャン方式を使用して最初から最後までスキャンされる場合と、逆方向スキャン方式を使用して最後から最初までスキャンされる場合の行の最大IDの計算に大きな違いがあることを示しています。以下の結果から、最大ID値を取得するには、後方スキャン方式が最適なスキャン方式であることが明らかです。
パフォーマンスの最適化
この記事の冒頭で述べたように、クエリのインデックス作成は、パフォーマンスの調整と最適化のプロセスにおいて最も重要な鍵です。前のクエリで、以下のCREATE INDEX T-SQLステートメントを使用して、CompanyEmployeesテーブルのEmploymentDate列に非クラスター化インデックスを追加するように調整した場合:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
2つのクエリの実行後に生成された実行プランを確認すると、新しく作成された非クラスター化インデックスに対してシークが実行され、両方のクエリがフォワードスキャンメソッドを使用してインデックスを最初から最後までスキャンすることがわかります。 2番目のクエリでDESC並べ替えオプションを使用しましたが、データ取得を高速化するために後方スキャンを実行する必要があります。これは、以下の実行プランの比較に示すように、完全なインデックススキャンを実行する必要なしにインデックスを直接シークしたために発生しました。
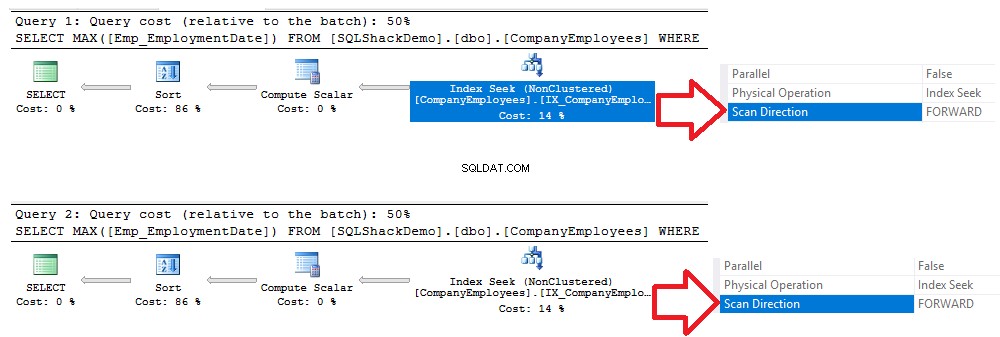
以下の統計スナップショットに示すように、前の2つのクエリから生成されたIOおよびTIME統計から同じ結果を導き出すことができます。この場合、2つのクエリは同じ量の実行時間、CPUおよびIO操作を消費しますが、わずかな違いがあります。 :

便利なツール:
dbForge Index Manager – SQLインデックスのステータスを分析し、インデックスの断片化に関する問題を修正するための便利なSSMSアドイン。