これは、SQL Server InternalsProblematicOperatorsシリーズの一部です。このトピックに関するKalenの最初の投稿と2番目の投稿を必ず読んでください。
SQL Serverは約30年以上前から存在しており、私はSQLServerをほぼ同じくらい長い間使用してきました。私はこの素晴らしい製品の何年にもわたって(そして何十年にもわたって!)そしてバージョンの多くの変化を見てきました。これらの投稿では、SQL Serverの機能や側面のいくつかを、時には歴史的な視点とともにどのように見ているかを紹介します。
前回、SQL Serverのクエリプランでのハッシュについて、SQLServerの診断で問題が発生する可能性のある演算子として説明しました。有用なインデックスがない場合、ハッシュは結合と集約に頻繁に使用されます。そして、スキャン(このシリーズの最初の投稿で話しました)のように、ハッシュが実際には他の方法よりも良い選択である場合があります。ハッシュ結合の場合、代替案の1つはLOOP JOINです。これについては、前回も説明しました。
この投稿では、ハッシュの別の方法について説明します。ハッシュの代替手段のほとんどは、データを並べ替える必要があるため、プランにSORT演算子を含めるか、既存のインデックスのために必要なデータを既に並べ替える必要があります。
SQLServer診断用のさまざまな種類の結合
JOIN操作の場合、最も一般的で便利なタイプのJOINはLOOPJOINです。前回の投稿でLOOPJOINのアルゴリズムについて説明しました。 LOOP JOINの場合、データ自体を並べ替える必要はありませんが、内部テーブルにインデックスが存在すると、結合がはるかに効率的になります。ご存知のとおり、インデックスが存在すると、並べ替えが必要になります。クラスター化インデックスはデータ自体を並べ替えますが、非クラスター化インデックスはインデックスキー列を並べ替えます。実際、ほとんどの場合、インデックスがないと、SQLServerのオプティマイザはHASHJOINアルゴリズムの使用を選択します。前回の例でこれを確認しました。インデックスがない場合はHASHJOINが選択され、インデックスがある場合はLOOPJOINが取得されました。
3番目のタイプの結合はMERGEJOINです。このアルゴリズムは、すでにソートされている2つのデータセットで機能します。すでにソートされている2つのデータセットを結合(または結合)しようとしている場合、一致する行を見つけるために各セットを1回通過するだけです。マージ結合アルゴリズムの擬似コードは次のとおりです。
入力1から最初の行R1を取得
入力2から最初の行R2を取得
どちらの入力の最後でもない
開始
R1がR2と結合する場合
開始
出力(R1、R2)
入力2から次の行R2を取得します
終了
else if R1
入力1から次の行R1を取得します
else
入力2から次の行R2を取得します
終了
MERGE JOINは非常に効率的なアルゴリズムですが、両方の入力データセットを結合キーで並べ替える必要があります。これは通常、両方のテーブルの結合キーにクラスター化インデックスがあることを意味します。テーブルごとに1つのクラスター化インデックスしか取得できないため、MERGE JOINSを実行できるようにするためだけにクラスター化キー列を選択することは、クラスター化キーの全体的な最良の選択ではない可能性があります。
したがって、通常、MERGE JOINSの目的でのみインデックスを作成することはお勧めしませんが、既存のインデックスが原因でMERGE JOINを取得することになった場合は、通常、それは良いことです。 MERGE JOINでは、両方の入力データセットを並べ替える必要があるだけでなく、少なくとも1つのデータセットに結合キーの一意の値が必要です。
例を見てみましょう。まず、ヘッダーを再作成します および詳細 テーブル:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLEIFEXISTSヘッダー;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
次に、これらのテーブル間の結合の計画を見てください。
SELECT *
FROMの詳細dJOINヘッダーh
ONd.SalesOrderID =h.SalesOrderID; GO
計画は次のとおりです:

両方のテーブルにクラスター化インデックスがある場合でも、HASHJOINが取得されることに注意してください。インデックスの1つをUNIQUEに再構築できます。この場合、それはヘッダーのインデックスである必要があります これは、SalesOrderID。に一意の値を持つ唯一のテーブルだからです。
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID)WITH DROP_EXISTING;
GO
ここで、クエリを再度実行し、プランがどのようにMERGEJOINを実行するかを確認します。

これらのプランは、実行プランが並べ替えを利用できるため、データが既にインデックスに並べ替えられているという利点があります。ただし、SQLServerはクエリ実行の一部として並べ替えを実行する必要がある場合があります。並べ替えられた出力を要求しなくても、SORTオペレーターがプランに表示される場合があります。 SQLServerがMERGEJOINが適切なオプションであると考えているが、テーブルの1つに適切なクラスター化インデックスがなく、並べ替えを非常に安価にするのに十分小さい場合は、SORTを実行してMERGEJOINを実行できます。使用済み。
ただし、通常、SORT演算子は、次の例のように、ORDERBYを使用して並べ替えられたデータを要求したクエリに表示されます。
SELECT*FROMの詳細
ORDER BY ProductID;
GO

クラスタ化インデックスがスキャンされ(テーブルのスキャンと同じです)、要求に応じて行が並べ替えられます。
すでにソートされているクラスター化インデックスの処理
しかし、データがクラスター化インデックスで既にソートされていて、クエリにクラスター化キー列にORDERBYが含まれている場合はどうなるでしょうか。上記の例では、DetailsテーブルのSalesOrderIDにクラスター化インデックスを作成しました。次の2つのクエリを見てください。
SELECT * FROM Details;
GO
SELECT*FROMの詳細
ORDER BY SalesOrderID;
GO
これらのクエリを一緒に実行すると、Quest Spotlight Tuning Pack分析ウィンドウは、2つのプランが等しいコストであることを示します。それぞれが全体の50%です。では、実際にはそれらの違いは何ですか?
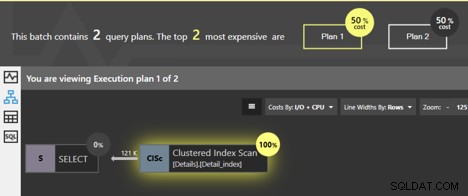
両方のクエリがクラスター化インデックスをスキャンしており、SQL Serverは、リーフレベルのページを順番にたどると、データがクラスター化されたキーの順序で返されることを認識しています。追加の並べ替えを行う必要がないため、SORT演算子はプランに追加されません。しかし、違いがあります。 Clustered Index Scanオペレーターをクリックすると、詳細情報が表示されます。
まず、ORDER BYを使用しないクエリについて、最初のプランの詳細情報を確認します。

詳細は、「Ordered」プロパティがFalseであることを示しています。ここでは、データがソートされた順序で返される必要はありません。ほとんどの場合、データを取得する最も簡単な方法は、クラスター化されたインデックスのページをたどることです。そのため、データは順番に返されますが、保証はありません。 Falseプロパティの意味は、SQLServerが順序付けられたページに従って結果を返す必要がないことです。クラスタ化インデックスに従わずに、SQLServerがテーブルのすべての行を取得できる方法は他にもあります。実行中にSQLServerが別の方法を使用して行を取得することを選択した場合、順序付けられた結果は表示されません。
2番目のクエリの場合、詳細は次のようになります。
 クエリにはORDERBYが含まれているため、データは並べ替えられた順序で返される必要があり、SQL Serverクラスタ化されたインデックスのページを順番にたどります。
クエリにはORDERBYが含まれているため、データは並べ替えられた順序で返される必要があり、SQL Serverクラスタ化されたインデックスのページを順番にたどります。
ここで覚えておくべき最も重要なことは、クエリにORDER BYを含めない場合、並べ替えられたデータは保証されないということです。クラスター化されたインデックスがあるからといって、それでも保証はありません。昨年、クエリを実行するたびに、ORDER BYなしでデータを順番に取得したとしても、データを順番に取得し続けるという保証はありません。 ORDER BYを使用することが、結果が返される順序を保証する唯一の方法です。
並べ替え操作を使用するためのヒント
では、SORTはSQLサーバーの診断で避けるべき操作ですか?スキャンやハッシュ操作と同じように、答えはもちろん「状況によって異なります」です。特に大規模なデータセットでは、並べ替えは非常にコストがかかる可能性があります。インデックスは基本的にデータが事前に並べ替えられていることを意味するため、適切なインデックス作成はSQLServerがSORT操作の実行を回避するのに役立ちます。ただし、インデックス作成にはコストが伴います。すべてのインデックスには、メンテナンスコストに加えて、ストレージコストがあります。データが大幅に更新される場合は、インデックスの数を最小限に抑える必要があります。
実行速度の遅いクエリの一部がプランでSORT操作を示していることがわかり、それらのSORTがプランで最もコストのかかる演算子の中にある場合は、SQLServerが並べ替えを回避できるようにするインデックスの作成を検討できます。ただし、追加のインデックスによって、アプリケーション全体のパフォーマンスに不可欠な他のクエリの速度が低下しないことを確認するために、徹底的なテストを行う必要があります。