グループ化された連結はSQLServerの一般的な問題であり、それをサポートする直接的な意図的な機能はありません(OracleのXMLAGG、PostgreSQLのSTRING_AGGまたはARRAY_TO_STRING(ARRAY_AGG())、MySQLのGROUP_CONCATなど)。これらのConnectアイテムで証明されているように、要求されましたが、まだ成功していません:
- 接続#247118:SQLにはMySQL group_Concat関数のバージョンが必要です(延期)
- Connect#728969:順序集合関数– WITHIN GROUP句(修正されないためクローズ)
**2017年1月の更新** :STRING_AGG()はSQLServer2017に含まれます。ここ、ここ、そしてここでそれについて読んでください。
グループ化された連結とは何ですか?
開始されていないグループ化された連結の場合は、複数行のデータを取得して1つの文字列に圧縮する場合です(通常は、コンマ、タブ、スペースなどの区切り文字を使用します)。これを「水平結合」と呼ぶ人もいます。正規化されたソースから「フラット化された」出力まで、各家族に属するペットのリストを圧縮する方法を示す簡単な視覚的な例:
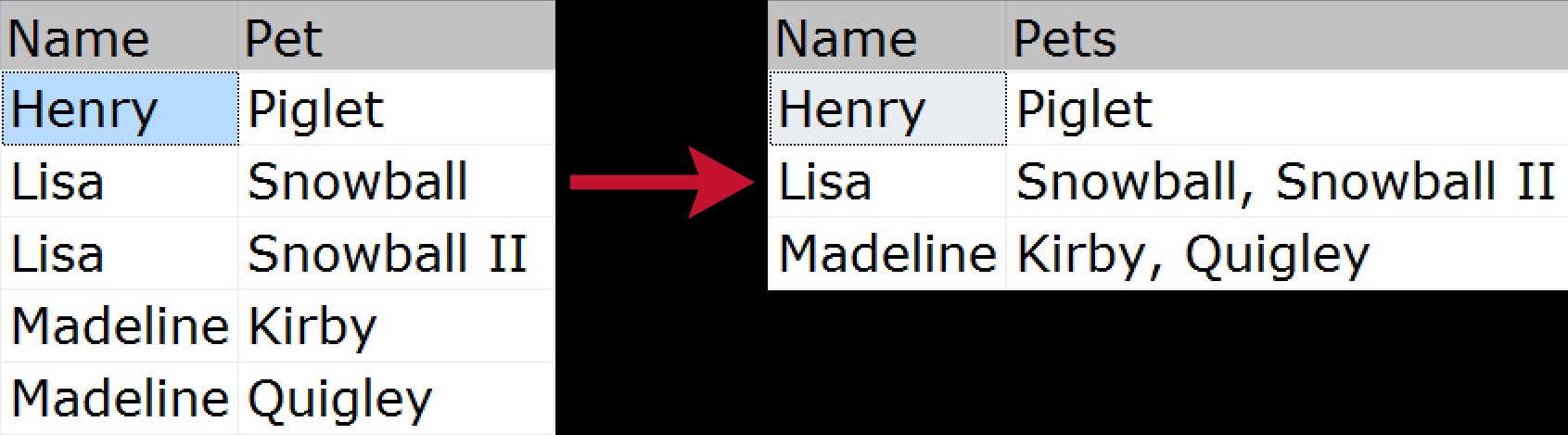
この問題を解決する方法は何年にもわたってたくさんありました。以下のサンプルデータに基づいたほんの数例です:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
推奨されるアプローチのいくつかの側面に焦点を当てたいので、これまでに考えられたすべてのグループ化された連結アプローチの完全なリストを示すつもりはありませんが、より一般的なアプローチのいくつかを指摘したいと思います:
スカラーUDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; 注:これを行わない理由があります:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
DISTINCTを使用 、関数はすべての行に対して実行され、重複が削除されます。 GROUP BYを使用 、重複が最初に削除されます。
共通言語ランタイム(CLR)
これはGROUP_CONCAT_Sを使用します https://groupconcat.codeplex.com/にある関数:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
再帰CTE
この再帰にはいくつかのバリエーションがあります。これは、アンカーとして一連の個別の名前を引き出します:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); カーソル
ここで言うことはあまりありません。通常、カーソルは最適なアプローチではありませんが、SQL Server 2000に固執している場合は、これが唯一の選択肢となる可能性があります。
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO 風変わりなアップデート
このアプローチを*愛する*人もいます。私はその魅力をまったく理解していません。
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; XMLパスの場合
カーソルやCLRを使用せずに注文を*保証*する唯一の方法であるため、私の好みの方法は非常に簡単です。とは言うものの、これは非常に生のバージョンであり、これからさらに説明する他のいくつかの固有の問題に対処できません。
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
多くの人が新しいCONCAT()を誤って想定しているのを見てきました SQL Server 2012で導入された機能は、これらの機能要求に対する答えでした。この関数は、単一行の列または変数に対してのみ機能することを目的としています。行間で値を連結するために使用することはできません。
FORXMLPATHの詳細
FOR XML PATH('') それだけでは十分ではありません–XMLエンティティ化に関する既知の問題があります。たとえば、ペットの名前の1つを更新して、HTMLブラケットまたはアンパサンドを含める場合:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
これらは途中でXMLセーフエンティティに変換されます:
Qui>gle&y
したがって、私は常にPATH, TYPE).value()を使用します 、次のように:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
また、私は常にNVARCHARを使用します 、基になる列にUnicodeが含まれる(または後で変更される)時期がわからないためです。
.value()内に次の種類が表示される場合があります 、または他の人:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
これらは交換可能であり、最終的にはすべて同じ文字列を表します。それらの間のパフォーマンスの違い(以下で詳しく説明します)はごくわずかであり、おそらく完全に非決定的です。
遭遇する可能性のあるもう1つの問題は、XMLで表現できない特定のASCII文字です。たとえば、文字列に文字0x001Aが含まれている場合 (CHAR(26) )、次のエラーメッセージが表示されます:
FOR XMLは、XMLで許可されていない文字(0x001A)が含まれているため、ノード'NoName'のデータをシリアル化できませんでした。 FOR XMLを使用してこのデータを取得するには、データをbinary、varbinary、またはimageデータ型に変換し、BINARYBASE64ディレクティブを使用します。
これは私にはかなり複雑に思えますが、このようなデータを保存していないか、少なくともグループ化された連結で使用しようとしていないため、心配する必要はありません。もしそうなら、他のアプローチの1つにフォールバックする必要があるかもしれません。
パフォーマンス
上記のサンプルデータを使用すると、これらのメソッドがすべて期待どおりに機能することを簡単に証明できますが、意味のある比較は困難です。そこで、テーブルにもっと大きなセットを追加しました:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
私にとって、これは575個のオブジェクトで、合計7,080行でした。最も幅の広いオブジェクトには142列ありました。確かに、SQLServerの歴史の中で考えられたすべてのアプローチを比較しようとはしませんでした。私が上に投稿したいくつかのハイライトだけです。結果は次のとおりです。
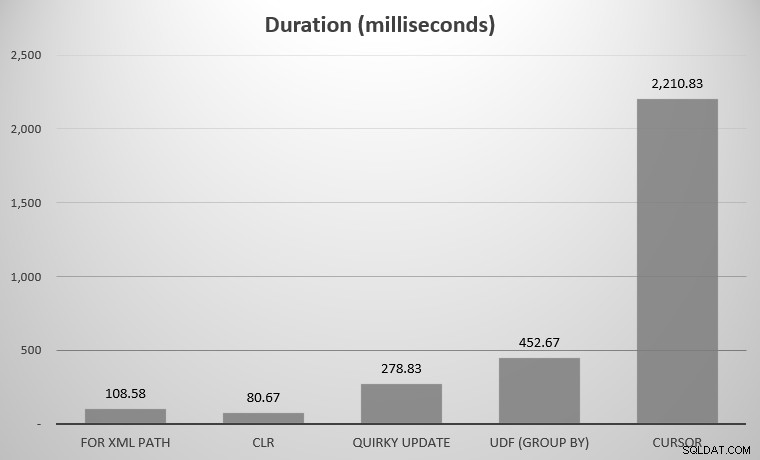
いくつかの候補者が行方不明になっていることに気付くかもしれません。 DISTINCTを使用したUDF 再帰CTEはチャートから外れているため、スケールが歪んでしまいます。表形式の7つのアプローチすべての結果は次のとおりです。
| アプローチ | 期間 (ミリ秒) |
|---|---|
| XMLパスの場合 | 108.58 |
| CLR | 80.67 |
| 風変わりな更新 | 278.83 |
| UDF(GROUP BY) | 452.67 |
| UDF(DISTINCT) | 5,893.67 |
| カーソル | 2,210.83 |
| 再帰CTE | 70,240.58 |
すべてのアプローチの平均継続時間(ミリ秒)
FOR XML PATHのバリエーションにも注意してください 独立してテストされましたが、非常に小さな違いが見られたので、平均のためにそれらを組み合わせました。本当に知りたい場合は、.[1] 私のテストでは、表記法が最も速く機能しました。 YMMV。
結論
CLRが何らかの障害となっているショップにいない場合、特に単純な名前やその他の文字列を扱っているだけではない場合は、CodePlexプロジェクトを検討する必要があります。 CROSS APPLYを作成するために、車輪の再発明を試みたり、直感的でないトリックやハッキングを試みたりしないでください。 または他の構成は、上記の非CLRアプローチよりも少し速く動作します。動作するものを取り出してプラグインするだけです。ソースコードも入手できるので、必要に応じて改良したり拡張したりできます。
CLRが問題になる場合は、FOR XML PATH おそらく最善の選択肢ですが、それでもトリッキーなキャラクターに注意する必要があります。 SQL Server 2000で立ち往生している場合、実行可能な唯一のオプションはUDF(またはUDFでラップされていない同様のコード)です。
次回
後続の投稿で調べたいことがいくつかあります。リストから重複を削除する、値自体以外の順序でリストを並べ替える、これらのアプローチのいずれかをUDFに組み込むのが難しい場合、実際のユースケースこの機能のために。