 新しいバージョンのSQLServerを利用できるのは素晴らしいことではありませんか?これは2、3年ごとにのみ発生することであり、今月は1つが一般提供に到達するのを見ました。 (わかりました。Azureで新しいバージョンのSQLデータベースをほぼ継続的に入手していることはわかっていますが、これは異なるものとしてカウントします。) この新しいリリースを認めて、今月のT-SQL Tuesday(Michael Swart – @mjswartがホスト)は、SQL Server 2016のすべてのトピックについて取り上げています!
新しいバージョンのSQLServerを利用できるのは素晴らしいことではありませんか?これは2、3年ごとにのみ発生することであり、今月は1つが一般提供に到達するのを見ました。 (わかりました。Azureで新しいバージョンのSQLデータベースをほぼ継続的に入手していることはわかっていますが、これは異なるものとしてカウントします。) この新しいリリースを認めて、今月のT-SQL Tuesday(Michael Swart – @mjswartがホスト)は、SQL Server 2016のすべてのトピックについて取り上げています!
そこで、今日はSQL 2016の時間テーブル機能を確認し、最終的に表示される可能性のあるクエリプランの状況を確認したいと思います。私はTemporalTablesが大好きですが、気を付けたいと思うかもしれないちょっとした落とし穴に出くわしました。
現在、SQL Server 2016がRTMになっているにもかかわらず、AdventureWorks2016CTP3を使用しています。これは、ここからダウンロードできますが、AdventureWorks2016CTP3.bakをダウンロードするだけではありません。 、SQLServer2016CTP3Samples.zipも取得します 同じサイトから。
ご覧のとおり、サンプルアーカイブには、時間テーブル用など、新機能を試すための便利なスクリプトがいくつかあります。これは双方にメリットがあります。たくさんの新機能を試すことができます。この投稿では、それほど多くのスクリプトを繰り返す必要はありません。とにかく、AW 2016 CTP3 Temporal Setup.sqlを実行して、TemporalTablesに関する2つのスクリプトを入手してください。 、続いてTemporal System-Versioning Sample.sql 。
これらのスクリプトは、HumanResources.Employeeを含むいくつかのテーブルの一時的なバージョンを設定します 。 HumanResources.Employee_Temporalを作成します (ただし、技術的には、何とでも呼ばれる可能性があります)。 CREATE TABLEの最後に ステートメントの場合、このビットが表示され、行が有効であるかどうかを示すために使用する2つの非表示の列が追加され、HumanResources.Employee_Temporal_Historyというテーブルを作成する必要があることが示されます。 古いバージョンを保存します。
... ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [HumanResources].[Employee_Temporal_History]) );
この投稿で調べたいのは、履歴が使用されたときにクエリプランで何が起こるかです。
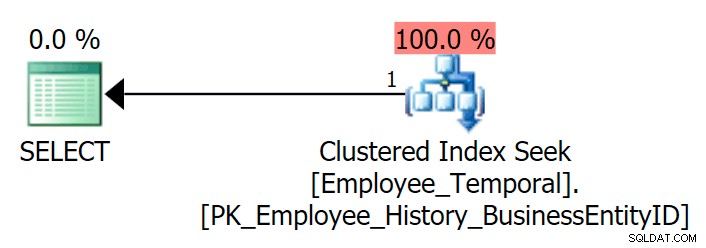
テーブルをクエリして、特定のBusinessEntityIDの最新の行を確認すると 、期待どおり、クラスター化インデックスシークを取得します。
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo FROM HumanResources.Employee_Temporal AS e WHERE e.BusinessEntityID = 4;
他のインデックスがあれば、それを使用してこのテーブルをクエリできると確信しています。しかし、この場合はそうではありません。作成しましょう。
CREATE UNIQUE INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
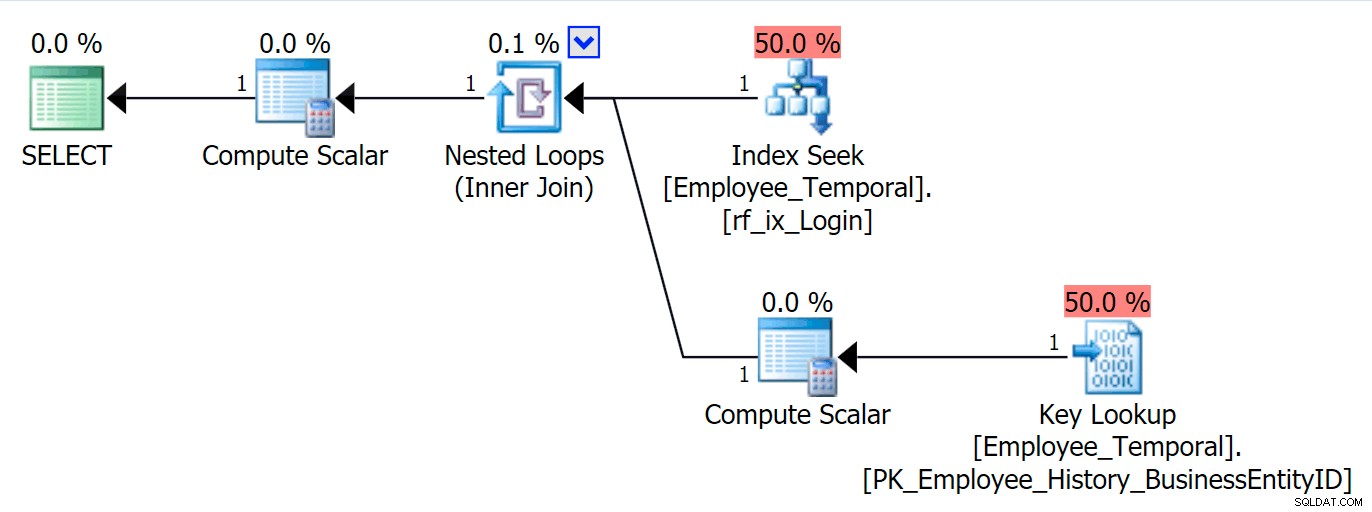
これで、LoginIDでテーブルをクエリできます。 、Loginid以外の列を要求すると、キールックアップが表示されます またはBusinessEntityID 。これは驚くべきことではありません。
SELECT * FROM HumanResources.Employee_Temporal e WHERE e.LoginID = N'adventure-works\rob0';
SQL Server Management Studioを少し使用して、このテーブルがオブジェクトエクスプローラーでどのように表示されるかを見てみましょう。

HumanResources.Employee_Temporalの下に記載されている履歴テーブルを確認できます。 、およびテーブル自体と履歴テーブルの両方からの列とインデックス。ただし、適切なテーブルのインデックスは主キー(BusinessEntityID上)です。 )と作成したばかりのインデックスで、履歴テーブルに一致するインデックスがありません。
履歴テーブルのインデックスはValidToにあります およびValidFrom 。インデックスを右クリックして[プロパティ]を選択すると、次のダイアログが表示されます:
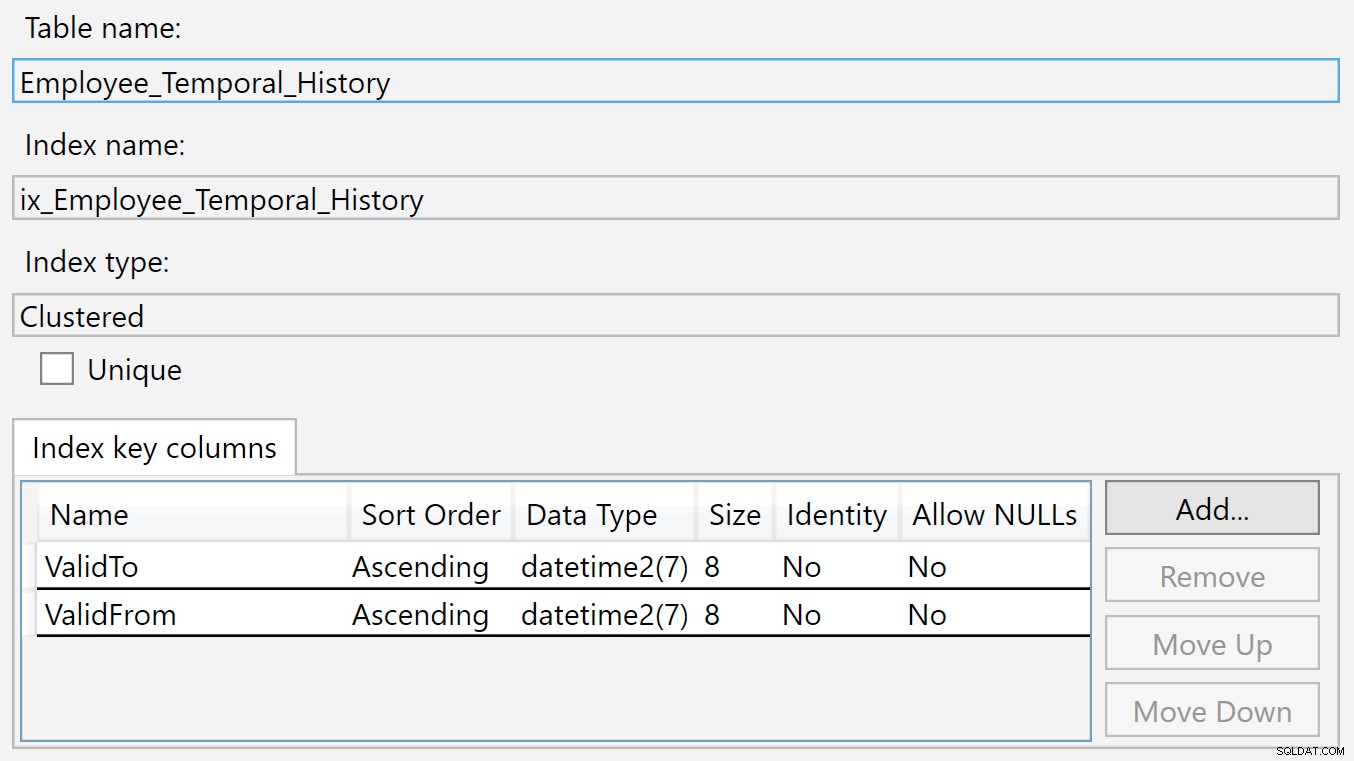
新しい行は、削除または変更されたばかりであるため、メインテーブルで無効になると、この履歴テーブルに挿入されます。 ValidToの値 列には現在の時刻が自然に入力されるため、ValidTo ID列のように昇順キーとして機能するため、bツリー構造の最後に新しい挿入が表示されます。
しかし、テーブルをクエリする場合、これはどのように機能しますか?
特定の時点で何が最新であったかをテーブルにクエリする場合は、次のようなクエリ構造を使用する必要があります。
SELECT * FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22';
このクエリは、メインテーブルの適切な行を履歴テーブルの適切な行と連結する必要があります。
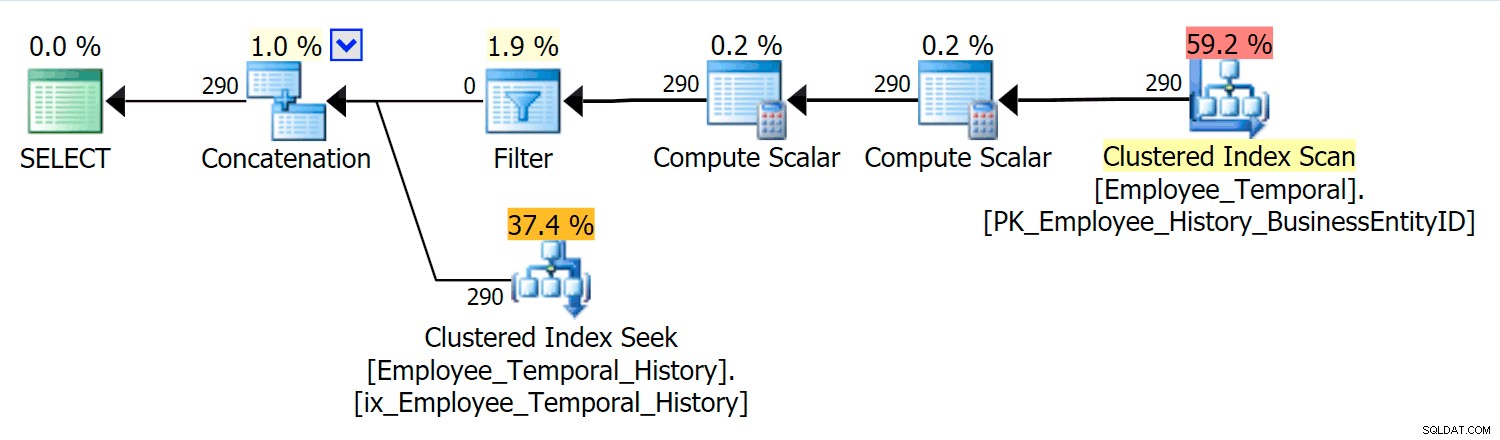
このシナリオでは、選択した時点で有効な行はすべて履歴テーブルからのものでしたが、それでも、フィルター演算子によってフィルター処理されたメインテーブルに対するクラスター化インデックススキャンが表示されます。このフィルターの述語は次のとおりです。
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
すぐにもう一度見てみましょう。
履歴テーブルのクラスター化インデックスシークは、ValidToのシーク述語を明確に活用している必要があります。シークの範囲スキャンの開始はHumanResources.Employee_Temporal_History.ValidToです。 >スカラー演算子( '2016-06-12 11:22:00') 、ただし、ValidToを持つすべての行があるため、Endはありません。 気になる時間の後は候補行であり、適切なValidFromをテストする必要があります HumanResources.Employee_Temporal_History.ValidFromである残差述語による値 <= '2016-06-12 11:22:00' 。
現在、間隔のインデックスを作成するのは困難です。これは、多くのブログで議論されている既知のことです。最も効果的なソリューションは、クエリを作成するための創造的な方法を検討しますが、そのようなスマートは時間テーブルに組み込まれていません。ただし、ValidFromなどの他の列にインデックスを配置したり、メインテーブルにある可能性のあるクエリのタイプに一致するインデックスを設定したりすることもできます。クラスタ化されたインデックスが両方のValidToの複合キーである場合 およびValidFrom 、これらの2つの列は、1つおきの列に含まれるため、残余述語のテストに適しています。
興味のあるログインIDがわかっている場合、私の計画は別の形になります。
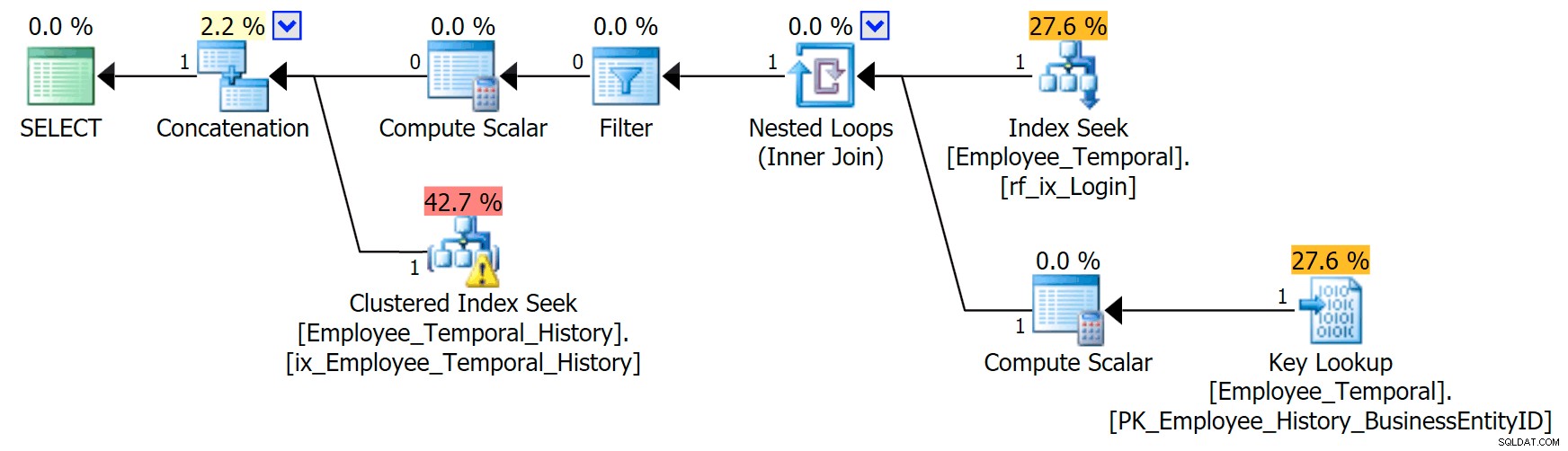
連結演算子の上のブランチは以前と同じように見えますが、そのフィルターオペレーターは無効な行を削除するために争いに入っていますが、下のブランチのクラスター化インデックスシークには警告があります。これは、私の以前の投稿の例のように、残余述語の警告です。気になる時間の後のある時点まで有効なエントリにフィルタリングできますが、ResidualPredicateはLoginIDにフィルタリングされるようになりました。 ValidFrom 。
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
rob0の行への変更は、履歴内の行のごく一部になります。行が複数回変更されている可能性があるため、この列はメインテーブルのように一意ではありませんが、インデックスを作成するのに適した候補がまだあります。
CREATE INDEX rf_ixHist_loginid ON HumanResources.Employee_Temporal_History(LoginID);
この新しいインデックスは、私たちの計画に顕著な影響を及ぼします。
クラスター化インデックスシークがクラスター化インデックススキャンに変更されました!!
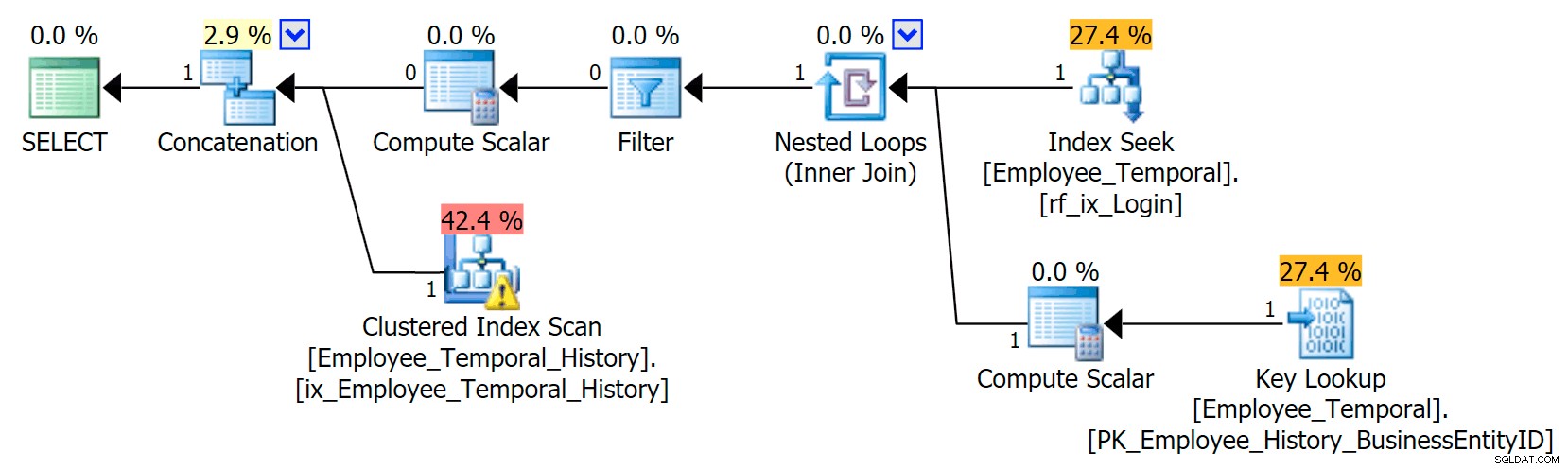
ご覧のとおり、クエリオプティマイザは、新しいインデックスを使用するのが最善の方法であると判断しました。しかし、他のすべての列を取得するためにルックアップを実行する必要があるという作業(すべての列を要求していたため)は、単純に手間がかかりすぎることも決定します。転換点に到達し(この場合、残念ながら誤った仮定)、代わりにクラスター化インデックスSCANが選択されました。非クラスター化インデックスがない場合でも、クラスター化インデックスシークを使用するのが最善のオプションでしたが、非クラスター化インデックスが考慮され、転換点の理由で拒否された場合、スキャンを選択します。
苛立たしいことに、私はこのインデックスを作成したばかりであり、その統計は良好なはずです。正確に1回のルックアップを必要とするシークは、クラスター化インデックススキャンよりも優れている必要があることを知っておく必要があります(統計のみ-LoginIDのため、これを知っている必要があると考えている場合 メインテーブルで一意であるため、常にそうであるとは限らないことに注意してください)。ですから、私はまだ十分な調査を行っていませんが、履歴テーブルでの検索は避けるべきだと思います。
非クラスター化インデックスに表示される列のみをクエリすると、動作が大幅に向上します。ルックアップが不要になったので、履歴テーブルの新しいインデックスがうまく使用されます。 LoginIDにのみフィルタリングできることに基づいて、ResidualPredicateを適用する必要があります。 およびValidTo 、ただし、クラスター化インデックススキャンにドロップするよりもはるかに優れた動作をします。
SELECT LoginID, ValidFrom, ValidTo FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22' WHERE LoginID = N'adventure-works\rob0'
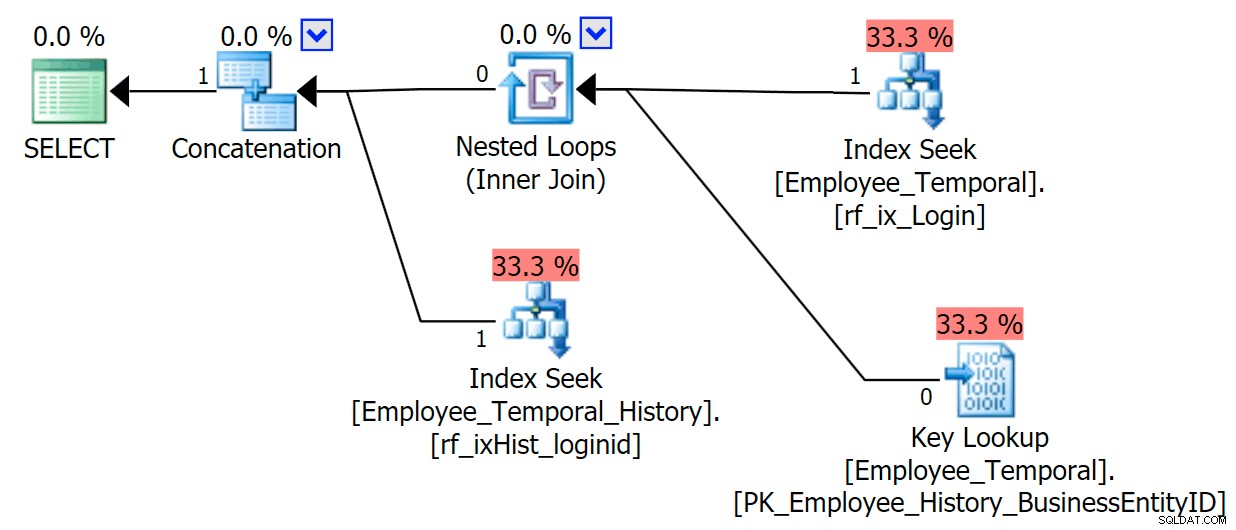
したがって、履歴テーブルをクエリする方法を考慮して、追加の方法で履歴テーブルにインデックスを付けてください。スキャンを実際に回避しているため、ルックアップを回避するために必要な列を含めます。
データが頻繁に変更される場合、これらの履歴テーブルは大きくなる可能性があります。したがって、それらがどのように処理されているかに注意してください。これと同じ状況は、他のFOR SYSTEM_TIMEを使用する場合にも発生します。 構築するため、(いつものように)クエリが作成している計画を確認し、インデックスを作成して、SQLServer2016の非常に強力な機能を活用できる位置にいることを確認する必要があります。