質問の核心は、「なぜLINQで順序が重要なのか」ではありません。 LINQは、並べ替えることなく文字通り翻訳するだけです。本当の問題は、「2つのSQLクエリのパフォーマンスが異なるのはなぜですか?」です。
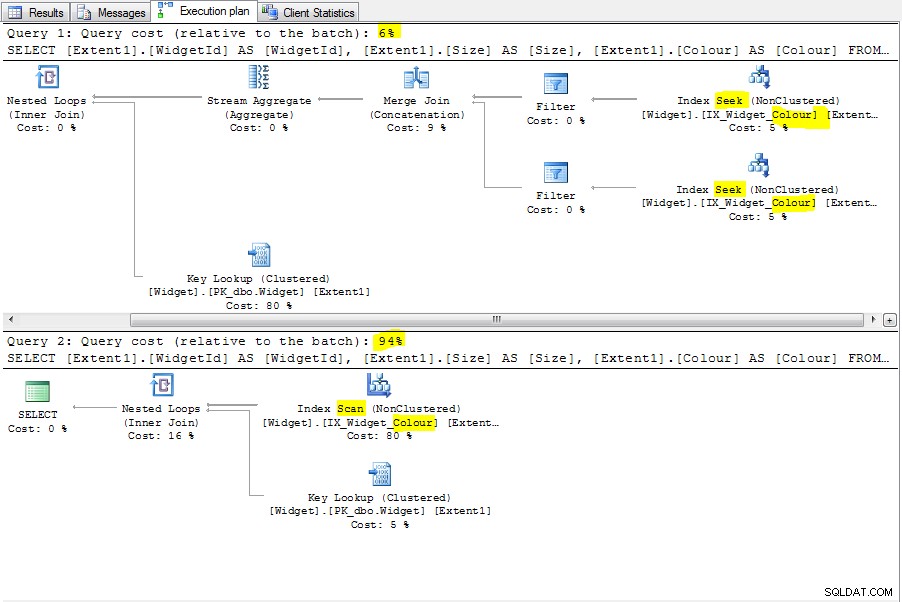
10万行挿入するだけで問題を再現できました。その場合、オプティマイザーの弱点がトリガーされています。オプティマイザーは、Colourでシークを実行できることを認識しません。 複雑な状態のため。最初のクエリでは、オプティマイザはパターンを認識し、インデックスシークを作成します。
これが必要な意味上の理由はありません。 NULLでシークする場合でも、インデックスでのシークが可能です。 。これはオプティマイザの弱点/バグです。 2つの計画は次のとおりです。
EFは、列とフィルター変数の両方がnullになる可能性があることを前提としているため、ここで役立つように努めています。その場合、それはあなたに一致を与えようとします(C#セマンティクスによればこれは正しいことです)。
次のフィルターを追加して、元に戻してみました:
Colour IS NOT NULL AND @p__linq__0 IS NOT NULL
AND Size IS NOT NULL AND @p__linq__1 IS NOT NULL
オプティマイザーがその知識を使用して、複雑なEFフィルター式を単純化することを期待しています。それはなんとかそうすることができませんでした。これが機能していれば、同じフィルターをEFクエリに追加して、簡単に修正できたはずです。
試してみるべき順序で私が推奨する修正は次のとおりです。
- データベース内のデータベース列をnull以外にする
- EFが複雑なフィルター条件を作成するのを防ぐことを期待して、EFデータモデルの列をnull以外にします
- インデックスの作成:
Colour, Sizeおよび/またはSize, Colour。また、問題を取り除きます。 - フィルタリングが正しい順序で行われていることを確認し、コードコメントを残します
-
INTERSECTを使用してみてください /Queryable.Intersectフィルタを組み合わせる。これにより、多くの場合、プランの形状が異なります。 - フィルタリングを行うインラインテーブル値関数を作成します。 EFは、このような関数をより大きなクエリの一部として使用できます
- 生のSQLにドロップダウン
- 計画ガイドを使用して計画を変更する
これらはすべて回避策であり、根本的な原因の修正ではありません。
結局、ここではSQLServerとEFの両方に満足していません。両方の製品を修正する必要があります。残念ながら、彼らはおそらくそうではなく、あなたもそれを待つことはできません。
インデックススクリプトは次のとおりです。
CREATE NONCLUSTERED INDEX IX_Widget_Colour_Size ON dbo.Widget
(
Colour, Size
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
CREATE NONCLUSTERED INDEX IX_Widget_Size_Colour ON dbo.Widget
(
Size, Colour
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]