その理由は、これを実装する価値のある優先機能とは考えていなかったためだと思います。 Postgres does 両方をサポート
UNION およびUNION ALL 。
この機能の強力なケースがある場合は、接続 でフィードバックを提供できます。 (またはその置換のURLが何であれ)。
重複が追加されないようにすることは、後のステップで前の行に追加された重複行がほとんどの場合、無限ループを引き起こしたり、最大再帰制限を超えたりするため、役立つ可能性があります。
SQL標準
にはかなりの数の場所があります UNIONを示すコードが使用されている場所 以下のような
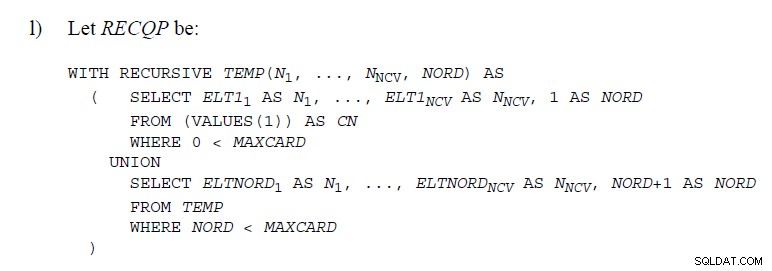
この記事では、SQLServerでの実装方法について説明します 。彼らは「内部」でそのようなことをしていません。スタックスプールは行を途中で削除するため、後の行が削除された行と重複しているかどうかを知ることはできません。 UNIONのサポート 多少異なるアプローチが必要になります。
それまでの間、マルチステートメントTVFでも同じことを簡単に実現できます。
以下のばかげた例を見てみましょう( Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
UNIONの変更 UNION ALLへ DISTINCTを追加します 最後に、無限の再帰からあなたを救うことはありません。
ただし、これは次のように実装できます
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
上記はIGNORE_DUP_KEYを使用しています 重複を破棄します。列リストが広すぎてインデックスを作成できない場合は、DISTINCTが必要になります。 およびNOT EXISTS 代わりは。また、再帰の最大数を設定し、無限ループを回避するためのパラメーターも必要になる可能性があります。