SQL Server オプティマイザには冗長な結合を削除するロジックが含まれていますが、制限があり、結合は おそらく冗長 .まとめると、結合には次の 4 つの効果があります。
<オール>NULL を導入できます s (RIGHT の場合) または FULL JOIN )冗長な結合を正常に削除するには、クエリ (またはビュー) で 4 つの可能性すべてを考慮する必要があります。これが正しく行われると、驚くべき効果が得られます。例:
USE AdventureWorks2012; GO CREATE VIEW dbo.ComplexView AS SELECT pc.ProductCategoryID, pc.Name AS CatName, ps.ProductSubcategoryID, ps.Name AS SubCatName, p.ProductID, p.Name AS ProductName, p.Color, p.ListPrice, p.ReorderPoint, pm.Name AS ModelName, pm.ModifiedDate FROM Production.ProductCategory AS pc FULL JOIN Production.ProductSubcategory AS ps ON ps.ProductCategoryID = pc.ProductCategoryID FULL JOIN Production.Product AS p ON p.ProductSubcategoryID = ps.ProductSubcategoryID FULL JOIN Production.ProductModel AS pm ON pm.ProductModelID = p.ProductModelIDオプティマイザは次のクエリを正常に単純化できます:
SELECT c.ProductID, c.ProductName FROM dbo.ComplexView AS c WHERE c.ProductName LIKE N'G%';宛先:
Rob Farley は、元の MVP Deep Dives book でこれらのアイデアについて詳しく書いています。 、そして彼がトピックについてプレゼンテーションを行っている記録 があります
主な制限は、外部キー関係 単一のキーに基づいている必要があります 特に結合の数が増えると、そのようなビューに対するクエリのコンパイル時間が非常に長くなる可能性があります。すべてのセマンティクスを正確に取得する 100 テーブルのビューを作成することは、非常に困難な作業になる可能性があります。おそらく 動的 SQL を使用して、別の解決策を見つけたいと思います。 .
そうは言っても、非正規化されたテーブルの特定の品質は、ビューの組み立てが非常に簡単であり、強制された
FOREIGN KEYsのみを必要とすることを意味する場合があります。 非NULL可能な参照列、および適切なUNIQUE計画で 100 の物理結合演算子のオーバーヘッドなしで、このソリューションを希望どおりに機能させるための制約。例
100 個ではなく 10 個のテーブルを使用:
-- Referenced tables CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE); CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);親テーブルの定義 (ページ圧縮あり):
CREATE TABLE dbo.Normalized ( pk integer IDENTITY NOT NULL, col01 tinyint NOT NULL REFERENCES dbo.Ref01, col02 tinyint NOT NULL REFERENCES dbo.Ref02, col03 tinyint NOT NULL REFERENCES dbo.Ref03, col04 tinyint NOT NULL REFERENCES dbo.Ref04, col05 tinyint NOT NULL REFERENCES dbo.Ref05, col06 tinyint NOT NULL REFERENCES dbo.Ref06, col07 tinyint NOT NULL REFERENCES dbo.Ref07, col08 tinyint NOT NULL REFERENCES dbo.Ref08, col09 tinyint NOT NULL REFERENCES dbo.Ref09, col10 tinyint NOT NULL REFERENCES dbo.Ref10, CONSTRAINT PK_Normalized PRIMARY KEY CLUSTERED (pk) WITH (DATA_COMPRESSION = PAGE) );ビュー:
CREATE VIEW dbo.Denormalized WITH SCHEMABINDING AS SELECT item01 = r01.item, item02 = r02.item, item03 = r03.item, item04 = r04.item, item05 = r05.item, item06 = r06.item, item07 = r07.item, item08 = r08.item, item09 = r09.item, item10 = r10.item FROM dbo.Normalized AS n JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01 JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02 JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03 JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04 JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05 JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06 JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07 JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08 JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09 JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;テーブルが非常に大きいとオプティマイザに認識させるために、統計をハックします:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;ユーザー クエリの例:
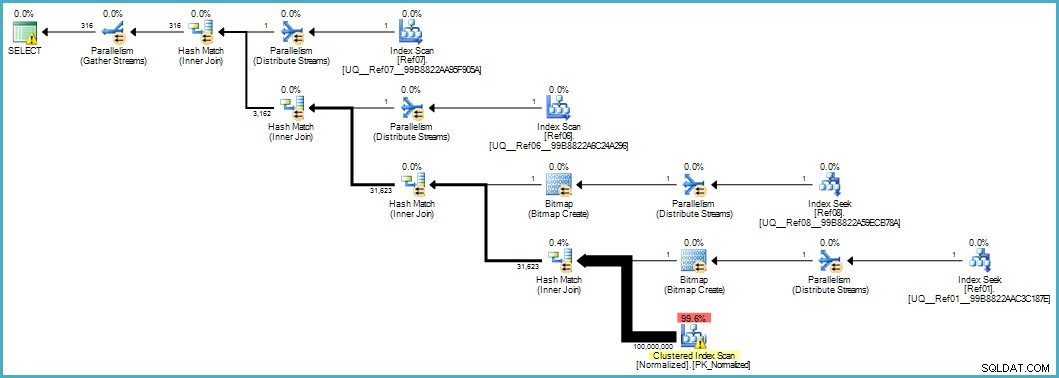
SELECT d.item06, d.item07 FROM dbo.Denormalized AS d WHERE d.item08 = 'Banana' AND d.item01 = 'Green';この実行計画が表示されます:
正規化されたテーブルのスキャンは悪いように見えますが、両方のブルーム フィルター ビットマップがストレージ エンジンによるスキャン中に適用されます (そのため、一致しない行はクエリ プロセッサまでは表示されません)。これは、あなたのケースでは許容できるパフォーマンスを提供するのに十分であり、オーバーフローした列で元のテーブルをスキャンするよりも確実に優れています.
ある段階で SQL Server 2012 Enterprise にアップグレードできる場合は、別のオプションがあります:正規化されたテーブルに列ストア インデックスを作成します:
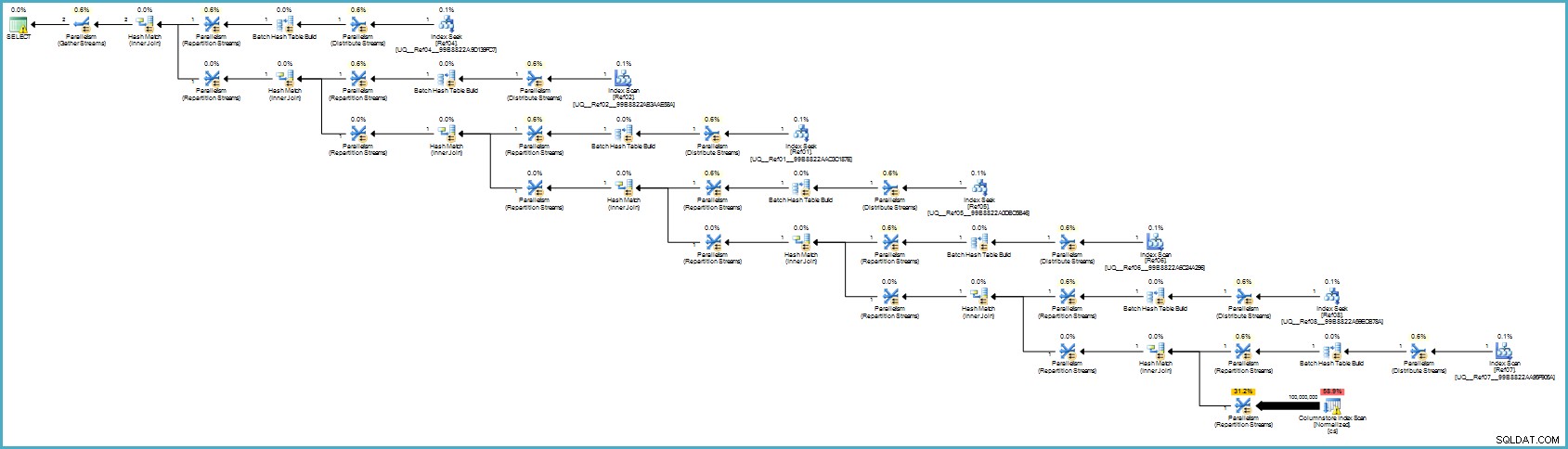
CREATE NONCLUSTERED COLUMNSTORE INDEX cs ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);実行計画は次のとおりです:
それはおそらくあなたには悪いように見えますが、列ストレージは非常に優れた圧縮を提供し、実行計画全体がバッチ モードで実行され、寄与するすべての列にフィルターが適用されます。サーバーが十分なスレッドとメモリを利用できる場合、この代替案は実際にうまくいく可能性があります。
最終的に、この正規化が正しいアプローチであるかどうかはわかりません。テーブルの数と、貧弱な実行計画が得られたり、過度のコンパイル時間が必要になったりする可能性を考慮すると、.おそらく最初に非正規化されたテーブルのスキーマを修正し (適切なデータ型など)、おそらくデータ圧縮を適用します... 通常のことです.
データが本当にスター スキーマに属している場合は、繰り返しのデータ要素を個別のテーブルに分割するだけでなく、さらに多くの設計作業が必要になる可能性があります。