問題の理由 :
TOKEN SSIS のメソッドは strtok の実装を使用します C++ の関数 .この情報は、Microsoft® SQL Server® 2012 Integration Services という本を読みながら集めました。強い>
. 113 ページの注記として言及されています (私はこの本が好きです!たくさんの素敵な情報 ).
strtok の実装を探してみました
INFO:strtok():C 関数 -- ドキュメントの補足 - このリンクのコード サンプルは、関数が連続する区切り文字を無視することを示しています。
次の SO の質問に対する回答は、strtok を指摘しています。 関数は、連続する区切り文字を無視するように設計されています。
strtok() を使用して 2 つのトークン セパレータの間にデータが表示されない場合を知る必要がある
TOKEN および TOKENCOUNT 関数は設計どおりに機能しますが、それが SSIS の動作方法であるかどうかは、Microsoft SSIS チームにとって問題になる可能性があります。
元の投稿 - 上記のセクションは更新です:
データ入力に基づいて、SSIS 2012 で簡単なパッケージを作成しました。質問で説明したように、TOKEN 関数が意図したとおりに動作しません。機能が動作していないように見えることに同意します。この投稿はそうではありません 元の問題に対する回答です。
比較的簡単な方法で式を記述する別の方法を次に示します。これは、入力レコードの最後のセグメントに常に値がある場合にのみ機能します (例:A1) 、B2 、C3 など)
式は次のように書き換えることができます :
このステートメントは、入力レコードをパラメーターとして受け取り、区切り文字キャレット (^) を 2 番目のパラメーターとして受け取ります。 3 番目のパラメーターは、区切り文字で分割された場合のレコード内の合計セグメント数を計算します。最後のセグメントにデータがある場合、2 つのセグメントがあることが保証されます。その後、1 を引いて、最後から 2 番目のセグメントを取得できます。
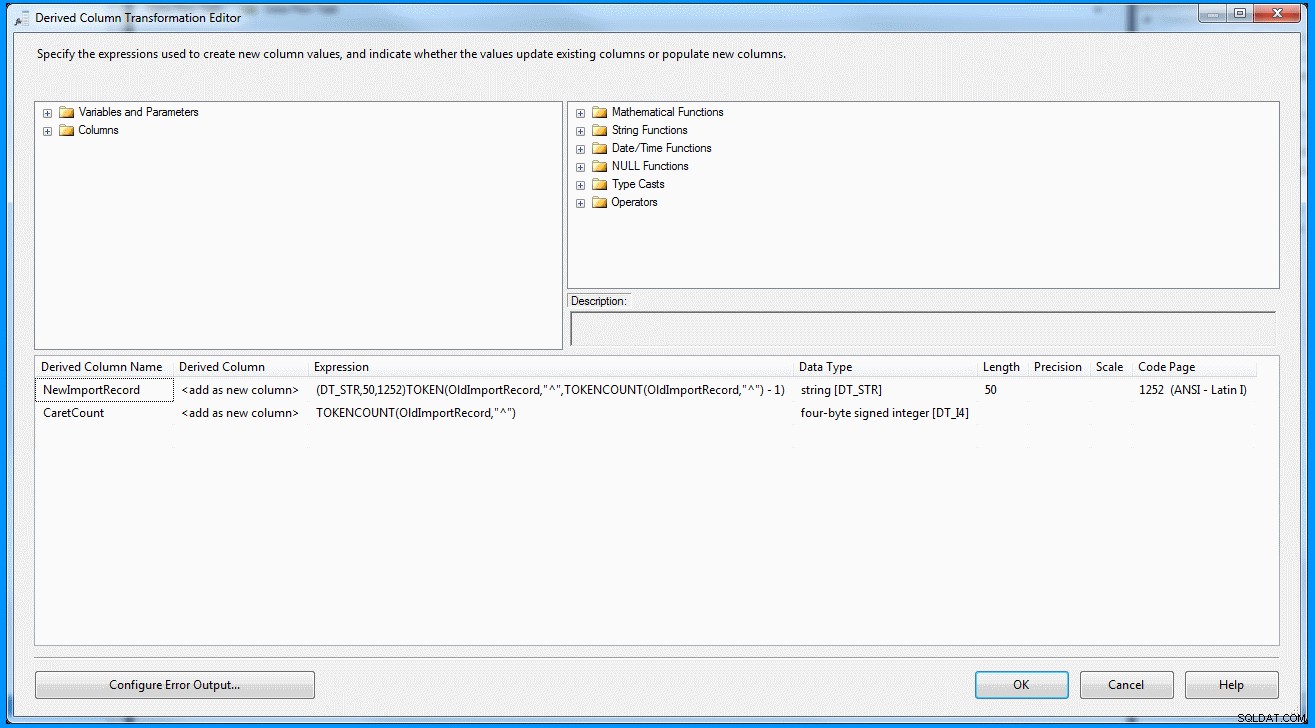
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
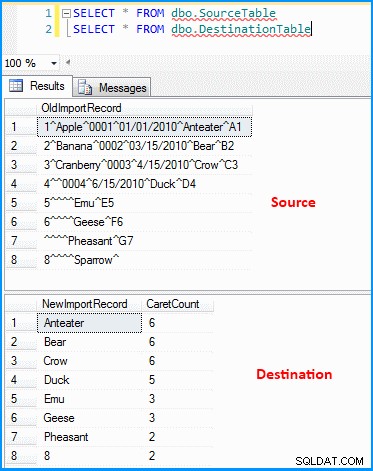
データ フロー タスクを含む単純なパッケージを作成しました。 OLE DB ソースがデータを取得し、派生した変換がデータを解析して分割します (下のスクリーンショットを参照)。次に、出力が宛先テーブルに挿入されます。最後のスクリーンショットでソース テーブルと宛先テーブルを確認できます。宛先テーブルには 2 つの列があります。最初の列には、最後から 2 番目のセグメント データと、区切り記号に基づくセグメント数が格納されます (これも正しくありません)。最後のレコードが正しい結果を取得していないことがわかります。最後のレコードの値が 8 でない場合 の場合、上記の式はゼロ インデックスに評価されるため失敗します。
表現を簡素化するのに役立つことを願っています.
他に連絡がない場合は、この問題を Microsoft Connect Web サイトに記録することをお勧めします> .
テーブルを作成してスクリプトに入力 :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
データ フロー タスク内の派生列変換 :
ソース テーブルと宛先テーブルのデータ :