春のトランザクションルーティング
まず、DataSourceTypeを作成します トランザクションルーティングオプションを定義するJava列挙型:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
読み取り/書き込みトランザクションをプライマリノードにルーティングし、読み取り専用トランザクションをレプリカノードにルーティングするために、ReadWriteDataSourceを定義できます。 プライマリノードとReadOnlyDataSourceに接続します レプリカノードに接続します。
読み取り/書き込みおよび読み取り専用のトランザクションルーティングは、Spring AbstractRoutingDataSourceによって実行されます。 TransactionRoutingDatasourceによって実装される抽象化 、次の図に示すように:
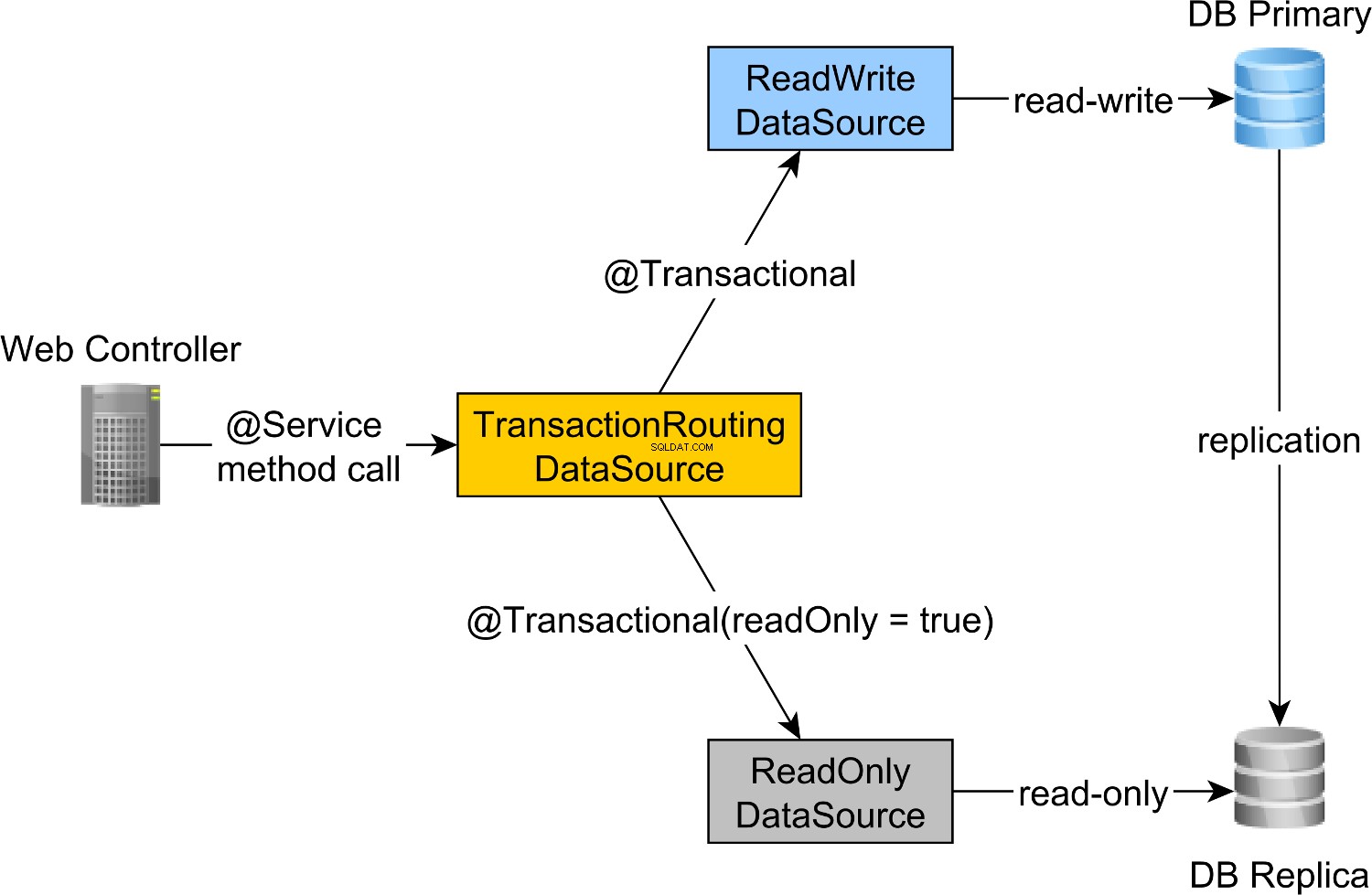
TransactionRoutingDataSource 実装は非常に簡単で、次のようになります。
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
基本的に、SpringのTransactionSynchronizationManagerを検査します 現在実行中のSpringトランザクションが読み取り専用かどうかを確認するために、現在のトランザクションコンテキストを格納するクラス。
determineCurrentLookupKey メソッドは、読み取り/書き込みまたは読み取り専用のJDBC DataSourceのいずれかを選択するために使用される識別子の値を返します。 。
Springの読み取り/書き込みおよび読み取り専用のJDBCデータソース構成
DataSource 構成は次のようになります:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
/META-INF/jdbc-postgresql-replication.properties リソースファイルは、読み取り/書き込みおよび読み取り専用のJDBC DataSourceの構成を提供します。 コンポーネント:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
jdbc.url.primary プロパティは、jdbc.url.replicaがプライマリノードのURLを定義します。 レプリカノードのURLを定義します。
readWriteDataSource Springコンポーネントは、読み取り/書き込みJDBC DataSourceを定義します readOnlyDataSource コンポーネントは、読み取り専用のJDBC DataSourceを定義します 。
読み取り/書き込みデータソースと読み取り専用データソースの両方が、接続プールにHikariCPを使用することに注意してください。
actualDataSource 読み取り/書き込みおよび読み取り専用のデータソースのファサードとして機能し、TransactionRoutingDataSourceを使用して実装されます ユーティリティ。
readWriteDataSource DataSourceType.READ_WRITEを使用して登録されます キーとreadOnlyDataSource DataSourceType.READ_ONLYを使用する キー。
したがって、読み取り/書き込み@Transactionalを実行する場合 メソッド、readWriteDataSource @Transactional(readOnly = true)の実行時に使用されます メソッド、readOnlyDataSource 代わりに使用されます。
additionalPropertiesに注意してください メソッドはhibernate.connection.provider_disables_autocommitを定義します RESOURCE_LOCALJPAトランザクションのデータベース取得を延期するためにHibernateに追加したHibernateプロパティ。
hibernate.connection.provider_disables_autocommitだけではありません データベース接続をより有効に活用できますが、この構成がないと、determineCurrentLookupKeyを呼び出す前に接続が取得されるため、この例を機能させる唯一の方法です。 メソッドTransactionRoutingDataSource。
JPA EntityManagerFactoryの構築に必要な残りのSpringコンポーネント AbstractJPAConfigurationによって定義されます 基本クラス。
基本的に、actualDataSource さらにDataSource-Proxyによってラップされ、JPA EntityManagerFactoryに提供されます。 。詳細については、GitHubでソースコードを確認できます。
テスト時間
トランザクションルーティングが機能するかどうかを確認するには、postgresql.confで次のプロパティを設定して、PostgreSQLクエリログを有効にします。 構成ファイル:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
log_min_duration_statement プロパティ設定はすべてのPostgreSQLステートメントをログに記録するためのもので、2番目の設定はデータベース名をSQLログに追加します。
したがって、newPostを呼び出すとき およびfindAllPostsByTitle このような方法:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
PostgreSQLが次のメッセージをログに記録していることがわかります。
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
high_performance_java_persistenceを使用したログステートメント high_performance_java_persistence_replicaを使用している間、プレフィックスはプライマリノードで実行されました レプリカノード上。
だから、すべてが魅力のように機能します!
すべてのソースコードは、私のHigh-Performance Java Persistence GitHubリポジトリにあるので、試してみることができます。
結論
接続プールに適切なサイズを設定する必要があります。これは、大きな違いを生む可能性があるためです。このために、FlexyPoolを使用することをお勧めします。
あなたは非常に勤勉である必要があり、それに応じてすべての読み取り専用トランザクションにマークを付けるようにしてください。トランザクションの10%のみが読み取り専用であるのは珍しいことです。このような書き込みが最も多いアプリケーションを使用しているのでしょうか、それともクエリステートメントのみを発行する書き込みトランザクションを使用しているのでしょうか。
バッチ処理の場合、必ず読み取り/書き込みトランザクションが必要になるため、次のようにJDBCバッチ処理を有効にしてください。
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
バッチ処理には、別のDataSourceを使用することもできます プライマリノードに接続する別の接続プールを使用します。
すべての接続プールの合計接続サイズが、PostgreSQLが構成されている接続の数よりも少ないことを確認してください。
各バッチジョブは専用のトランザクションを使用する必要があるため、適切なバッチサイズを使用するようにしてください。
さらに、ロックを保持し、トランザクションをできるだけ早く終了する必要があります。バッチプロセッサが並行処理ワーカーを使用している場合は、関連付けられている接続プールのサイズがワーカーの数と等しいことを確認してください。そうすれば、他のワーカーが接続を解放するのを待たなくなります。