特にデータ分析とIoTの使用量が急激に増加している場合、企業内で大量のデータを管理することが難しい場合があります。サイズによっては、この量のデータがシステムのパフォーマンスに影響を与える可能性があり、データベースを拡張するか、これを修正する方法を見つける必要があります。 PostgreSQLデータベースをスケーリングする方法はいくつかあり、そのうちの1つがシャーディングです。このブログでは、シャーディングとは何か、およびClusterControlを使用してPostgreSQLでシャーディングを構成してタスクを簡素化する方法を説明します。
シャーディングとは何ですか?
シャーディングは、大きなテーブルのデータを複数の小さなテーブルに分割することにより、データベースを最適化するアクションです。小さいテーブルはシャード(またはパーティション)です。パーティショニングとシャーディングは同様の概念です。主な違いは、シャーディングはデータが複数のコンピューターに分散していることを意味し、パーティショニングは単一のデータベースインスタンス内でデータのサブセットをグループ化することを意味します。
シャーディングには2つのタイプがあります:
-
水平シャーディング:新しい各テーブルには、大きなテーブルと同じスキーマがありますが、一意の行があります。クエリが、グループ化されることが多い行のサブセットを返す傾向がある場合に役立ちます。
-
垂直シャーディング:新しい各テーブルには、元のテーブルのスキーマのサブセットであるスキーマがあります。クエリがデータの列のサブセットのみを返す傾向がある場合に役立ちます。
| ID | | | |
|---|---|---|---|
| 1 | | 26 | |
| 2 | | 31 | |
| 3 | | 54 | |
| 4 | | 47 | |
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | | | ID | |
| 1 | | 26 | 1 | |
| 2 | | 31 | 2 | |
| 3 | | 54 | 3 | |
| 4 | | 47 | 4 | |
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | | | | ID | | | |
| 1 | | 26 | | 3 | | 54 | |
| 2 | | 31 | 4 | | 47 | | |
シャーディングの概念を確認したので、次のステップに進みましょう。
PostgreSQLクラスターをデプロイする方法
ClusterControlから展開を実行するには、[展開]オプションを選択し、表示される指示に従います。
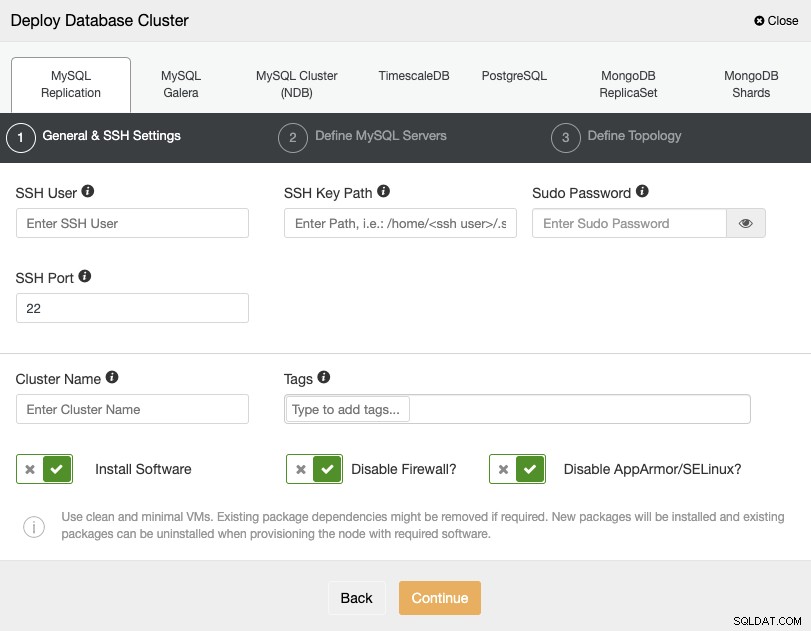
PostgreSQLを選択するときは、ユーザー、キー、またはパスワードを指定する必要があります。 SSHでサーバーに接続するためのポート。新しいクラスターの名前を追加することもできます。必要に応じて、ClusterControlを使用して、対応するソフトウェアと構成をインストールすることもできます。
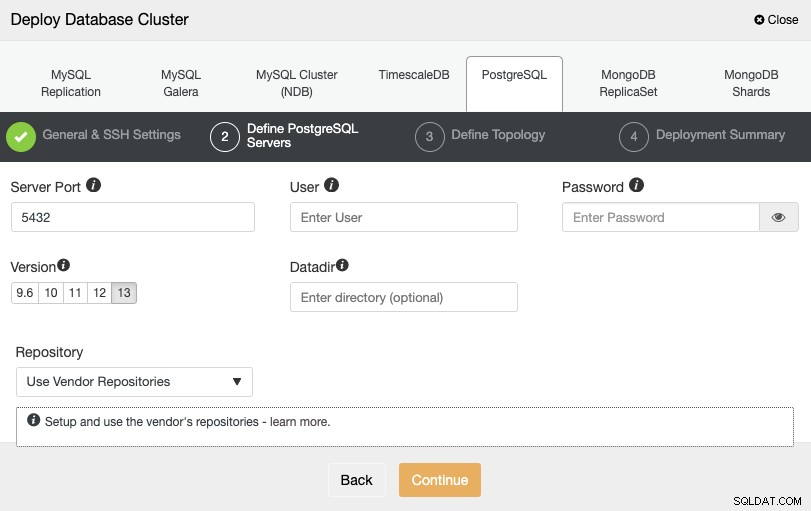
SSHアクセス情報を設定した後、データベースの資格情報を定義する必要があります、version、およびdatadir(オプション)。使用するリポジトリを指定することもできます。
次のステップでは、IPアドレスまたはホスト名を使用して作成するクラスターにサーバーを追加する必要があります。
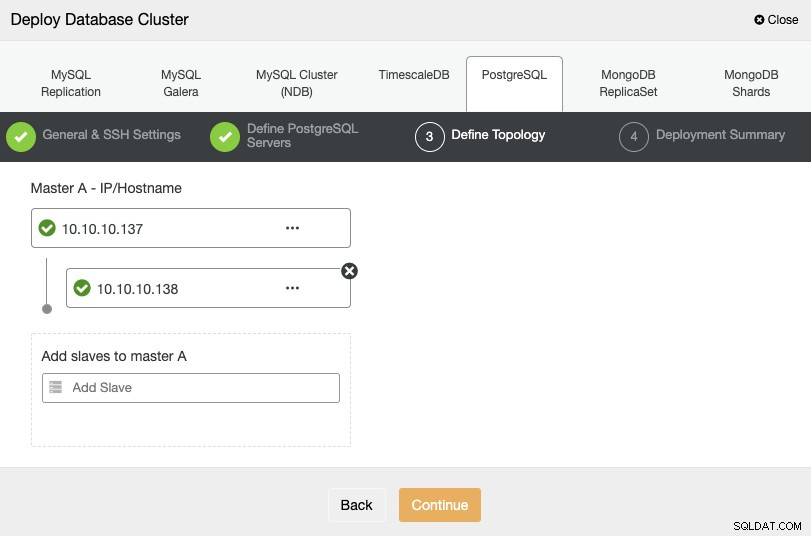
最後のステップで、レプリケーションを同期にするか、同期するかを選択できます。非同期で、「デプロイ」を押すだけです。
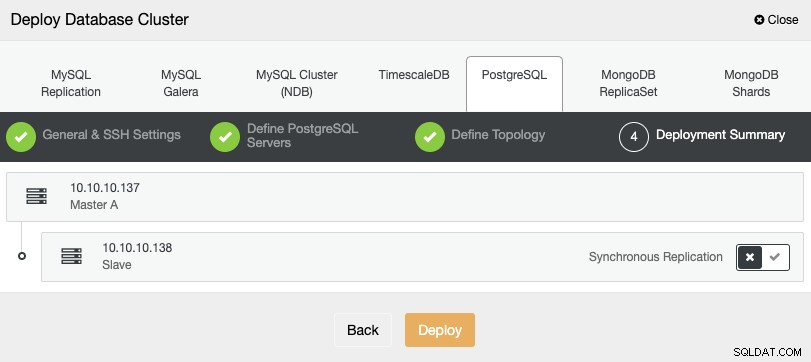
タスクが完了すると、新しいPostgreSQLクラスターがClusterControlのメイン画面。

クラスターが作成されたので、クラスターに対していくつかのタスクを実行できます。ロードバランサー(HAProxy)、接続プール(pgBouncer)、または新しいレプリカを追加するようなものです。
プロセスを繰り返して、少なくとも2つの別個のPostgreSQLクラスターを作成し、シャーディングを構成します。これが次のステップです。
PostgreSQLシャーディングを構成する方法
次に、PostgreSQLパーティションと外部データラッパー(FDW)を使用してシャーディングを構成します。この機能により、PostgreSQLは他のサーバーに保存されているデータにアクセスできます。これは、一般的なPostgreSQLインストールでデフォルトで使用できる拡張機能です。
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersFDW拡張機能を有効にするには、メインサーバー(この場合はShard1)で次のコマンドを実行する必要があります。
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSION次に、登録日でパーティション化された顧客テーブルを作成しましょう:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);そして次のパーティション:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');ここで、メインパーティションにクエリを実行して、すべてのデータを確認できます。
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)または、対応するパーティションにクエリを実行します:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
ご覧のとおり、登録日に従って、データはさまざまなパーティションに挿入されました。次に、リモートノード(この場合はShard2)で、別のテーブルを作成しましょう。
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);このShard2サーバーをShard1に次のように作成する必要があります:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');そしてそれにアクセスするユーザー:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');次に、Shard1でFOREIGNTABLEを作成します。
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;そして、Shard1からこの新しいリモートテーブルにデータを挿入しましょう:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1すべてがうまくいけば、Shard1とShard2の両方からデータにアクセスできるはずです:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)PostgreSQLのパーティショニングとシャーディングは優れた機能です。パフォーマンスを向上させるために、または他の状況の中でも簡単な方法でデータをパージするために、大きなテーブルでデータを分離する必要がある場合に役立ちます。シャーディングを使用する場合の重要なポイントは、ノード間でデータを最適な方法で分散する適切なシャードキーを選択することです。また、ClusterControlを使用して、PostgreSQLの展開を簡素化し、監視、アラート、自動フェイルオーバー、バックアップ、ポイントインタイムリカバリなどのいくつかの機能を利用できます。