PostgreSQLインストールの管理には、PostgreSQLが実行されるソフトウェア/インフラストラクチャスタックのさまざまな側面の検査と制御が含まれます。これはカバーする必要があります:
- データベースの使用/トランザクション/接続に関するアプリケーションの調整
- データベースコード(クエリ、関数)
- データベースシステム(パフォーマンス、HA、バックアップ)
- ハードウェア/インフラストラクチャ(ディスク、CPU /メモリ)
PostgreSQLコアは、データの保存、処理、提供を信頼するデータベースレイヤーを提供します。また、真に近代的で、効率的で、信頼性が高く、安全なシステムを実現するためのすべてのテクノロジーを提供します。しかし、多くの場合、このテクノロジーは、コアPostgreSQLディストリビューションですぐに使用できる洗練されたビジネス/エンタープライズクラスの製品としては利用できません。代わりに、PostgreSQLコミュニティまたはこれらのニーズを満たす商用製品のいずれかによる多くの製品/ソリューションがあります。これらのソリューションは、コアテクノロジーのユーザーフレンドリーな改良として、またはコアテクノロジーの拡張として、あるいはPostgreSQLコンポーネントとシステムの他のコンポーネント間の統合として提供されます。 PostgreSQLを使用して本番環境に移行するための10のヒントというタイトルの以前のブログでは、本番環境でのPostgreSQLインストールの管理に役立つツールのいくつかを調べました。このブログでは、実稼働環境でPostgreSQLのインストールを管理するときにカバーする必要のある側面と、その目的で最も一般的に使用されるツールについて詳しく説明します。次のトピックについて説明します。
- 導入
- 管理
- スケーリング
- 監視
展開
昔は、PostgreSQLを手動でダウンロードしてコンパイルし、ランタイムパラメータとユーザーアクセス制御を構成していました。これが必要になる場合もありますが、システムが成熟して成長し始めると、Postgresqlをデプロイおよび管理するためのより標準化された方法が必要になります。ほとんどのOSは、PostgreSQLクラスターをインストール、デプロイ、および管理するためのパッケージを提供しています。 Debianは、多くのPostgresqlバージョンと、バージョンごとに同時に多くのクラスターをサポートする独自のシステムレイアウトを標準化しました。 postgresql-common debianパッケージは、必要なツールを提供します。たとえば、DebianでPostgreSQLバージョン10用の新しいクラスター(i18n_clusterと呼ばれる)を作成するには、次のコマンドを実行します。
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksums次にsystemdを更新します:
$ sudo systemctl daemon-reload最後に、新しいクラスターを起動して使用します:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(Debianは異なるポート5432、5433などを使用して異なるクラスターを処理することに注意してください)
より自動化された大規模な展開の必要性が高まるにつれて、Ansible、Chef、Puppetなどの自動化ツールを使用するインストールがますます増えています。自動化とデプロイメントの再現性に加えて、自動化ツールは、クラスターのデプロイメントと構成を文書化するための優れた方法であるため、優れています。一方、自動化はそれ自体が大きな分野に進化し、熟練した人々が自動化されたスクリプトを作成、管理、実行する必要があります。 PostgreSQLプロビジョニングの詳細については、このブログを参照してください:PostgreSQL DBAになる:プロビジョニングと展開。
管理
稼働中のシステムの管理には、バックアップのスケジュールとそのステータスの監視、障害復旧、構成管理、高可用性管理、および自動フェイルオーバー処理などのタスクが含まれます。 Postgresqlクラスターのバックアップはさまざまな方法で実行できます。低レベルのツール:
- 従来のpg_dump(論理バックアップ)
- ファイルシステムレベルのバックアップ(物理バックアップ)
- pg_basebackup(物理バックアップ)
以上のレベル:
- バーマン
- PgBackRest
これらの各方法は、さまざまなユースケースとリカバリシナリオをカバーし、複雑さも異なります。 PostgreSQLのバックアップは、PITR、WALのアーカイブ、およびレプリケーションの概念と密接に関連しています。何年にもわたって、PostgreSQLでバックアップを取り、テストし、最後に(指を交差させた!)使用する手順は、複雑なタスクに進化しました。このブログでPostgreSQLのバックアップソリューションの概要を見つけることができます:PostgreSQLのトップバックアップツール。
高可用性と自動フェイルオーバーに関して、これを実装するためにインストールに必要な最低限の要件は次のとおりです。
- 現役のプライマリー
- プライマリからストリーミングされたWALを受け入れるホットスタンバイ
- プライマリに障害が発生した場合に、プライマリがプライマリではなくなったことをプライマリに通知する方法(STONITHと呼ばれることもあります)
- 2台のサーバー間の接続とプライマリの状態をチェックするハートビートメカニズム
- フェイルオーバーを実行する方法(例:pg_ctlプロモートまたはトリガーファイルを介して)
- 古いプライマリを新しいスタンバイとして再作成するための自動化された手順:プライマリで中断または障害が検出されたら、スタンバイを新しいプライマリとして昇格させる必要があります。古いプライマリは無効または使用できなくなりました。したがって、システムには、フェイルオーバーと古いプライマリサーバーの新しいスタンバイとしての再作成の間にこの状態を処理する方法が必要です。この状態は縮退状態と呼ばれ、PostgreSQLは、古いプライマリを新しいプライマリから同期可能な状態に戻すプロセスを高速化するために、pg_rewindと呼ばれるツールを提供します。
- オンデマンド/計画的な切り替えを行う方法
上記のすべてを処理する広く使用されているツールはRepmgrです。スイッチオーバーを成功させるための最小限のセットアップについて説明します。まず、FreeBSD11.1で動作するPostgreSQL10.4プライマリを手動でビルドしてインストールし、このバージョン(10.4)ではrepmgr4.0も手動でビルドしてインストールします。 fbsd(192.168.1.80)とfbsdclone(192.168.1.81)という名前の2つのホストを、同じバージョンのPostgreSQLとrepmgrで使用します。プライマリ(最初はfbsd、192.168.1.80)で、次のPostgreSQLパラメータが設定されていることを確認します。
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' 次に、repmgrユーザー(スーパーユーザーとして)とデータベースを作成します。
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrpg_hba.confでホストベースのアクセス制御を設定するには、上部に次の行を配置します。
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trust.sshにauthorized_keysを設定してから.sshを共有することにより、クラスターのすべてのノード(この場合はfbsdとfbsdclone)でユーザーrepmgrのパスワードなしのログインを設定していることを確認します。次に、プライマリでrepmrg.confを次のように作成します。
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'次に、プライマリを登録します:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredそして、クラスターのステータスを確認します:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2repmgr.confを次のように設定して、スタンバイで作業します。
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'また、上記の行で指定されたデータディレクトリが存在し、空であり、適切な権限を持っていることを確認します。
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 data新しいスタンバイにクローンを作成する必要があります:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"そしてスタンバイを開始します:
example@sqldat.com:~ % pg_ctl -D data startこの時点で、レプリケーションは期待どおりに機能しているはずです。pg_stat_replication(fbsd)とpg_stat_wal_receiver(fbsdclone)にクエリを実行して、これを確認してください。次のステップは、スタンバイを登録することです:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerこれで、スタンドアロンまたはプライマリのいずれかでクラスタのステータスを取得し、スタンバイが登録されていることを確認できます。
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2ここで、スケジュールされた手動切り替えを順番に実行したいとします。ノードfbsdで管理作業を行うため。スタンバイノードで、次のコマンドを実行します。
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyスイッチオーバーが正常に実行されました。クラスターショーが提供するものを見てみましょう:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=22つのサーバーの役割が入れ替わっています。 Repmgrは、監視、自動フェイルオーバー、および通知/アラートを提供するrepmgrdデーモンを提供します。 repmgrdとpgbouncerを組み合わせることで、データベースの接続情報の自動更新を実装できるため、障害が発生したプライマリにフェンシングを提供し(障害が発生したノードがアプリケーションで使用されないようにする)、アプリケーションのダウンタイムを最小限に抑えることができます。より複雑なスキームでは、次のことを実現するために、pgbouncerとrepmgrの上にKeepalivedとHAProxyを組み合わせるという別のアイデアがあります。
- 負荷分散(スケーリング)
- 高可用性
ClusterControlは、PostgreSQLレプリケーション設定のフェイルオーバーも管理し、HAProxyとVirtualIPを統合して、クライアント接続を作業マスターに自動的に再ルーティングすることに注意してください。詳細については、PostgreSQL自動化に関するこのホワイトペーパーを参照してください。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするスケーリング
PostgreSQL 10(および11)の時点では、少なくともコアPostgreSQLからではなく、マルチマスターレプリケーションを実行する方法はまだありません。これは、select(読み取り専用)アクティビティのみをスケールアップできることを意味します。 PostgreSQLでのスケーリングは、ホットスタンバイを追加することで実現され、読み取り専用アクティビティ用のリソースが増えます。 repmgrを使用すると、スタンバイクローンで以前に見たように、新しいスタンバイを簡単に追加できます。 およびスタンバイレジスタ コマンド。追加(または削除)されたスタンバイは、ロードバランサーの構成に通知する必要があります。上記の管理トピックで述べたように、HAProxyはPostgreSQLで人気のあるロードバランサーです。通常、VRRPを介して仮想IPを提供するKeepalivedと結合されます。 HAProxyとKeepalivedをPostgreSQLと一緒に使用する方法の概要については、この記事「HAProxyとKeepalivedを使用したPostgreSQLの負荷分散」を参照してください。
監視
PostgreSQLで監視する対象の概要については、この記事「PostgreSQLで監視する重要事項-ワークロードの分析」を参照してください。プラグインを介してシステムとpostgresqlの監視を提供できるツールはたくさんあります。一部のツールは履歴値のグラフを表示する領域(munin)をカバーし、他のツールはライブデータの監視とライブアラートの提供(nagios)の領域をカバーし、一部のツールは両方の領域(zabbix)をカバーします。 PostgreSQL用のそのようなツールのリストはここで見つけることができます:https://wiki.postgresql.org/wiki/Monitoring。オフライン(ログファイルベース)監視用の一般的なツールはpgBadgerです。 pgBadgerは、PostgreSQLログ(通常は1日のアクティビティをカバーします)を解析し、情報を抽出し、統計を計算し、最終的に結果を表示する豪華なhtmlページを生成することによって機能するPerlスクリプトです。 pgBadgerは、log_line_prefix設定に制限はなく、既存の形式に適応する場合があります。たとえば、postgresql.confに次のようなものを設定した場合:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l '次に、ログファイルを解析して結果を生成するpgbadgerコマンドは次のようになります。
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadgerは以下のレポートを提供します:
- 概要統計(主にSQLトラフィック)
- 接続(1秒あたり、データベース/ユーザー/ホストごと)
- セッション(データベース/ユーザー/ホスト/アプリケーションごとの数、セッション時間)
- チェックポイント(バッファ、walファイル、アクティビティ)
- 一時ファイルの使用法
- バキューム/分析アクティビティ(テーブルごと、タプル/ページが削除されました)
- ロック
- クエリ(タイプ/データベース/ユーザー/ホスト/アプリケーション別、ユーザー別の期間)
- トップ(クエリ:最も遅く、時間がかかり、より頻繁に、正規化された最も遅い)
- イベント(エラー、警告、致命的など)
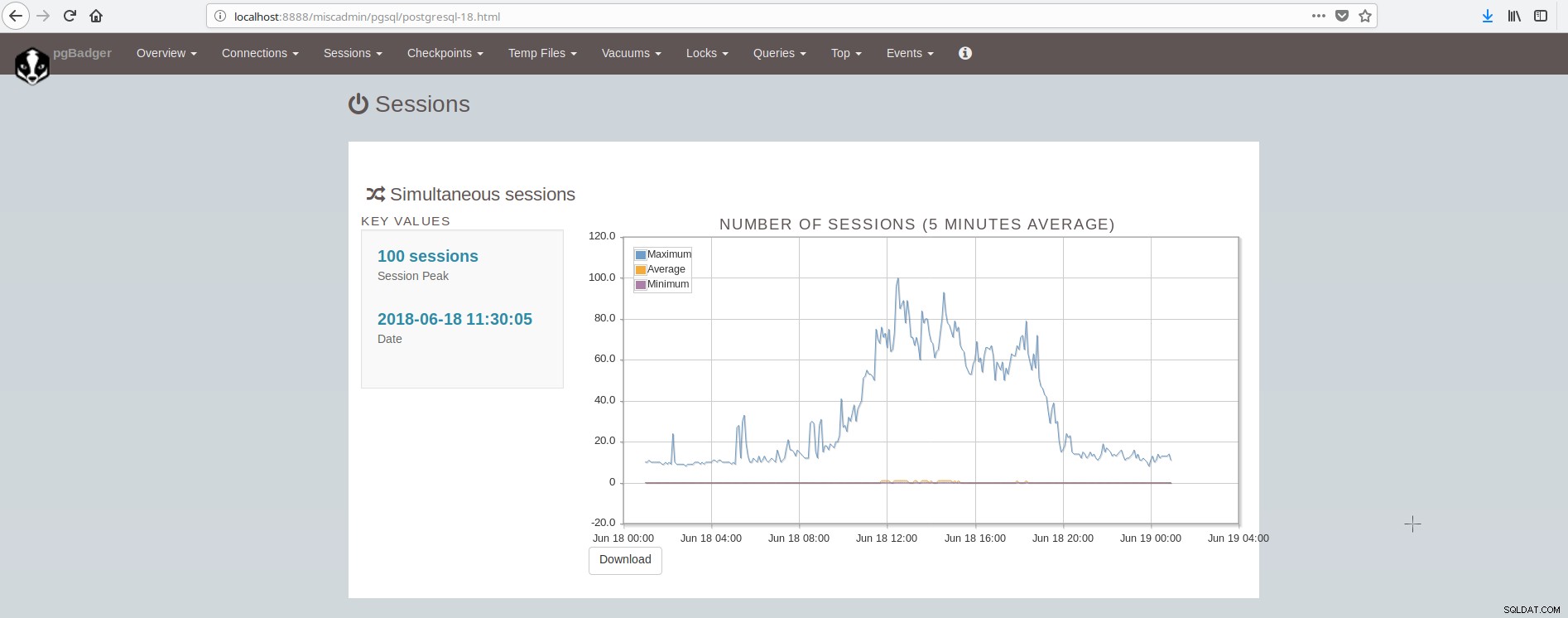
セッションを表示する画面は次のようになります:
結論として、最新の信頼性が高く高速なインフラストラクチャを実現するには、平均的なPostgreSQLインストールで多くのツールを統合して処理する必要があります。postgresqlとシステム管理に大規模なチームが関与していない限り、これを実現するのはかなり複雑です。上記のすべてとそれ以上のことを行う優れたスイートはClusterControlです。