ディザスタリカバリでは、データベースで問題が発生する可能性のあるすべてのものを処理するシステムをセットアップすることを目指しています。データベースがクラッシュした場合はどうなりますか?開発者が誤ってテーブルを切り捨てた場合はどうなりますか?先週一部のデータが削除されたことがわかったが、今日まで気づかなかった場合はどうなりますか?これらのことが起こり、しっかりとした計画とシステムが整っていると、災害が醜い頭を抱えたときに他の人の心がすでに止まっているときに、DBAはヒーローのように見えます。
何らかの価値のあるデータベースには、1つ以上のディザスタリカバリオプションを実装する方法が必要です。 PostgreSQLには非常に堅牢なレプリケーションシステムが組み込まれており、問題が発生した場合にディザスタリカバリを支援するために多くの構成でセットアップできる柔軟性があります。上記の質問のようなシナリオ、ディザスタリカバリオプションの設定方法、および各ソリューションのメリットに焦点を当てます。
高可用性
PostgreSQLのストリーミングレプリケーションを使用すると、高可用性のセットアップと保守が簡単になります。目標は、ハードウェア障害、ソフトウェア障害、さらにはネットワークの停止などの理由でメインデータベースがダウンした場合に、マスターに昇格できるフェイルオーバーサイトを提供することです。別のホストでレプリカをホストすることは素晴らしいことですが、別のデータセンターでレプリカをホストすることはさらに優れています。
ストリーミングレプリケーションの設定の詳細については、Severeninesが詳細をここで入手できます。公式のPostgreSQLストリーミングレプリケーションドキュメントには、ストリーミングレプリケーションプロトコルとそのすべての動作に関する詳細情報があります。
標準のセットアップは次のようになります。マスターデータベースは読み取り/書き込み接続を受け入れ、レプリカデータベースはほぼリアルタイムですべてのWALアクティビティを受信し、すべてのデータ変更アクティビティをローカルで再生します。
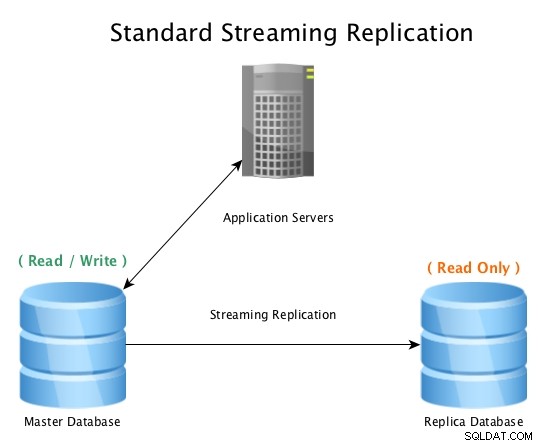 PostgreSQLを使用した標準ストリーミングレプリケーション
PostgreSQLを使用した標準ストリーミングレプリケーション マスターデータベースが使用できなくなると、フェイルオーバー手順が開始されてデータベースがオフラインになり、レプリカデータベースがマスターに昇格してから、新しく昇格したホストへのすべての接続が示されます。これは、ロードバランサー、アプリケーション構成、IPエイリアス、またはトラフィックをリダイレクトするその他の巧妙な方法のいずれかを再構成することで実行できます。
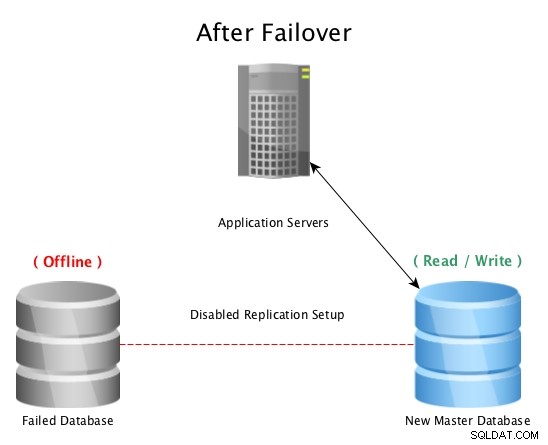 PostgreSQLストリーミングレプリケーションによるフェイルオーバー後
PostgreSQLストリーミングレプリケーションによるフェイルオーバー後 災害がマスターデータベースに発生した場合(ハードドライブの障害、停電、またはマスターが意図したとおりに機能しないなど)、ホットスタンバイにフェイルオーバーすることは、深刻な問題なしにアプリケーションや顧客にクエリをオンラインで提供し続けるための最も簡単な方法です。ダウンタイム。次に、障害が発生したデータベースホストを修正するか、新しいレプリカをオンラインにして、スタンバイの準備ができているというセーフティネットを維持するための競争が始まります。複数のスタンバイを用意することで、壊滅的な障害が発生した後のウィンドウでも二次的な障害に備えることができますが、そうは思われないかもしれません。
注:ストリーミングレプリカにフェイルオーバーすると、前のマスターが中断したところから再開されるため、データベースをオンラインに保つのに役立ちますが、誤って失われたデータを復元することはできません。
ポイントインタイムリカバリ
もう1つのディザスタリカバリオプションは、ポイントインタイムリカバリ(PITR)です。 PITRを使用すると、データベースのコピーをいつでも戻すことができます。ただし、その時点より前のベースバックアップがあり、それまでに必要なすべてのWALセグメントがある場合に限ります。
ポイントインタイムリカバリオプションは、ホットスタンバイほど迅速にオンラインになりませんが、主な利点は、テーブルの削除、不正なデータの挿入、説明のつかないデータの破損などの大きなイベントの前にデータベーススナップショットをリカバリできることです。 。破棄する前にコピーを取得したいような方法でデータを破棄するものはすべて、PITRがその日を節約します。
ポイントインタイムリカバリは、通常はプログラムpg_basebackupを使用してデータベースの定期的なスナップショットを作成し、マスターによって生成されたすべてのWALファイルのアーカイブされたコピーを保持することによって機能します
ポイントインタイムリカバリの設定
セットアップには、マスターに設定されたいくつかの構成オプションが必要です。そのうちのいくつかは、現在の最新バージョンであるPostgreSQL 11のデフォルト値に合わせるのに適しています。この例では、rsyncを使用して16MBファイルをリモートPITRホストに直接コピーします。 、およびcronジョブを使用して反対側でそれらを圧縮します。
WALアーカイブ
マスターpostgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'注: archive_commandの設定にはさまざまなものがあります。全体的な目標は、安全のために、アーカイブされたすべてのWALファイルを別のホストに送信することです。 WALファイルを失うと、失われたWALファイルを超えたPITRは不可能になります。プログラミングの創造性を狂わせましょう。ただし、信頼できるものであることを確認してください。
[オプション]アーカイブされたWALファイルを圧縮します:
すべての設定は多少異なりますが、問題のデータベースのデータ更新が非常に少ない場合を除いて、16MBのファイルの蓄積はドライブスペースをかなり早くいっぱいにします。 cronを使用して設定された簡単な圧縮スクリプトは、次のようになります。
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]注: リカバリ方法では、圧縮されたファイルは後で解凍する必要があります。一部の管理者は、ファイルがX日経過した後にのみ圧縮することを選択し、全体的なスペースを低く抑えながら、余分な作業を行わずに最新のWALファイルをリカバリできるようにします。リカバリ速度を最大化するには、問題のデータベースに最適なオプションを選択してください。
ベースバックアップ
PITRバックアップの重要なコンポーネントの1つは、基本バックアップと基本バックアップの頻度です。これらは、毎時、毎日、毎週、毎月の場合がありますが、リカバリのニーズとデータベースデータチャーンのトラフィックに基づいて最適なオプションを選択しました。毎週日曜日にバックアップがあり、土曜日の午後まで復旧する必要がある場合は、前の日曜日の基本バックアップを、そのバックアップから土曜日の午後までのすべてのWALファイルとともにオンラインにします。このリカバリプロセスの処理に10時間かかる場合、これは望ましくないほど長すぎる可能性があります。ベースバックアップはその朝から行われるため、毎日のベースバックアップはそのリカバリ時間を短縮しますが、ベースバックアップのためのホストでの作業量も増加します。
データベースのチャーンが少ないため、WALファイルの1週間のリカバリに数分かかる場合は、毎週のバックアップで問題ありません。最終的には同じデータが存在しますが、どれだけ速くデータにアクセスできるかが重要です。
この例では、毎週のベースバックアップを設定します。高可用性のためにストリーミングレプリケーションを使用し、マスターの負荷を軽減するため、レプリカデータベースからベースバックアップを作成します。
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -z注: pg_basebackupコマンドは、このホストがマスター上のユーザー「レプリケーション」のパスワードなしアクセス用に設定されていることを前提としています。これは、このPITRバックアップホストのpg_hbaの「trust」、. pgpassファイルのパスワード、またはその他のより安全な方法で実行できます。 。バックアップを設定するときは、セキュリティに注意してください。
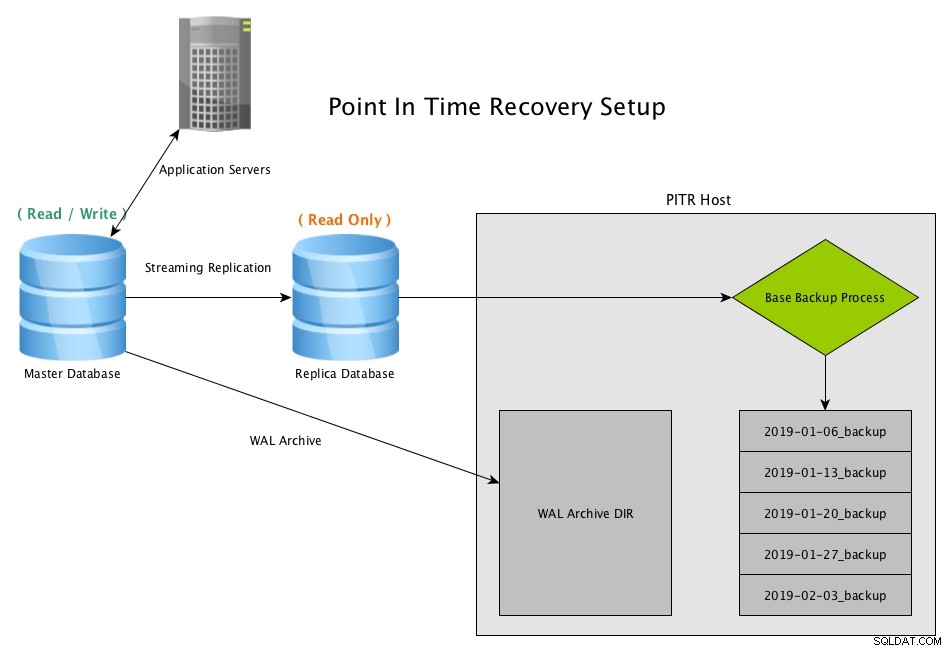 PostgreSQLを使用したストリーミングレプリカからのポイントインタイムリカバリ(PITR)今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングのために知っておくべきことホワイトペーパーをダウンロードする
PostgreSQLを使用したストリーミングレプリカからのポイントインタイムリカバリ(PITR)今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングのために知っておくべきことホワイトペーパーをダウンロードする PITR回復シナリオ
ポイントインタイムリカバリの設定はジョブの一部にすぎず、データをリカバリする必要があるのは別の部分です。幸運なことに、これが発生する必要はないかもしれませんが、PITRバックアップの復元を定期的に実行して、システムが機能していることを検証し、プロセスが正しく認識/スクリプト化されていることを確認することを強くお勧めします。
テストシナリオでは、復旧する時点を選択し、復旧プロセスを開始します。例:金曜日の朝、開発者はコードレビューを行わずに新しいコードの変更を本番環境にプッシュし、重要な顧客データの束を破壊します。ホットスタンバイは常にマスターと同期しているため、マスターにフェイルオーバーしても、同じデータになるため、何も修正されません。 PITRバックアップは私たちを救うものです。
コードプッシュは午前11時に行われたため、データベースをその直前の午前10:59に復元する必要があります。幸い、毎日バックアップを実行して、今朝の深夜からバックアップを作成します。何が破壊されたかわからないため、PITRホストでこのデータベースを完全に復元し、万が一の場合に備えて、マスターと同じハードウェア仕様を備えているため、マスターとしてオンラインにすることにしました。シナリオが発生しました。
マスターをシャットダウン
バックアップから完全に復元してマスターにプロモートすることにしたので、これをオンラインに保つ必要はありません。シャットダウンしましたが、万が一の場合に備えて、後で何かを取得する必要がある場合に備えて、そのままにしておいてください。
リカバリ用のベースバックアップの設定
次に、PITRホストで、イベント前の最新の基本バックアップであるバックアップ「2018-12-21_backup」を取得します。
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/これで、ベースバックアップとpg_basebackupによって提供されるWALファイルの準備が整いました。今すぐオンラインにすると、バックアップが行われた時点まで回復しますが、その間のすべてのWALトランザクションを回復したいと考えています。午前0時と午前11時59分なので、recovery.confファイルを設定しました。
recovery.confを作成
このバックアップは実際にはストリーミングレプリカからのものであるため、レプリカ設定を含むrecovery.confファイルがすでに存在する可能性があります。新しい設定で上書きします。さまざまなオプションすべての詳細情報リストは、PostgreSQLのドキュメントにあります。
WALファイルに注意して、restoreコマンドは必要な圧縮ファイルをrestoreディレクトリにコピーし、解凍してから、PostgreSQLがリカバリのために必要とする場所に移動します。元のWALファイルは、他の理由で必要になった場合に備えて、そのまま残ります。
新しいrecovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'リカバリプロセスを開始する
すべての準備が整ったので、回復のプロセスを開始します。これが発生した場合は、データベースログを調整して、意図したとおりに復元されていることを確認することをお勧めします。
DBを起動します:
pg_ctl -D /var/lib/pgsql/11/data startログを追跡する:
データベースがアーカイブファイルから回復していることを示す多くのログエントリがあり、ある時点で、「トランザクションのコミット前に回復が停止しています…」という行が表示されます。
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07この時点で、リカバリプロセスはすべてのWALファイルを取り込みましたが、マスターとしてオンラインになる前に確認する必要もあります。この例では、ログには、回復目標時刻11:59:00以降の次のトランザクションが11:59:01であり、回復されなかったことが記録されています。確認するには、データベースにログインして確認します。実行中のデータベースは、正確に11:59の時点でのスナップショットである必要があります。
すべてが良さそうになったら、マスターとしての回復を促進する時間です。
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)これで、データベースはオンラインになり、決定した時点まで回復し、マスターノードとして読み取り/書き込み接続を受け入れます。すべての構成パラメーターが正しく、本番環境に対応していることを確認してください。
データベースはオンラインですが、リカバリプロセスはまだ完了していません。このPITRバックアップがマスターとしてオンラインになっているので、新しいスタンバイとPITRセットアップをセットアップする必要があります。それまでは、この新しいマスターがオンラインでアプリケーションにサービスを提供している可能性がありますが、すべてが再度セットアップされるまで、別の災害から安全ではありません。
その他のポイントインタイムリカバリシナリオ
データベース全体のPITRバックアップを元に戻すことは極端なケースですが、データのサブセットのみが欠落しているか、破損しているか、不良であるというシナリオもあります。このような場合、リカバリオプションを使用してクリエイティブになります。マスターをオフラインにしてバックアップに置き換えることなく、PITRバックアップを別のホスト(またはスペースに問題がない場合は別のポート)で希望する正確な時間にオンラインにし、バックアップから復元されたデータを直接エクスポートできます。マスターデータベースに。これは、少数の行、少数のテーブル、または必要なデータの構成を回復するために使用できます。
ストリーミングレプリケーションとポイントインタイムリカバリにより、PostgreSQLは、スタンバイホストをマスターとして使用する準備ができているか、バックアップをリカバリする準備ができている限り、必要なデータを確実にリカバリできるという大きな柔軟性を提供します。優れたディザスタリカバリオプションは、他のバックアップオプション、より多くのレプリカノード、さまざまなデータセンターや大陸にまたがる複数のバックアップサイト、別のレプリカの定期的なpg_dumpsなどでさらに拡張できます。
これらのオプションを合計することもできますが、本当の問題は、「データの価値と、データを取り戻すためにいくら費やしてもよいか」ということです。多くの場合、データの損失はビジネスの終わりであるため、最悪の事態が発生するのを防ぐために、適切なディザスタリカバリオプションを用意する必要があります。