リレーショナルデータベースエンジンのいずれにおいても、最小限の時間とリソースでクエリの実行に対応する可能な限り最良の計画を生成する必要があります。一般に、すべてのデータベースはツリー構造形式でプランを生成します。各プランツリーのリーフノードはテーブルスキャンノードと呼ばれます。計画のこの特定のノードは、ベーステーブルからデータをフェッチするために使用されるアルゴリズムに対応しています。
たとえば、単純なクエリの例をSELECT * FROM TBL1、TBL2 whereTBL2.ID>1000;と考えます。生成された計画は次のとおりであると想定します。
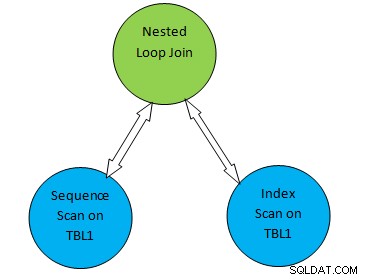
したがって、上記のプランツリーでは、「TBL1のシーケンシャルスキャン」と「 「TBL2のインデックススキャン」は、それぞれテーブルTBL1とTBL2のテーブルスキャン方法に対応します。したがって、この計画に従って、TBL1は対応するページから順番にフェッチされ、TBL2にはINDEXスキャンを使用してアクセスできます。
計画の一部として適切なスキャン方法を選択することは、全体的なクエリパフォーマンスの観点から非常に重要です。
PostgreSQLでサポートされているすべてのタイプのスキャン方法に入る前に、ブログで頻繁に使用される主要なキーポイントのいくつかを修正しましょう。
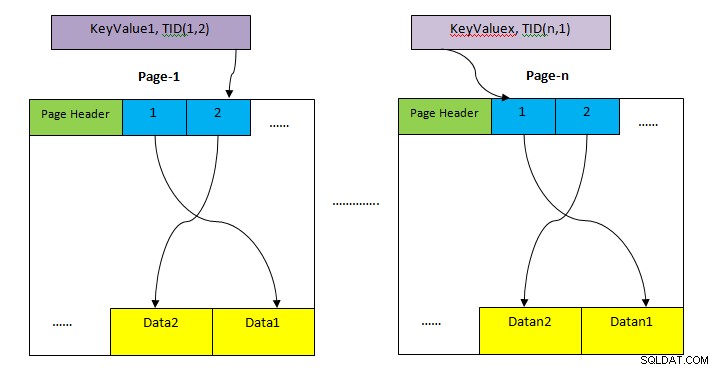
- ヒープ: テーブルの行全体を格納するためのストレージ領域。これは複数のページに分割され(上の図を参照)、各ページサイズはデフォルトで8KBです。各ページ内で、各アイテムポインタ(1、2、…。など)はページ内のデータを指します。
- インデックスストレージ: このストレージには、キー値、つまりインデックスに含まれる列値のみが格納されます。これも複数のページに分割され、各ページサイズはデフォルトで8KBです。
- タプル識別子(TID): TIDは、2つの部分で構成される6バイトの数値です。最初の部分は4バイトのページ番号で、残りの2バイトのタプルインデックスはページ内にあります。これらの2つの数値の組み合わせは、特定のタプルの保管場所を一意に示します。
現在、PostgreSQLは以下のスキャンメソッドをサポートしており、これにより、必要なすべてのデータをテーブルから読み取ることができます。
- シーケンシャルスキャン
- インデックススキャン
- インデックスのみのスキャン
- ビットマップスキャン
- TIDスキャン
これらのスキャン方法はそれぞれ、クエリやその他のパラメータに応じて同じように役立ちます。テーブルのカーディナリティ、テーブルの選択性、ディスクI / Oコスト、ランダムI / Oコスト、シーケンスI / Oコストなど。事前設定テーブルを作成し、これらのスキャン方法をよりよく説明するために頻繁に使用されるデータを入力してみましょう。 。
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEこの例では、100万件のレコードが挿入され、すべての統計が最新になるようにテーブルが分析されます。
名前が示すように、テーブルのシーケンシャルスキャンは、対応するテーブルのすべてのページのすべてのアイテムポインタをシーケンシャルにスキャンすることによって実行されます。したがって、特定のテーブルに100ページがあり、各ページに1000レコードがある場合、シーケンシャルスキャンの一部として、100 * 1000レコードをフェッチし、分離レベルおよび述語句に従って一致するかどうかを確認します。したがって、全表スキャンの一部として1つのレコードのみが選択された場合でも、条件に従って適格なレコードを見つけるには、100Kレコードをスキャンする必要があります。
上記の表とデータに従って、次のクエリでは、データの大部分が選択されるため、順次スキャンが実行されます。
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)計画コストを計算して比較しなければ、どの種類のスキャンが使用されるかを判断することはほとんど不可能です。ただし、シーケンシャルスキャンを使用するには、少なくとも以下の基準が一致する必要があります。
- 述語の一部であるキーで使用可能なインデックスがありません。
- 行の大部分はSQLクエリの一部としてフェッチされています。
フェッチされる行がごくわずかで、述語が1つ(または複数)の列にある場合は、インデックスがある場合とない場合のパフォーマンスを評価してみてください。
シーケンシャルスキャンとは異なり、インデックススキャンはすべてのレコードをシーケンシャルにフェッチするわけではありません。むしろ、クエリに含まれるインデックスに対応する異なるデータ構造(インデックスのタイプに応じて)を使用し、最小限のスキャンで必要なデータ(述語ごと)句を見つけます。次に、インデックススキャンを使用して検出されたエントリは、ヒープ領域のデータを直接指します(上の図を参照)。このデータは、分離レベルに従って可視性を確認するためにフェッチされます。したがって、インデックススキャンには2つのステップがあります。
- インデックス関連のデータ構造からデータを取得します。対応するデータのTIDをヒープに返します。
- 次に、対応するヒープページに直接アクセスして、データ全体を取得します。この追加の手順は、以下の理由で必要です。
- クエリは、対応するインデックスで利用可能なものよりも多くの列をフェッチするように要求した可能性があります。
- 可視性情報はインデックスデータとともに維持されません。したがって、分離レベルごとにデータの可視性を確認するには、ヒープデータにアクセスする必要があります。
ここで、インデックススキャンが非常に効率的であるのに、なぜ常に使用しないのか疑問に思うかもしれません。ですから、私たちが知っているように、すべてにはいくらかのコストが伴います。ここで、関連するコストは、実行しているI/Oのタイプに関連しています。インデックススキャンの場合、インデックスストレージで見つかった各レコードに関してランダムI / Oが関与し、HEAPストレージから対応するデータをフェッチする必要がありますが、シーケンシャルスキャンの場合、シーケンスI / Oが関与します。これには約25%しかかかりません。ランダムI/Oタイミングの。
したがって、インデックススキャンは、ランダムI/Oコストのために全体的なゲインが発生したオーバーヘッドを上回っている場合にのみ選択する必要があります。
上記の表とデータに従って、次のクエリでは、1つのレコードのみが選択されるため、インデックススキャンが実行されます。そのため、ランダムI / Oが少なくなり、対応するレコードの検索が高速になります。
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)インデックスのみのスキャンは、2番目のステップを除いて、インデックススキャンに似ています。つまり、名前が示すように、インデックスデータ構造のみをスキャンします。インデックススキャンと比較してインデックスのみのスキャンを選択するには、2つの追加の前提条件があります。
- クエリは、インデックスの一部であるキー列のみをフェッチする必要があります。
- 選択したヒープページ上のすべてのタプル(レコード)が表示されている必要があります。前のセクションで説明したように、インデックスデータ構造は可視性情報を維持しないため、インデックスからのみデータを選択するには、可視性のチェックを回避する必要があります。これは、そのページのすべてのデータが可視であると見なされる場合に発生する可能性があります。
次のクエリは、インデックスのみのスキャンになります。このクエリは、レコード数の選択に関してはほぼ同じですが、キーフィールド(つまり「num」)のみが選択されるため、インデックスのみのスキャンが選択されます。
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)ビットマップスキャンは、インデックススキャンとシーケンシャルスキャンを組み合わせたものです。インデックススキャンの欠点を解決しようとしますが、それでも完全な利点を維持します。インデックスデータ構造で見つかった各データについて上記で説明したように、ヒープページで対応するデータを見つける必要があります。したがって、代わりに、インデックスページを一度フェッチしてからヒープページをフェッチする必要があります。これにより、多くのランダムI/Oが発生します。したがって、ビットマップスキャン方式は、ランダムI/Oなしのインデックススキャンの利点を活用します。これは、次の2つのレベルで機能します。
- ビットマップインデックススキャン:最初に、インデックスデータ構造からすべてのインデックスデータをフェッチし、すべてのTIDのビットマップを作成します。簡単に理解できるように、このビットマップにはすべてのページのハッシュが含まれ(ページ番号に基づいてハッシュされます)、各ページエントリにはそのページ内のすべてのオフセットの配列が含まれていると見なすことができます。
- ビットマップヒープスキャン:名前が示すように、ページのビットマップを読み取り、保存されているページとオフセットに対応するヒープからデータをスキャンします。最後に、可視性や述語などをチェックし、これらすべてのチェックの結果に基づいてタプルを返します。
以下のクエリでは、選択するレコードが非常に少ない(つまり、インデックススキャンには多すぎる)と同時に、大量のレコードを選択しない(つまり、シーケンシャルには少なすぎる)ため、ビットマップスキャンが発生します。スキャン)。
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)次に、同じ数のレコードを選択しますが、キーフィールドのみ(つまり、インデックス列のみ)を選択する以下のクエリについて考えてみます。キーのみを選択するため、データの他の部分のヒープページを参照する必要がなく、ランダムなI/Oが発生することはありません。したがって、このクエリはビットマップスキャンではなくインデックスのみのスキャンを選択します。
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TIDスキャン
TIDは、前述のように、4バイトのページ番号とページ内の残りの2バイトのタプルインデックスで構成される6バイトの番号です。 TIDスキャンはPostgreSQLの非常に特殊な種類のスキャンであり、クエリ述語にTIDがある場合にのみ選択されます。 TIDスキャンを示す以下のクエリを検討してください。
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)したがって、ここの述語では、条件として列の正確な値を指定する代わりに、TIDが提供されます。これは、OracleのROWIDベースの検索に似ています。
すべてのスキャン方法は広く使用されており、有名です。また、これらのスキャン方法は、ほとんどすべてのリレーショナルデータベースで利用できます。しかし、最近PostgreSQLコミュニティで議論されている別のスキャン方法があり、他のリレーショナルデータベースにも最近追加されています。これは、MySQLでは「LooseIndexScan」、Oracleでは「Index Skip Scan」、DB2では「JumpScan」と呼ばれています。
このスキャン方法は、Bツリーインデックスの先頭のキー列の個別の値が選択されている特定のシナリオで使用されます。このスキャンの一部として、最初の一意の値をトラバースしてから次の大きな値にジャンプするのではなく、すべての等しいキー列の値をトラバースすることを回避します。
この作業はPostgreSQLでまだ進行中であり、仮の名前は「Index Skip Scan」であり、将来のリリースでこれが見られる可能性があります。