今日では、企業のデータベースに大量のデータが表示されるのが一般的ですが、サイズによっては、適切な方法で構成または実装しないと、管理が困難になり、トラフィックが多いときにパフォーマンスに影響を与える可能性があります。 。一般に、巨大なデータベースがあり、応答時間を短くしたい場合は、それを拡張する必要があります。 PostgreSQLもこの点の例外ではありません。 PostgreSQLをスケーリングするために利用できるアプローチはたくさんありますが、最初に、スケーリングとは何かを学びましょう。
スケーラビリティは、リソースを追加することで増大する需要を処理するシステム/データベースの特性です。
この量の需要の理由は一時的なものである可能性があります。たとえば、顧客や従業員の増加のために、セールの割引や恒久的な割引を開始する場合などです。いずれの場合も、リソースを追加または削除して、必要に応じてこれらの変更を管理したり、トラフィックを増やしたりできるようにする必要があります。
このブログでは、PostgreSQLデータベースを拡張する方法と、それを実行する必要がある場合について説明します。
水平スケーリングと垂直スケーリング
データベースを拡張する主な方法は2つあります...
- 水平スケーリング(スケールアウト):データベースノードを追加してデータベースクラスターを作成または増加することで実行されます。
- 垂直スケーリング(スケールアップ):既存のデータベースノードにハードウェアリソース(CPU、メモリ、ディスク)を追加することで実行されます。
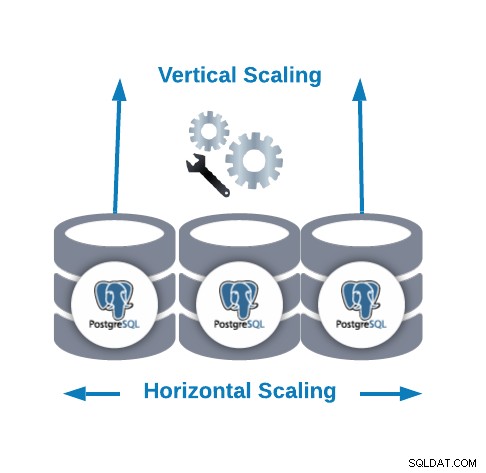
水平スケーリングの場合、スレーブノードとしてデータベースノードをさらに追加できます。これは、ノード間のトラフィックのバランスをとる読み取りパフォーマンスを向上させるのに役立ちます。この場合、ポリシーとノードの状態に応じて、トラフィックを正しいノードに分散するためにロードバランサーを追加する必要があります。
ロードバランサーを1つだけ追加する単一障害点を回避するには、2つ以上のロードバランサーノードを追加し、「キープアライブ」などのツールを使用して可用性を確保することを検討する必要があります。
PostgreSQLにはネイティブのマルチマスターサポートがないため、書き込みパフォーマンスを向上させるためにPostgreSQLを実装する場合は、このタスクに外部ツールを使用する必要があります。
垂直スケーリングの場合、PostgreSQLが新しいまたはより優れたハードウェアリソースを使用できるように、いくつかの構成パラメーターを変更する必要がある場合があります。 PostgreSQLのドキュメントからこれらのパラメータのいくつかを見てみましょう。
- work_mem:一時ディスクファイルに書き込む前に、内部ソート操作とハッシュテーブルによって使用されるメモリの量を指定します。複数の実行中のセッションがそのような操作を同時に実行している可能性があるため、使用されるメモリの合計はwork_memの値の何倍にもなる可能性があります。
- maintenance_work_mem:VACUUM、CREATE INDEX、ALTER TABLE ADDFOREIGNKEYなどのメンテナンス操作で使用されるメモリの最大量を指定します。設定を大きくすると、バキューム処理とデータベースダンプの復元のパフォーマンスが向上する可能性があります。
- autovacuum_work_mem:各autovacuumワーカープロセスで使用されるメモリの最大量を指定します。
- autovacuum_max_workers:一度に実行できる自動真空プロセスの最大数を指定します。
- max_worker_processes:システムがサポートできるバックグラウンドプロセスの最大数を設定します。バキューム、チェックポイント、その他のメンテナンスジョブなどのプロセスの制限を指定します。
- max_parallel_workers:システムが並列操作でサポートできるワーカーの最大数を設定します。並列ワーカーは、前のパラメーターによって確立されたワーカープロセスのプールから取得されます。
- max_parallel_maintenance_workers:単一のユーティリティコマンドで開始できる並列ワーカーの最大数を設定します。現在、並列ワーカーの使用をサポートする唯一の並列ユーティリティコマンドは、CREATE INDEXであり、Bツリーインデックスを作成する場合のみです。
- effective_cache_size:単一のクエリで使用できるディスクキャッシュの有効サイズに関するプランナーの仮定を設定します。これは、インデックスを使用するコストの見積もりに考慮されます。値が大きいほどインデックススキャンが使用される可能性が高くなり、値が低いほどシーケンシャルスキャンが使用される可能性が高くなります。
- shared_buffers:データベースサーバーが共有メモリバッファに使用するメモリの量を設定します。良好なパフォーマンスを得るには、通常、最小値よりも大幅に高い設定が必要です。
- temp_buffers:各データベースセッションで使用される一時バッファーの最大数を設定します。これらは、一時テーブルへのアクセスにのみ使用されるセッションローカルバッファです。
- effective_io_concurrency:PostgreSQLが同時に実行できると予想する同時ディスクI/O操作の数を設定します。この値を上げると、個々のPostgreSQLセッションが並行して開始しようとするI/O操作の数が増えます。現在、この設定はビットマップヒープスキャンにのみ影響します。
- max_connections:データベースサーバーへの同時接続の最大数を決定します。このパラメータを増やすと、PostgreSQLがより多くのバックエンドプロセスを同時に実行できるようになります。
この時点で、私たちが尋ねなければならない質問があります。データベースを拡張する必要があるかどうかをどのように知ることができ、それを行うための最良の方法をどのように知ることができますか?
監視
PostgreSQLデータベースのスケーリングは複雑なプロセスであるため、いくつかのメトリックをチェックして、スケーリングするための最適な戦略を決定できるようにする必要があります。
CPU、メモリ、ディスクの使用状況を監視して、構成に問題があるかどうか、または実際にデータベースを拡張する必要があるかどうかを判断できます。たとえば、サーバーの負荷が高く、データベースアクティビティが低い場合は、スケーリングする必要はないでしょう。構成パラメータを確認するだけで、ハードウェアリソースと一致させることができます。
データベースごとにPostgreSQLノードが使用するディスク容量を確認すると、さらにディスクが必要かどうか、さらにはテーブルのパーティション分割が必要かどうかを確認するのに役立ちます。データベース/テーブルで使用されているディスク容量を確認するには、pg_database_sizeやpg_table_sizeなどのPostgreSQL関数を使用できます。
データベース側から確認する必要があります
- 接続量
- クエリの実行
- インデックスの使用法
- 膨張
- レプリケーションラグ
これらは、データベースのスケーリングが必要かどうかを確認するための明確な指標になる可能性があります。
スケーリングおよび監視システムとしてのClusterControl
ClusterControlは、以前に見た両方のスケーリング方法に対処し、スケーリング要件を確認するために必要なすべてのメトリックを監視するのに役立ちます。方法を見てみましょう...
ClusterControlをまだ使用していない場合は、インストールし、現在のPostgreSQLデータベースをデプロイまたはインポートして、[インポート]オプションを選択し、手順に従って、バックアップ、自動フェイルオーバー、アラート、監視などのClusterControlのすべての機能を利用できます。など。
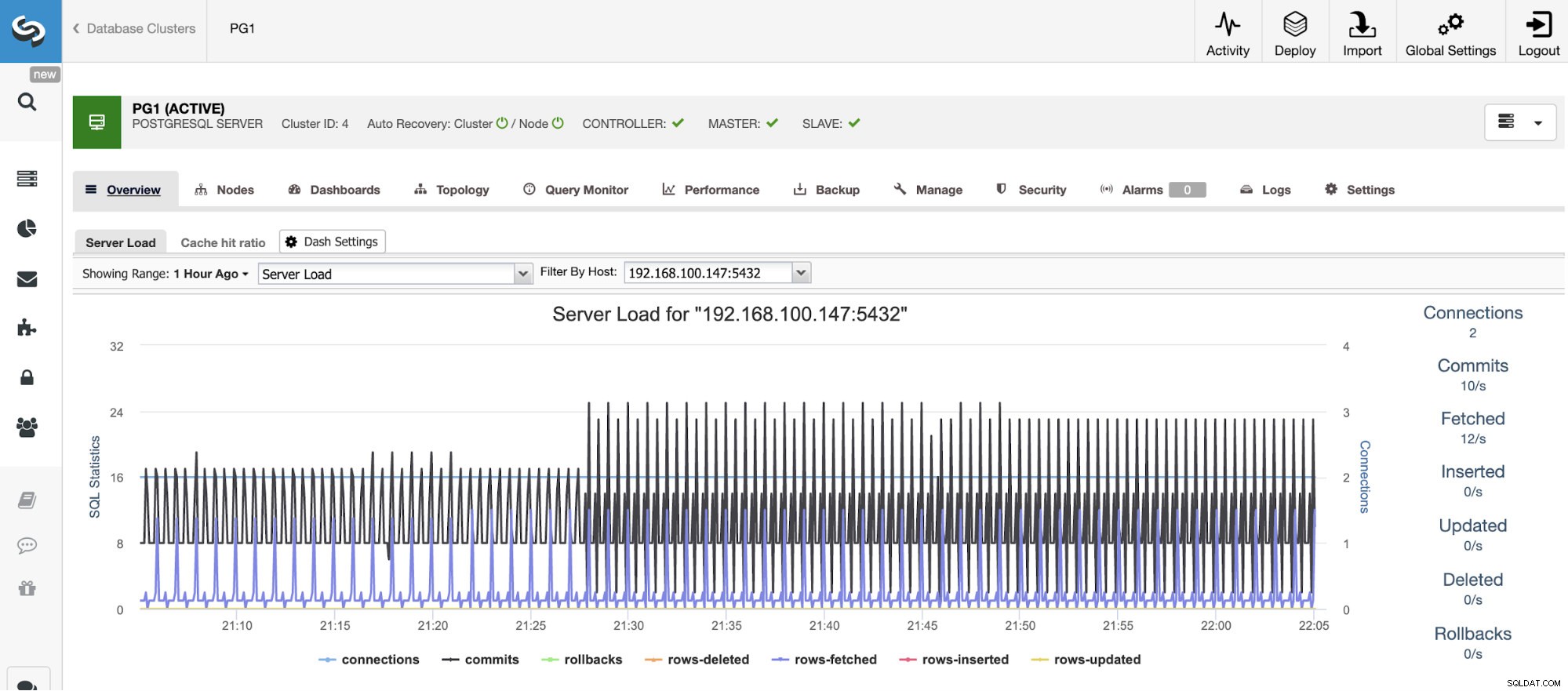
水平スケーリング
水平スケーリングの場合、クラスターアクションに移動して[レプリケーションスレーブの追加]を選択すると、新しいレプリカを最初から作成するか、既存のPostgreSQLデータベースをレプリカとして追加できます。
新しいレプリケーションスレーブを追加することが本当に簡単な作業になる方法を見てみましょう。
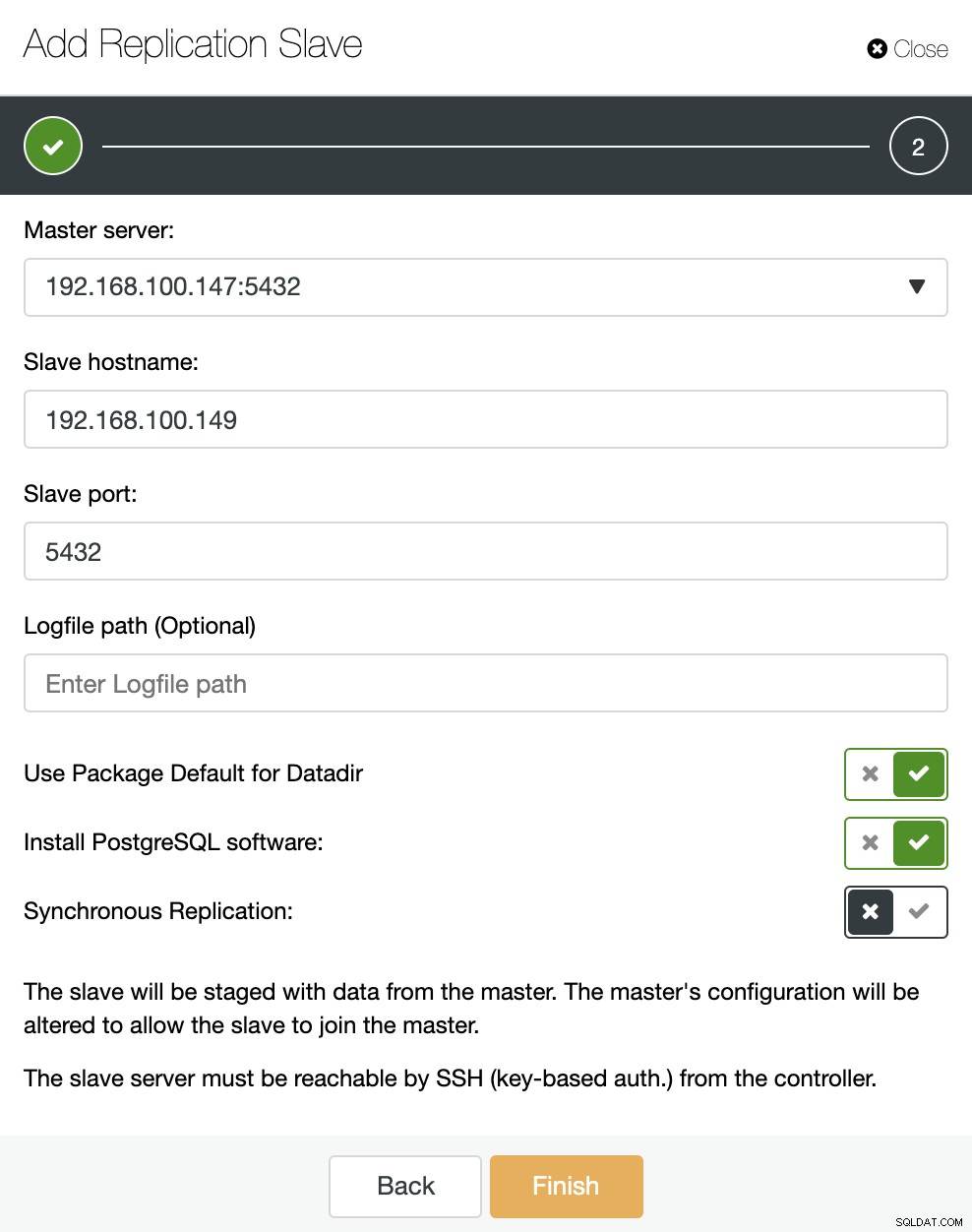
画像でわかるように、マスターサーバーを選択し、新しいスレーブサーバーのIPアドレスとデータベースポートを入力するだけです。次に、ClusterControlにソフトウェアをインストールさせるかどうか、およびレプリケーションスレーブを同期にするか非同期にするかを選択できます。
このようにして、必要な数のレプリカを追加し、ロードバランサーを使用してそれらの間で読み取りトラフィックを分散できます。これはClusterControlでも実装できます。
ここで、クラスターアクションに移動して[ロードバランサーの追加]を選択すると、新しいHAProxyロードバランサーをデプロイするか、既存のHAProxyロードバランサーを追加できます。
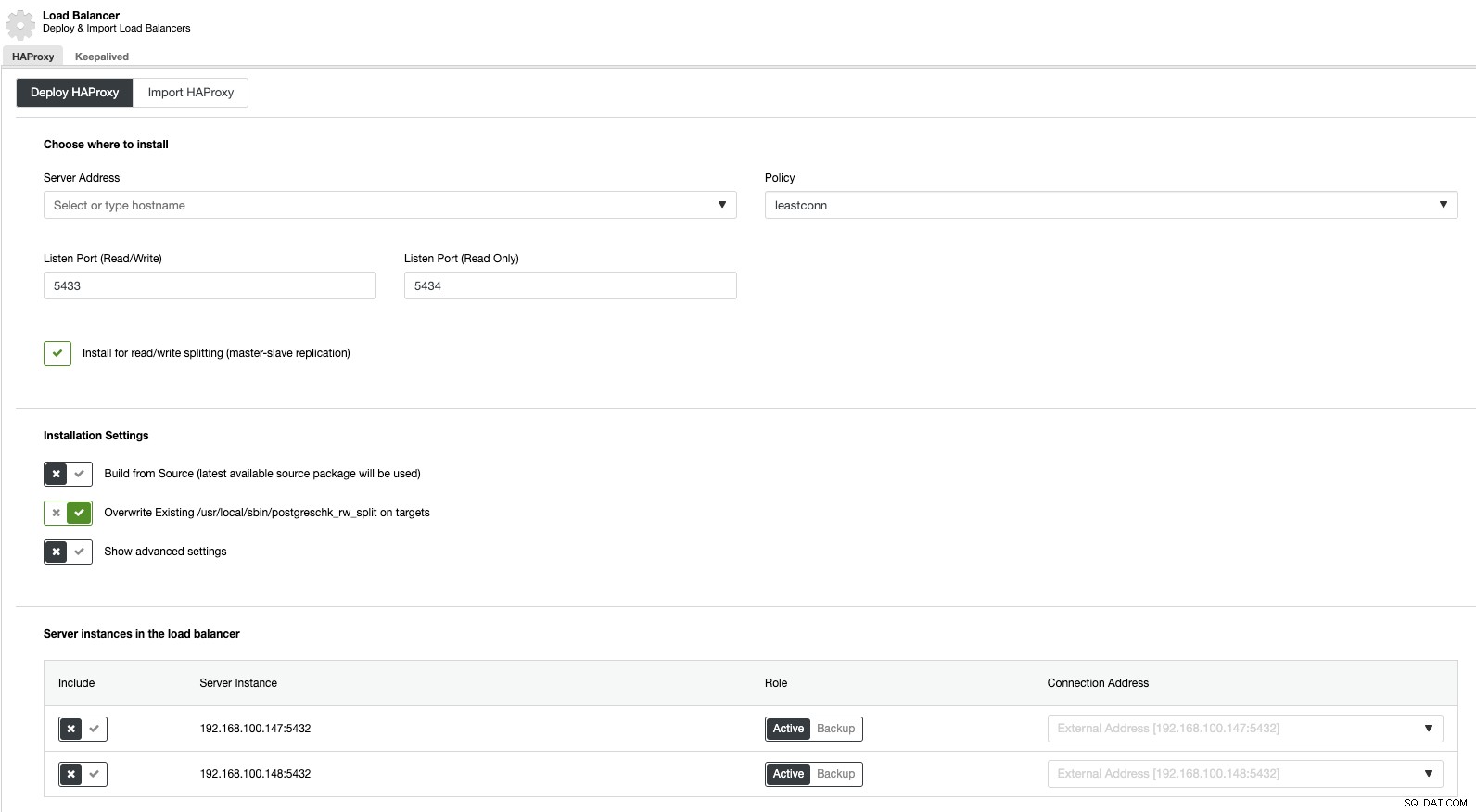
次に、同じロードバランサーセクションで、ロードバランサーノードで実行されるKeepalivedサービスを追加して、高可用性環境を改善できます。
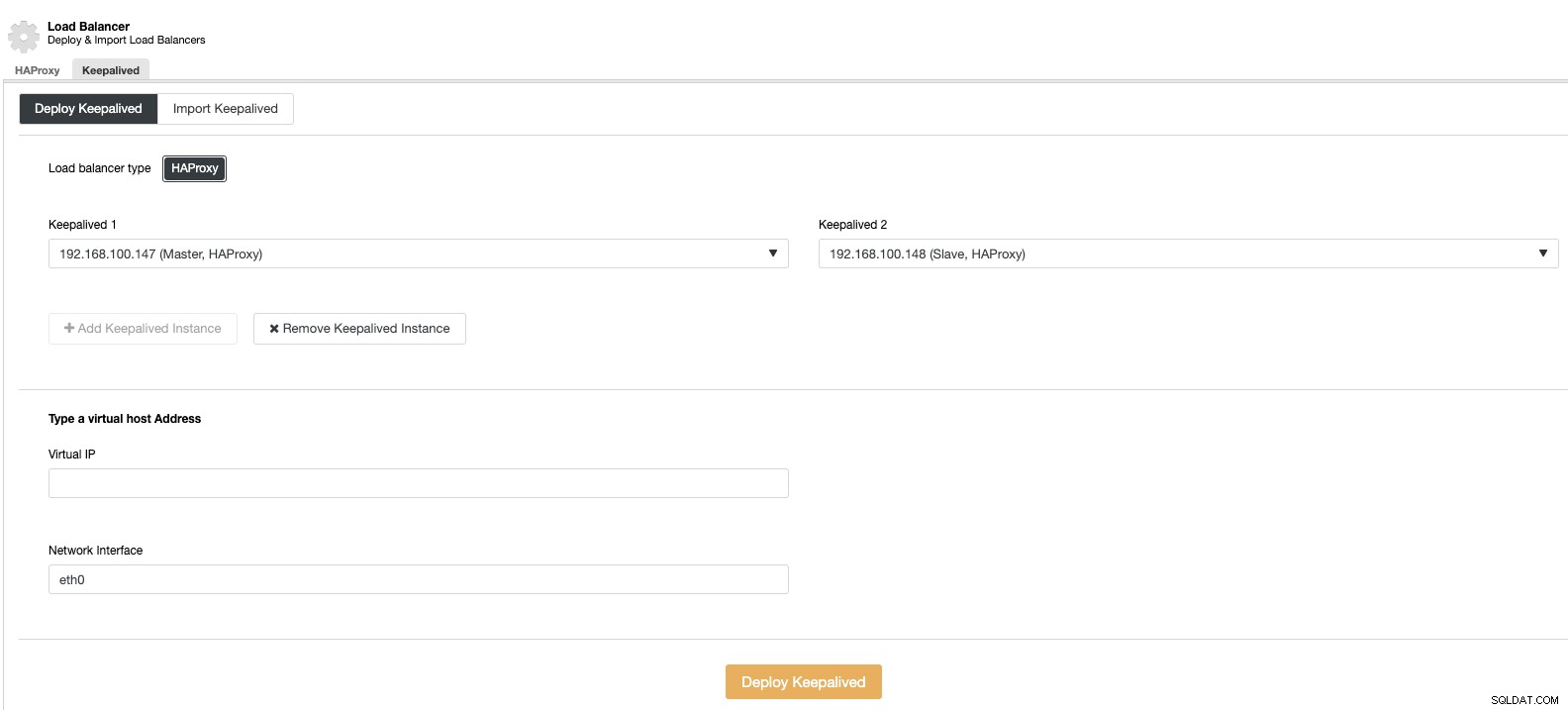
垂直スケーリング
垂直スケーリングの場合、ClusterControlを使用すると、オペレーティングシステムとデータベース側の両方からデータベースノードを監視できます。 CPU使用率、メモリ、接続、上位クエリ、実行中のクエリなど、いくつかの指標を確認できます。ダッシュボードセクションを有効にすることもできます。これにより、メトリックをより詳細に、よりわかりやすく表示できます。
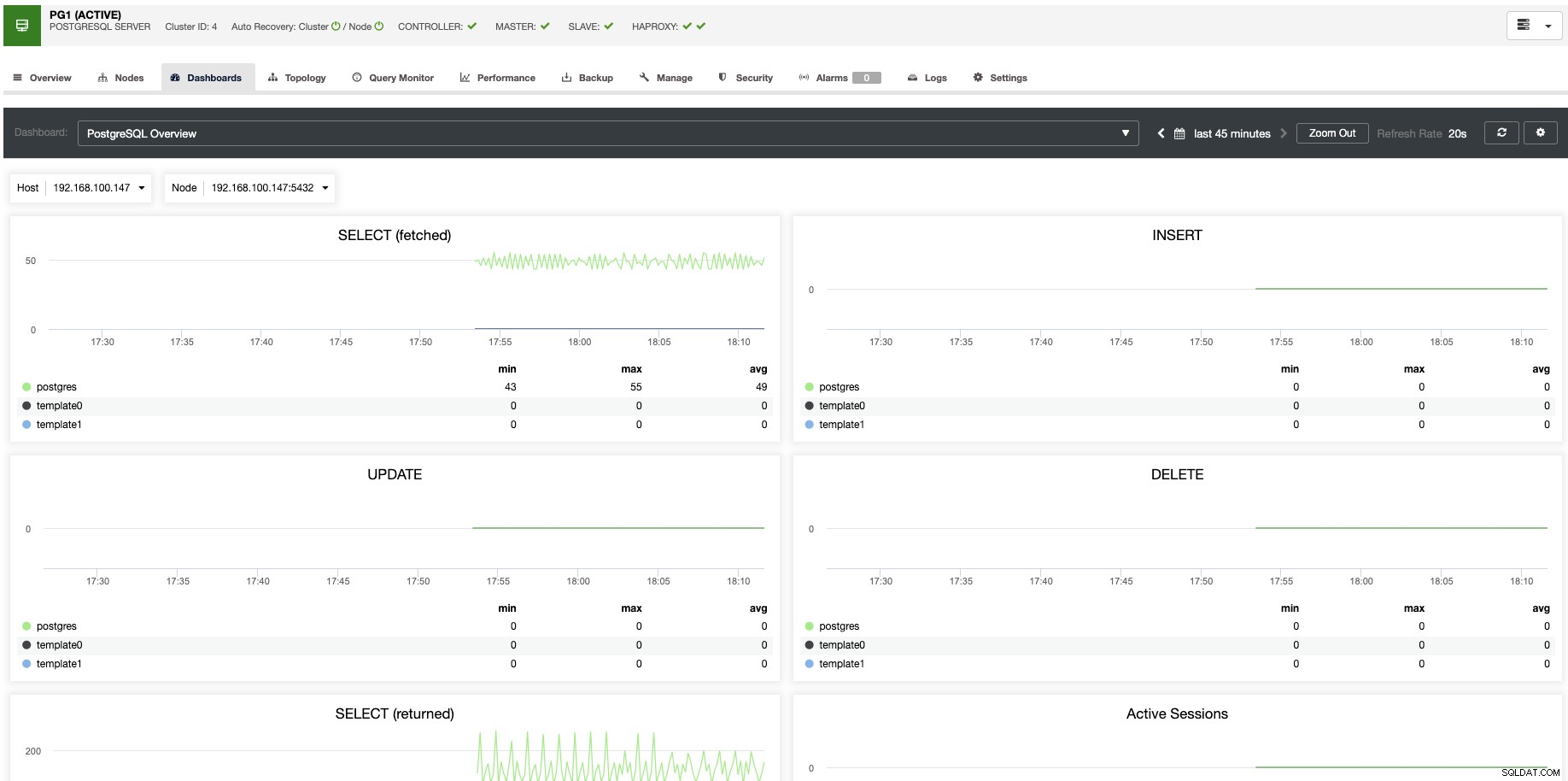
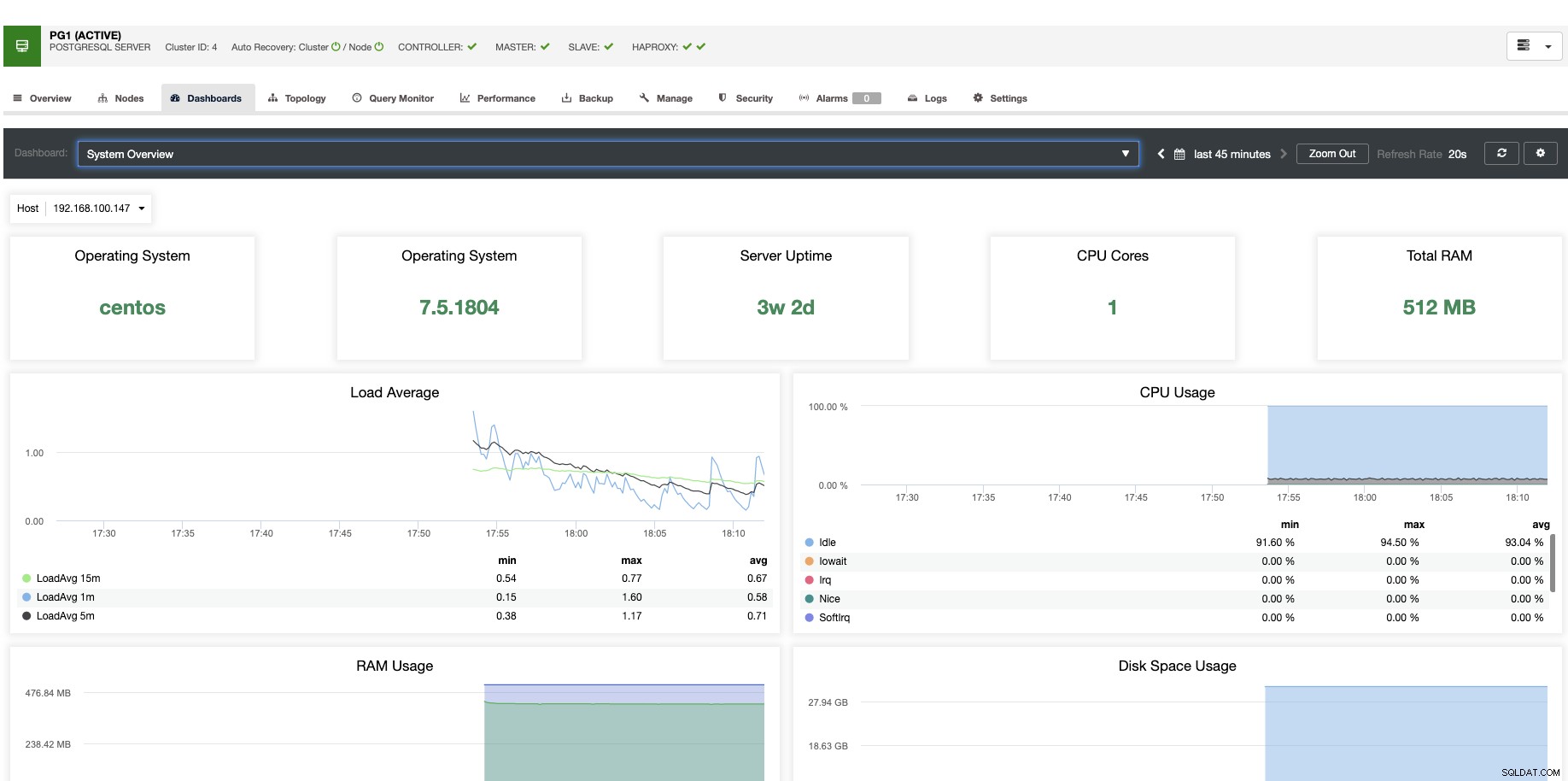
ClusterControlから、ワンクリックで、ホストの再起動、レプリケーションスレーブの再構築、スレーブのプロモートなどのさまざまな管理タスクを実行することもできます。
結論
PostgreSQLデータベースのスケールアウトは時間のかかる作業になる可能性があります。何をスケーリングする必要があるのか、そしてそれを行うための最良の方法は何かを知る必要があります。最終的に、クラスターを手動で管理およびスケーリングすることは、特定の時点を過ぎると非常に負担になるため、ほとんどの場合、私たちのようなツールを使用します。
手動ルートを選択した場合は、クラスターにノードを追加することを検討する時期を確認してください。面倒を避けたいですか? ClusterControlを30日間無料で評価して、その機能が大規模なオープンソースの処理をシンプルかつ効率的にする方法を確認してください。
ただし、データベースを管理および拡張したい場合は、TwitterまたはLinkedInでフォローするか、ニュースレターを購読して、オープンソースベースのデータベースインフラストラクチャを管理する際の最新ニュースとベストプラクティスを入手してください。すぐにお会いしましょう!
>