PostgreSQLは素晴らしいプロジェクトであり、驚くべき速度で進化しています。一連のブログ投稿を使用して、バージョン全体でPostgreSQLのフォールトトレランス機能の進化に焦点を当てます。これはシリーズの4回目の投稿であり、同期コミットと、PostgreSQLのフォールトトレランスと信頼性に対する同期コミットの影響について説明します。
最初から進化の進展を目撃したい場合は、以下のシリーズの最初の3つのブログ投稿を確認してください。各投稿は独立しているため、実際に読んで別の投稿を理解する必要はありません。
- PostgreSQLのフォールトトレランスの進化
- PostgreSQLのフォールトトレランスの進化:レプリケーションフェーズ
- PostgreSQLのフォールトトレランスの進化:タイムトラベル
同期コミット
デフォルトでは、PostgreSQLは非同期レプリケーションを実装しており、サーバーにとって都合のよいときにいつでもデータがストリーミングされます。これは、フェイルオーバーの場合にデータが失われることを意味します。コミットする前にデータのレプリケーションを確認するために1つ(または複数)のスタンバイを要求するようにPostgresに要求することができます。これは同期レプリケーション(同期コミット)と呼ばれます。 ) 。
同期レプリケーションでは、レプリケーションの遅延は直接 マスターでのトランザクションの経過時間に影響します。非同期レプリケーションでは、マスターはフルスピードで続行できます。
同期レプリケーションは、データが少なくともに書き込まれることを保証します トランザクションがコミットされたことがユーザーまたはアプリケーションに通知される前の2つのノード。
ユーザーは各トランザクションのコミットモードを選択できます 、同期と非同期の両方のコミットトランザクションを同時に実行できるようにします。
これにより、パフォーマンスとトランザクションの耐久性の確実性の間で柔軟なトレードオフが可能になります。
同期コミットの構成
Postgresで同期レプリケーションを設定するには、synchronous_commitを設定する必要があります postgresql.confのパラメータ。
このパラメータは、コマンドが成功を返す前に、トランザクションコミットがWALレコードがディスクに書き込まれるのを待つかどうかを指定します クライアントへの表示。有効な値は、synchronous_commitを設定するときに、同期レプリケーションの観点からどのように機能するかについて説明します。 定義された各値を持つパラメータ。
Postgresのドキュメント(9.6)から始めましょう:
ここでは、投稿の冒頭で説明したように、同期コミットの概念を理解しています。同期レプリケーションは自由に設定できますが、設定しないと、データが失われるリスクが常にあります。ただし、fsync offとは異なり、データベースの不整合を引き起こすリスクはありません。 –しかし、それは別の投稿のトピックです-。最後に、レプリケーションの遅延の間にデータを失いたくない場合は、トランザクションがコミットされたことをユーザー/アプリケーションに通知する前に、データが少なくとも2つのノードに書き込まれるようにする必要があると結論付けます。 、パフォーマンスの低下を受け入れる必要があります。
同期のレベルごとに異なる設定がどのように機能するかを見てみましょう。始める前に、PostgreSQLレプリケーションによってcommitがどのように処理されるかについて説明しましょう。クライアントはマスターノードでクエリを実行し、変更はトランザクションログ(WAL)に書き込まれ、ネットワーク経由でスタンバイノードのWALにコピーされます。次に、スタンバイノードのリカバリプロセスがWALから変更を読み取り、クラッシュリカバリの場合と同じようにデータファイルに適用します。スタンバイがホットスタンバイの場合 モードの場合、クライアントは、これが発生している間、ノードで読み取り専用クエリを発行できます。レプリケーションの仕組みの詳細については、このシリーズのレプリケーションブログ投稿をご覧ください。
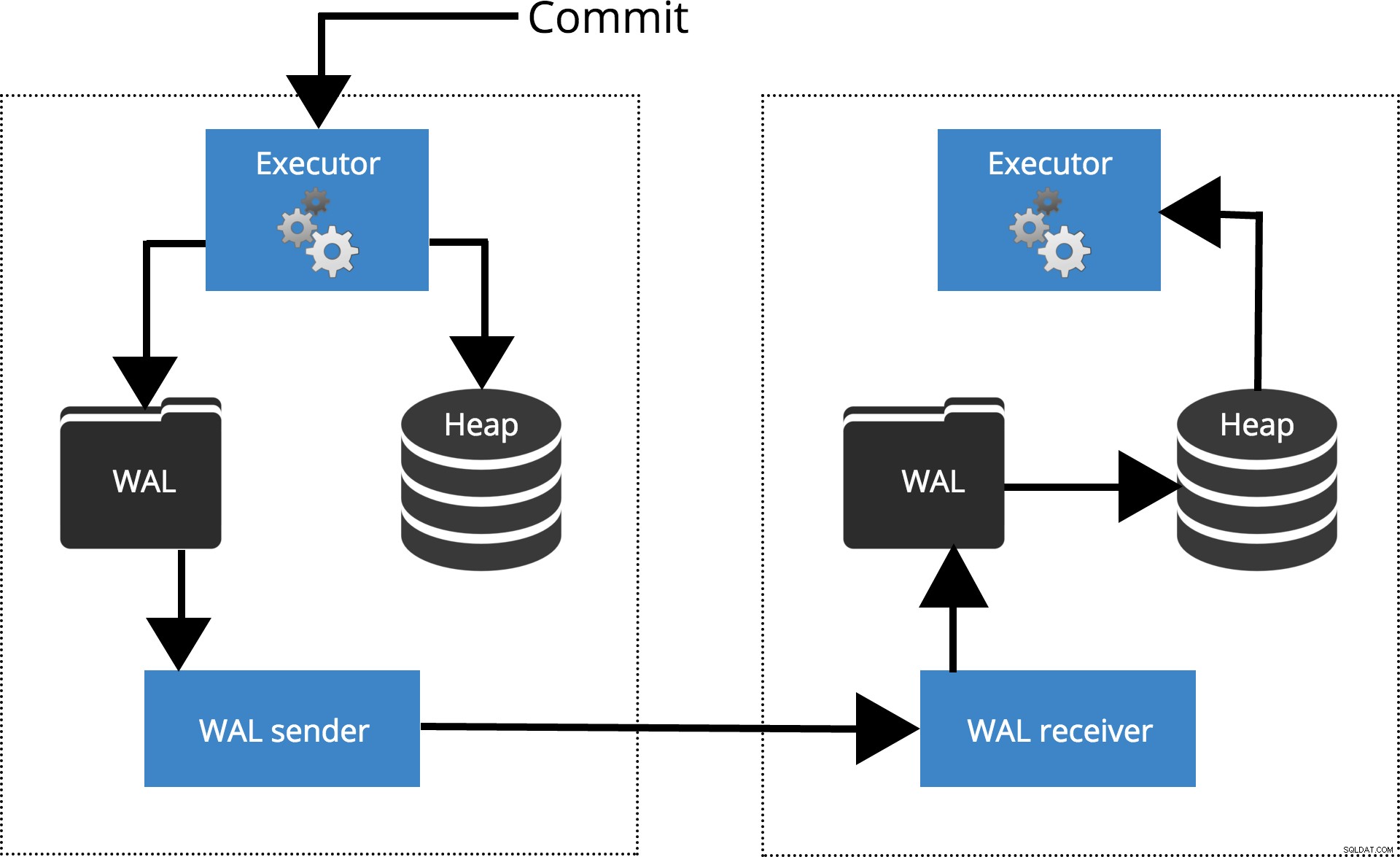
図1レプリケーションの仕組み
Synchronous_commit=オフ
sychronous_commit = off, COMMIT トランザクションレコードがディスクにフラッシュされるのを待ちません。これは下の図2で強調表示されています。
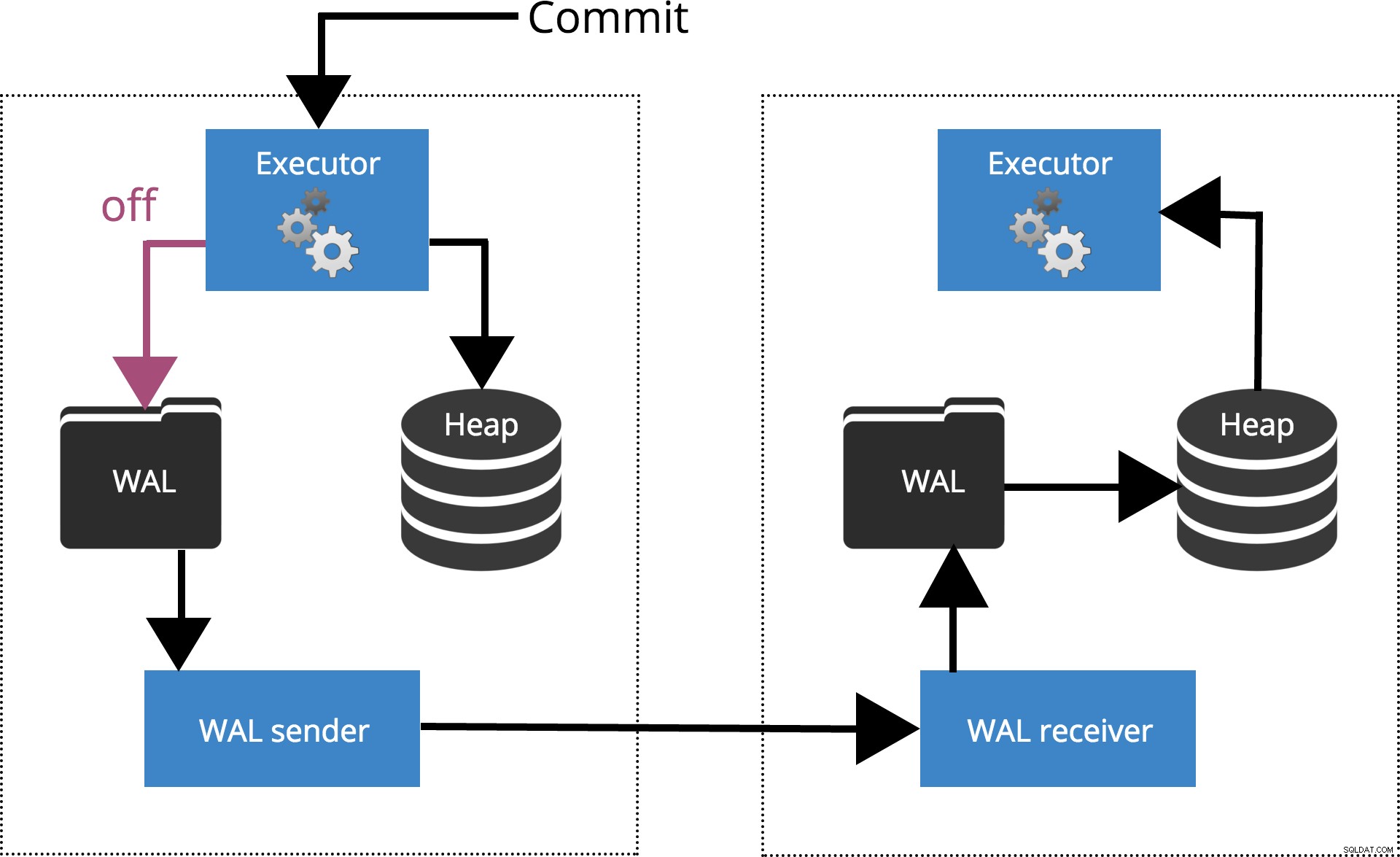
図2synchronous_commit =off
Synchronous_commit =local
synchronous_commit = local,を設定すると COMMIT トランザクションレコードがローカルディスクにフラッシュされるまで待機します。これは下の図3で強調表示されています。
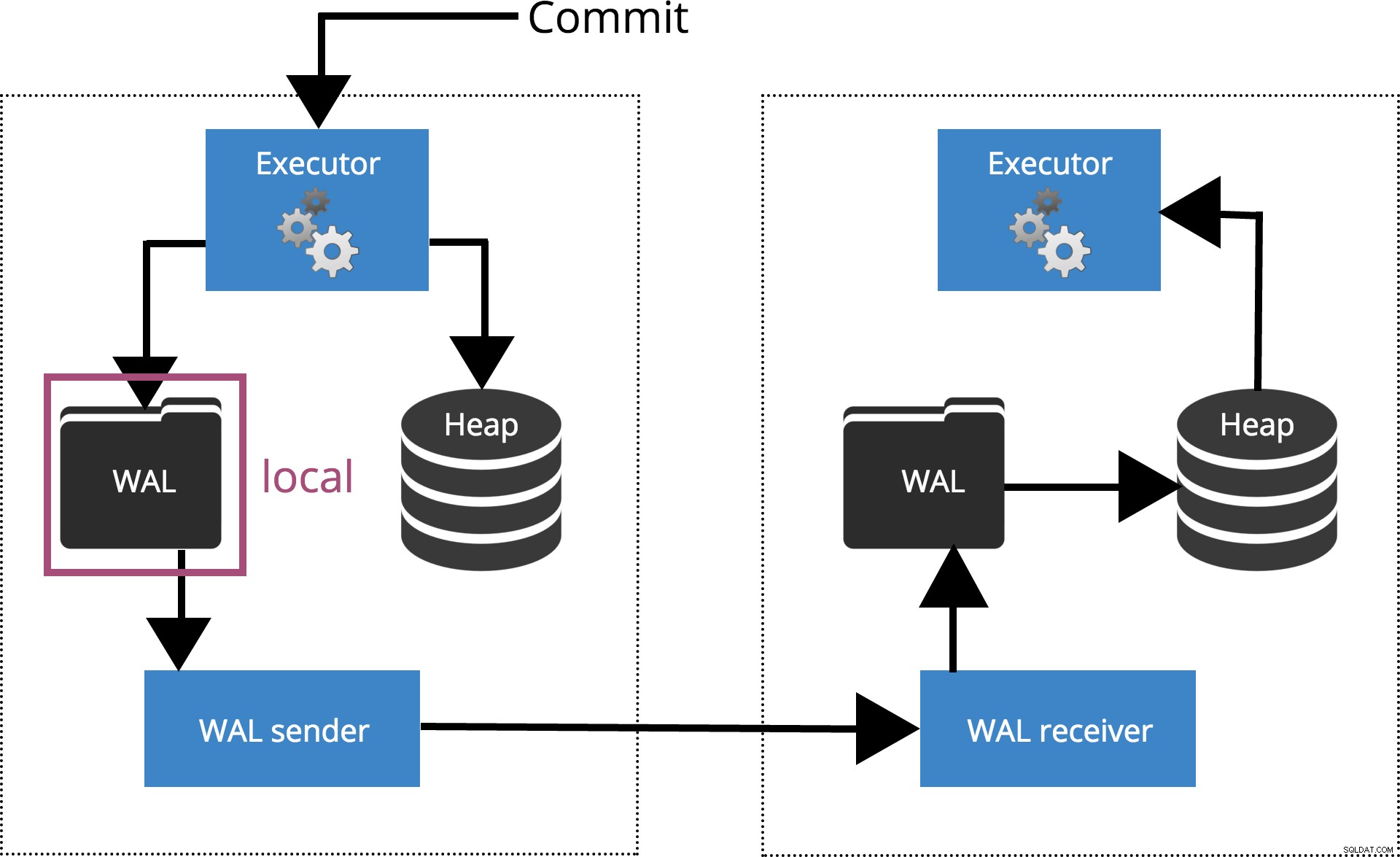
図3synchronous_commit =local
synchronous_commit =on(デフォルト)
synchronous_commit = on, COMMIT synchronous_standby_namesで指定されたサーバーまで待機します トランザクションレコードが安全にディスクに書き込まれたことを確認します。これは下の図4で強調表示されています。
注: synchronous_standby_namesの場合 が空の場合、この設定はsynchronous_commit = localと同じように動作します 。
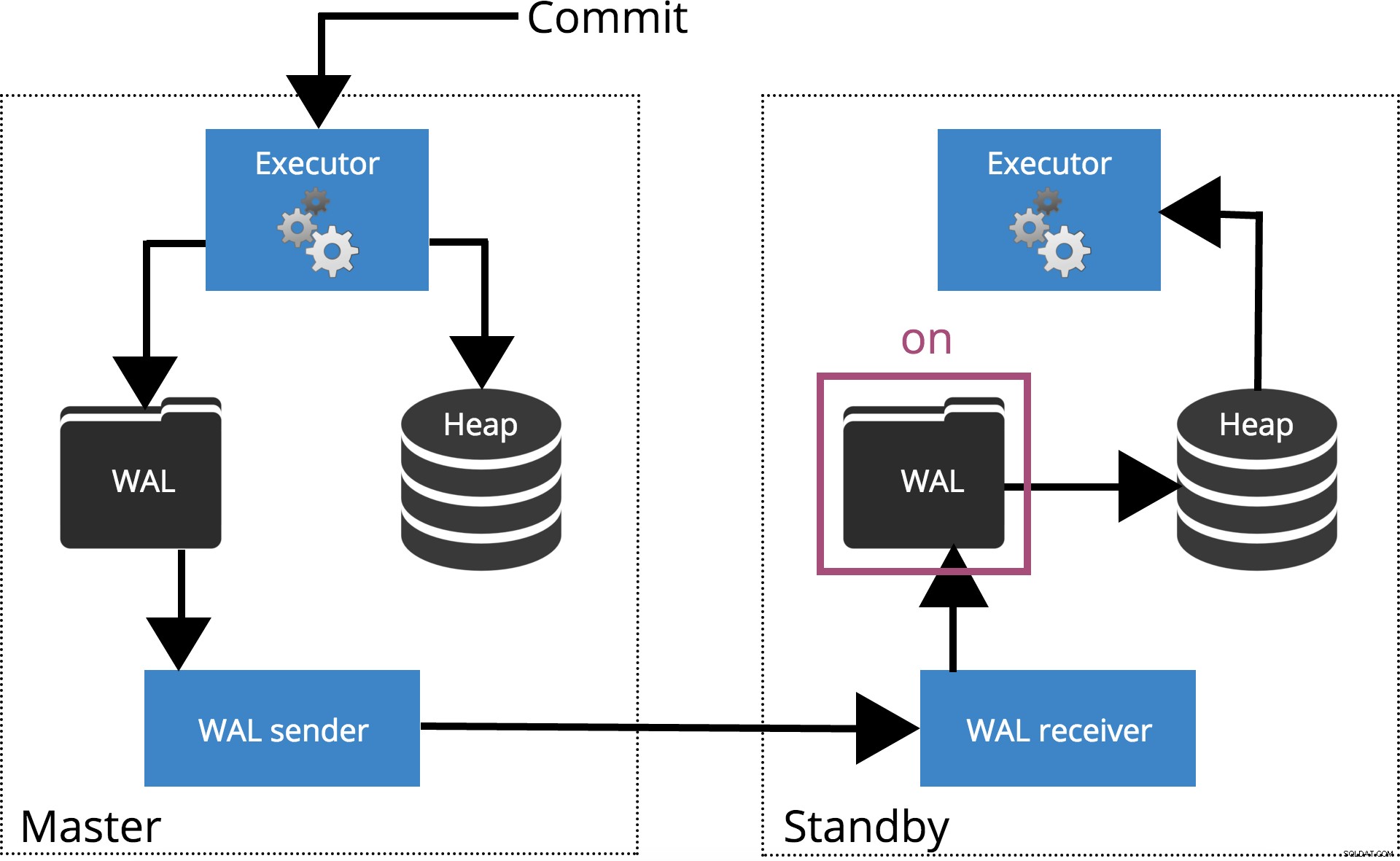
図4synchronous_commit =on
Synchronous_commit =remote_write
synchronous_commit = remote_write,を設定すると COMMIT synchronous_standby_namesで指定されたサーバーまで待機します オペレーティングシステムへのトランザクションレコードの書き込みを確認しますが、必ずしもディスクに到達しているとは限りません。これは、下の図5で強調表示されています。
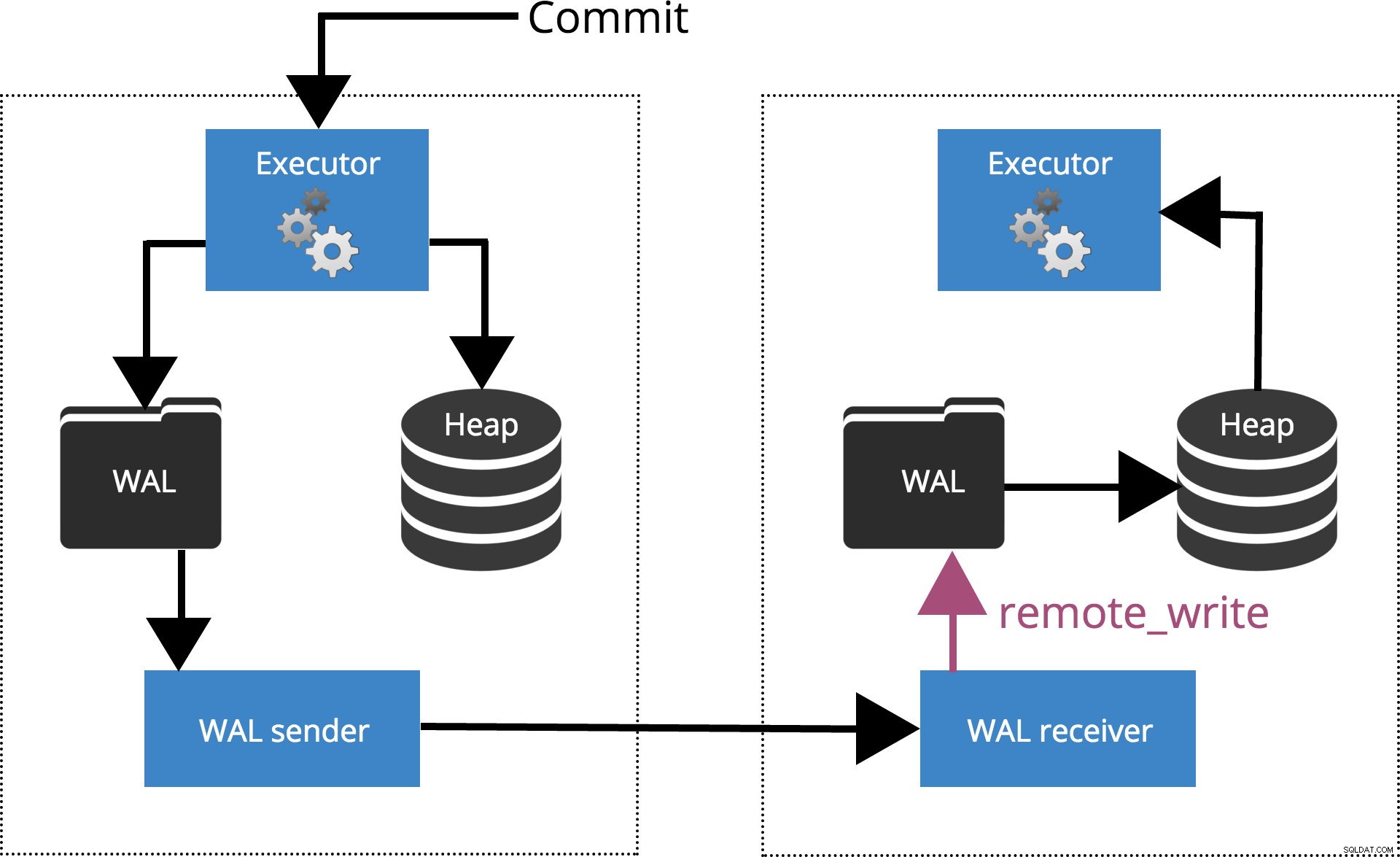
図5synchronous_commit =remote_write
Synchronous_commit =remote_apply
synchronous_commit = remote_apply,を設定すると COMMIT synchronous_standby_namesで指定されたサーバーまで待機します トランザクションレコードがデータベースに適用されたことを確認します。これは下の図6で強調表示されています。
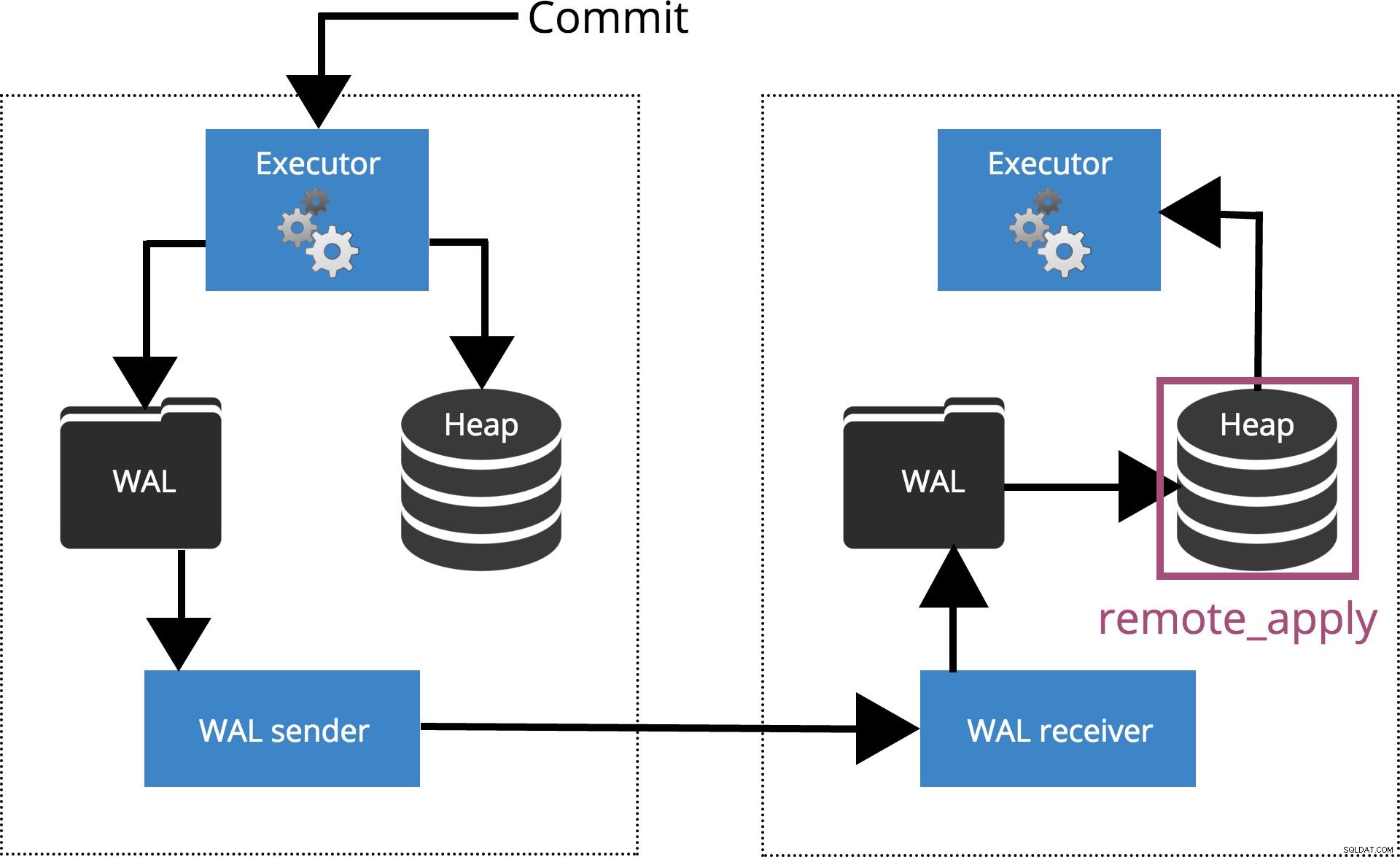
図6synchronous_commit =remote_apply
それでは、synchronous_standby_namesを見てみましょう。 パラメータの詳細。synchronous_commitを設定するときに上記で参照されます。 onとして 、remote_apply またはremote_write 。
synchronous_standby_names =‘standby_name [、…]’
同期コミットは、優先順位の順にリストされているスタンバイの1つからの応答を待ちます。これは、最初のスタンバイが接続されてストリーミングされている場合、2番目のスタンバイがすでに応答している場合でも、同期コミットは常にそれからの応答を待機することを意味します。 *の特別な値 stanby_nameとして使用できます これは、接続されているスタンバイと一致します。
synchronous_standby_names =‘num(standby_name [、…])’
同期コミットは、少なくともnumからの応答を待ちます 優先順位順にリストされているスタンバイの数。上記と同じルールが適用されます。したがって、たとえば、synchronous_standby_names = '2 (*)'を設定します。 同期コミットは、任意の2台のスタンバイサーバーからの応答を待機します。
synchronous_standby_namesは空です
示されているようにこのパラメーターが空の場合、synchronous_commitの設定の動作が変わります。 on 、remote_write またはremote_apply localと同じように動作します (つまり、COMMIT ローカルディスクへのフラッシュのみを待機します。
結論
このブログ投稿では、同期レプリケーションについて説明し、Postgresで利用できるさまざまなレベルの保護について説明しました。次のブログ投稿で論理レプリケーションを続行します。
参照
イラストのアイデアをくれた同僚のPetrJelinekに特に感謝します。
PostgreSQLドキュメント
PostgreSQL9管理クックブック–第2版