ビジネスアプリケーションにサービスを提供するデータベースは、多くの場合、一時データをサポートする必要があります。たとえば、サプライヤとの契約が期間限定で有効であるとします。特定の時点から有効にすることも、開始時点から終了時点までの特定の時間間隔で有効にすることもできます。さらに、多くの場合、1つ以上のテーブルのすべての変更を監査する必要があります。また、特定の時点での状態、または特定の期間にテーブルに加えられたすべての変更を表示できる必要がある場合もあります。データの整合性の観点から、多くの追加の時間固有の制約を実装する必要がある場合があります。
時間データの紹介
時間的サポートのあるテーブルでは、ヘッダーは、間隔を表す少なくとも1回のパラメーターを持つ述語を表します。 残りの述語が有効な場合、つまり、完全な述語はタイムスタンプ付きの述語です。行はタイムスタンプ付きの提案を表し、行の有効期間は通常、 fromの2つの属性で表されます。 およびto 、または開始 および終了 。
時間テーブルの種類
紹介の部分で、2種類の時間的な問題があることに気づいたかもしれません。 1つ目は、有効期間です。 命題の–テーブル内のタイムスタンプ付きの行が表す命題が実際に真であった期間。たとえば、サプライヤとの契約は、時点1から時点2までのみ有効でした。この種の有効期間は、人々にとって意味があり、ビジネスにとっても意味があります。有効期間は、申請時間とも呼ばれます。 または人間の時間 。同じエンティティに対して複数の有効期間を設定できます。たとえば、時点1から時点2まで有効だった前述の契約は、時点7から時点9までも有効である可能性があります。
2番目の一時的な問題は、トランザクション時間です。 。上記の契約の行は、時点1に挿入され、誰かがそれを変更するまで、または時間の終わりまで、データベースに知られている唯一の真実のバージョンでした。行が時点2で更新されると、元の行は時点1から時点2までデータベースに真であることがわかりました。同じ提案の新しい行が、時点2から時点2までのデータベースに有効な時間で挿入されます。時間の終わり。トランザクション時間は、システム時間とも呼ばれます。 またはデータベース時間 。
もちろん、アプリケーションとシステムの両方のバージョン管理されたテーブルを実装することもできます。このようなテーブルはbitemporal と呼ばれます テーブル。
SQL Server 2016では、システムバージョンの一時テーブルを使用して、すぐに使用できるシステム時間のサポートを利用できます。 。アプリケーション時間を実装する必要がある場合は、自分でソリューションを開発する必要があります。
アレンの音程演算子
リレーショナルモデルの時間データの理論は、30年以上前に進化し始めました。かなりの数の便利なブール演算子と、間隔を処理して間隔を返すいくつかの演算子を紹介します。これらの演算子は、アレンの演算子として知られています。これは、1983年の研究論文で時間間隔に関する多数の演算子を定義したJ.F.アレンにちなんで名付けられました。それらのすべては、まだ有効で必要なものとして受け入れられています。データベース管理システムは、これらの演算子をすぐに実装することで、アプリケーション時間の処理に役立つ可能性があります。
まず、使用する表記法を紹介します。 i 1で示される2つの間隔で作業します およびi 2 。最初の間隔の開始時点はb 1です。 、そして終わりは e 1 ; 2番目の間隔の開始時点はb 2です。 終わりはe 2 。アレンのブール演算子 次の表で定義されています。
[table id =2 /]
ブール演算子に加えて、入力パラメータとして間隔を受け入れ、間隔を返すAllenの3つの演算子があります。これらの演算子は、単純な区間代数を構成します 。これらの演算子は、おそらくすでに使い慣れている関係演算子と同じ名前であることに注意してください:Union、Intersect、およびMinus。ただし、リレーショナルの対応物とまったく同じように動作するわけではありません。一般に、3つの区間演算子のいずれかを使用して、操作によって空の時点のセットまたは1つの区間で記述できないセットが生じる場合、演算子はNULLを返す必要があります。 2つの間隔の和集合は、間隔が一致または重複している場合にのみ意味があります。交差は、間隔が重なっている場合にのみ意味があります。マイナス間隔演算子は、場合によってのみ意味があります。たとえば、(3:10)マイナス(5:7)は、結果を1つの間隔で記述できないため、NULLを返します。次の表は、区間代数の演算子の定義をまとめたものです。
[テーブルID=3 /]
重複クエリのパフォーマンスの問題実装する最も複雑な演算子の1つは、重複です。 オペレーター。重複する間隔を見つける必要があるクエリは、最適化するのが簡単ではありません。ただし、このようなクエリは一時テーブルで非常に頻繁に発生します。この記事と次の2つの記事では、このようなクエリを最適化するいくつかの方法を紹介します。しかし、解決策を紹介する前に、問題を紹介しましょう。
問題を説明するために、いくつかのデータが必要です。次のコードは、 bで表される有効期間を持つテーブルを作成する方法の例を示しています。 およびe 列。間隔の開始と終了は整数で表されます。このテーブルには、WideWorldImporters.Sales.OrderLinesテーブルのデモデータが入力されています。 WideWorldImportersには複数のバージョンがあることに注意してください データベースなので、わずかに異なる結果が得られる可能性があります。 https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0のWideWorldImporters-Standard.bakバックアップファイルを使用して、SQLServerインスタンスにこのデモデータベースを復元しました。
デモデータの作成
デモテーブルを作成しましたdbo.Intervals tempd 次のコードのデータベース。
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
インデックスにも注意してください 作成した。 2つのインデックスは、間隔の開始時または間隔の終了時の検索に最適です。次のコードを使用して、すべての間隔の最小開始と最大終了を確認できます。
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
結果から、最小の開始時点が1で、最大の終了時点が1155であることがわかります。
データにコンテキストを与える
私が時点の開始と終了を表していることに気付くかもしれません。 整数として。次に、間隔に時間のコンテキストを与える必要があります。この場合、単一の時点は日を表します 。次のコードは、日付ルックアップテーブルを作成します そしてそれを投入します。開始日は2014年7月1日であることに注意してください。
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
これで、dbo.Intervalsテーブルをdbo.DateNumsテーブルに2回結合して、間隔の開始と終了を表す整数にコンテキストを与えることができます。
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
パフォーマンスの問題の紹介
時間クエリの問題は、テーブルから読み取るときに、SQL Serverが使用できるインデックスは1つだけであり、片側からの結果の候補ではない行を正常に削除してから、残りのデータをスキャンできることです。たとえば、特定の間隔と重複するテーブル内のすべての間隔を見つける必要があります。最初の間隔の始まりが2番目の間隔の終わり以下で、2番目の間隔の始まりが最初の間隔の終わり以下の場合、または数学的に(b1≤e2)の場合、2つの間隔が重なることを覚えておいてください。 AND(b2≤e1)。
次のクエリは、間隔(10、30)と重複するすべての間隔を検索しました。 2番目の条件(b2≤e1)は、読みやすくするために(e1≥b2)になっていることに注意してください(表の間隔の開始と終了は常に条件の左側にあります)。指定された、または検索された間隔は、テーブル内のすべての間隔のタイムラインの先頭にあります。
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);>
クエリは36の論理読み取りを使用しました。実行プランを確認すると、クエリがidx_bインデックスのインデックスシークをシーク述語[tempdb]。[dbo]。[Intervals] .b <=Scalar Operator((30))で使用し、スキャンしたことがわかります。行を選択し、残差述語[tempdb]。[dbo]。[Intervals]。[e]> =(10)を使用して結果の行を選択します。検索された間隔はタイムラインの先頭にあるため、seek述語は行の大部分を正常に削除しました。表のいくつかの間隔だけが、開始点が30以下になっています。
検索された間隔がタイムラインの最後にある場合、SQL Serverがシークにidx_eインデックスを使用するだけで、同様に効率的なクエリが得られます。ただし、次のクエリが示すように、検索された間隔がタイムラインの中央にある場合はどうなりますか?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
今回、クエリは111の論理読み取りを使用しました。テーブルが大きくなると、最初のクエリとの違いはさらに大きくなります。実行プランを確認すると、SQLServerがidx_eインデックスを[tempdb]。[dbo]。[Intervals].e> =Scalar Operator((570))seekpredicateおよび[tempdb]。[で使用していることがわかります。 dbo]。[間隔]。[b]<=(590)残差述語。シーク述語は、一方の側からの行の約半分を除外し、もう一方の側からの行の半分はスキャンされ、結果の行が残りの述語で抽出されます。
拡張T-SQLソリューション
単一のインデックスを使用して、検索された間隔の両側から行を削除するためにそのインデックスを使用するソリューションがあります。次の図は、このロジックを示しています。
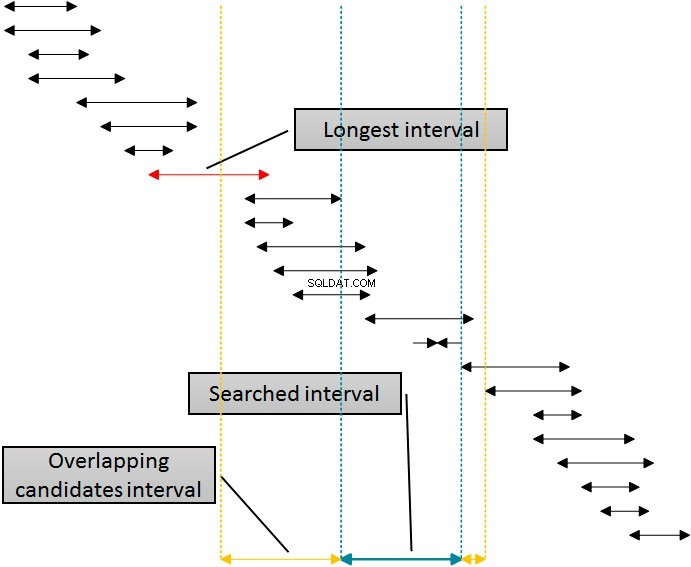
図の間隔は、SQLServerによるidx_bインデックスの使用法を表す下限でソートされています。指定された(検索された)間隔の右側から間隔を削除するのは簡単です。開始が指定された間隔の終了より少なくとも1単位大きい(右側にある)すべての間隔を削除するだけです。この境界は、右端の点線で示されている図で確認できます。ただし、左から削除する方が複雑です。同じインデックス、つまり左から削除するためのidx_bインデックスを使用するには、クエリのWHERE句のテーブルの間隔の先頭を使用する必要があります。少なくとも、図でコールアウトでマークされている表の最長の間隔の長さについては、指定された(検索された)間隔の先頭から離れて左側に移動する必要があります。左の黄色い線の前から始まる間隔は、指定された(青い)間隔と重なることはできません。
最長の間隔の長さが20であることはすでにわかっているので、非常に簡単な方法で拡張クエリを記述できます。
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
このクエリは、20個の論理読み取りのみで前の行と同じ行を取得します。実行プランを確認すると、シーク述語Seek Keys [1]でidx_bが使用されていることがわかります。開始:[tempdb]。[dbo]。[Intervals] .b> =Scalar Operator((550)) 、End:[tempdb]。[dbo]。[Intervals] .b <=Scalar Operator((590))。これにより、タイムラインの両側から行が正常に削除され、残りの述語[tempdb]。[dbo]が削除されました。 [Intervals]。[e]>=(570)AND[tempdb]。[dbo]。[Intervals]。[e]<=(610)を使用して、非常に限られた部分スキャンから行を選択しました。
もちろん、idx_eインデックスがより役立つ場合をカバーするために、図を裏返すこともできます。このインデックスを使用すると、左からの削除は簡単です。指定された間隔の開始前に少なくとも1単位終了するすべての間隔を削除します。今回は、右からの削除がより複雑になります。テーブル内の間隔の終わりは、指定された間隔の終わりにテーブル内のすべての間隔の最大長を加えたものよりも右に置くことはできません。
このパフォーマンスは、表の特定のデータの結果であることに注意してください。間隔の最大長は20です。このようにして、SQLServerは両側から間隔を非常に効率的に削除できます。ただし、テーブルに長い間隔が1つしかない場合、SQL Serverは、使用するインデックスに応じて、左右どちらの側からも多くの行を削除できないため、コードの効率が大幅に低下します。 。とにかく、実際には、間隔の長さは何度も変化しないので、この最適化手法は、特に単純であるため、非常に役立つ可能性があります。
結論
これは1つの可能な解決策にすぎないことに注意してください。 Itzik Ben-Gan(https://sqlmag.com/t-sql/)によるSQL Serverの間隔クエリの記事で、最長の間隔の長さに関係なく、より複雑なソリューションを見つけることができます。 sql-server-interval-queries)。ただし、拡張T-SQLは本当に気に入っています。 この記事で紹介したソリューション。解決策は非常に簡単です。重複するクエリのWHERE句に2つの述語を追加するだけです。しかし、これは可能性の終わりではありません。次の2つの記事では、さらに多くのソリューションを紹介するので、最適化ツールボックスに豊富な可能性がありますので、しばらくお待ちください。
便利なツール:
dbForge Query Builder for SQL Server –ユーザーは、手動でコードを記述しなくても、直感的なビジュアルインターフェイスを介して複雑なSQLクエリをすばやく簡単に作成できます。