SELECT*FROMテーブル形式の一般的なクエリでは不十分な場合があります。クエリのデータが1つのテーブルではなく複数のテーブルにある場合、または一度に複数の選択パラメータを指定する必要がある場合は、より高度なクエリが必要になります。
この記事では、このようなクエリを作成する方法を説明し、複雑なSQLクエリの例を示します。
複雑なクエリはどのように見えますか?
まず、SQLクエリを作成するための条件を定義しましょう。特に、次の選択パラメータを使用する必要があります。
- データを抽出するテーブルの名前;
- データベースに変更を加えた後に元のフィールドに戻す必要があるフィールドの値。
- テーブル間の関係;
- サンプリング条件;
- 補助的な選択基準(制限、情報の提示方法、並べ替えの種類)。
このトピックをよりよく理解するために、次の4つの簡単なテーブルを使用する例を考えてみましょう。最初の行は、複雑なクエリで外部キーとして機能するテーブルの名前です。これについては、例を挙げてさらに詳しく検討します。
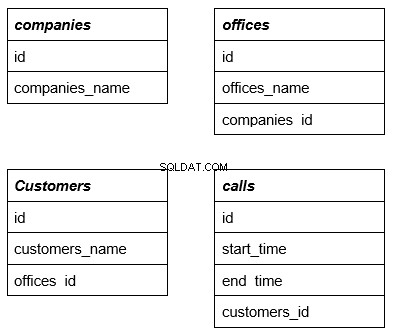
各テーブルには、他のいくつかのテーブルに関連する行があります。さらに必要な理由を説明します。
それでは、基本的なSQLクエリを見てみましょう。
SELECT * FROM companies WHERE companies_name %STARTSWITH 'P';%STARTSWITH 述語は、指定された1つまたは複数の文字で始まる行を選択します。
結果は次のようになります:

それでは、複雑なSQLクエリについて考えてみましょう。
SELECT
companies.companies_name,
SUM(CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
HAVING AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) > (SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls)
ORDER BY calls DESC, companies.id ASC;
結果は次の表になります。

この表には、会社、対応する電話の数、およびおおよその期間が示されています。
さらに、平均通話時間が他の会社の平均通話時間よりも長い会社名のみが一覧表示されます。
複雑なSQLクエリを作成するための主なルールは何ですか?
複雑なクエリを作成するための多目的アルゴリズムを作成してみましょう。
まず、クエリに参加するデータで構成されるテーブルを決定する必要があります。
上記の例には、企業が含まれます および呼び出し テーブル。必要なデータを含むテーブルが互いに直接関連していない場合は、それらを結合する中間テーブルも含める必要があります。
このため、オフィスなどのテーブルも接続します および顧客 、外部キーを使用します。したがって、この例のテーブルを使用したクエリの結果には、常に次の行が含まれます。
SELECT
...
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
...;
After that, you must test the correctness of the behavior in the following part of the query:
SELECT * FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id;
組み合わせた表は、3つの最も重要なポイントを示しています。
- SELECTの後のフィールドのリストに注意してください。結合されたテーブルからデータを読み取る操作では、結合するテーブルの名前を nameで指定する必要があります。 フィールド。
- 複雑なクエリには常にメインテーブルがあります(会社 )。ほとんどのフィールドはそこから読み取られます。この例では、添付のテーブルは3つのテーブル(オフィス)を使用しています。 、お客様 、および呼び出し 。名前はJOIN演算子の後に決定されます。
- 2番目のテーブルの名前を指定することに加えて、結合を実行するための条件を必ず指定してください。この状態についてさらに説明します。
- クエリは、多数の行を含むテーブルを表示します。中間結果が表示されるため、ここで公開する必要はありません。ただし、いつでも自分で出力を確認できます。これは、最終結果の間違いを避けるのに役立つため、非常に重要です。
次に、各企業内およびすべての企業間の通話時間を比較するクエリの部分を見てみましょう。すべての通話の平均時間を計算する必要があります。次のクエリを使用します:
SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls
DATEDIFFを使用したことに注意してください 指定された期間の差を出力する関数。この場合、平均通話時間は335秒です。
それでは、すべての企業からの通話に関するデータをクエリに追加しましょう。
SELECT
companies.companies_name,
SUM(CASE WHEN calls.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
ORDER BY calls DESC, companies.id ASC;
このクエリでは、
- SUM(calls.idがNULLでない場合は1 ELSE 0 END) –不要な操作を避けるために、会社の通話数がゼロでない場合は、既存の通話のみを要約します。これは、null値が発生する可能性のある大きなテーブルでは非常に重要です。
- AVG(ISNULL(DATEDIFF(SECOND、calls.start_time、calls.end_time)、0)) –クエリは上記のAVGクエリと同じです。ただし、ここでは ISNULLを使用します NULLを0に置き換える演算子。呼び出しがまったくない企業に必要です。
結果:
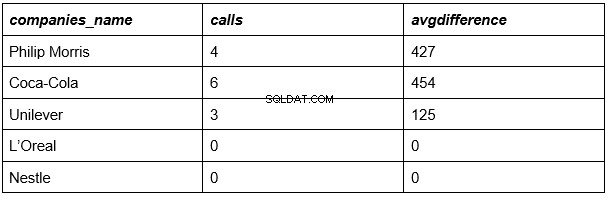
ほぼ完了です。上記の表は、会社のリスト、各会社に対応する通話数、および各会社の平均通話時間を示しています。
残っているのは、最後の列の数値を、すべての企業からのすべての通話の平均時間(335秒)と比較することだけです。
最初に提示したクエリを入力する場合は、 HAVINGを追加するだけです。 一部、あなたはあなたが必要とするものを手に入れるでしょう。
将来、既存の複雑なSQLクエリを修正する必要があるときに混乱しないように、各行にコメントを追加することを強くお勧めします。
最終的な考え
複雑なSQLクエリにはそれぞれ個別のアプローチが必要ですが、そのようなクエリのほとんどの準備にはいくつかの推奨事項が適しています。
- クエリに参加するテーブルを決定します。
- 単純な部分から複雑なクエリを作成します。
- クエリの精度を部分的に順番に確認します。
- 小さなテーブルでクエリの精度をテストします。
- 記号「-」を使用して、オペランドを含む各行に詳細なコメントを書き込みます。
専用のツールを使用すると、この作業がはるかに簡単になります。その中でも、クエリビルダーを使用することをお勧めします。これは、ビジュアルモードで最も複雑なクエリをはるかに高速に構築できるビジュアルツールです。このツールは、スタンドアロンソリューションとして、または多機能のdbForge Studio forSQLServerの一部として利用できます。
この記事がこの特定の問題の明確化に役立つことを願っています。