SQL Server DBAとして、インデックス構造は特定のクエリ(または一連のクエリ)のパフォーマンスを劇的に向上させることができると聞いています。それでも、次のように、多くのDBAが見落としている特定の詳細があります。
- インデックス構造が断片化され、パフォーマンスの低下の問題が発生する可能性があります。
- データベーステーブルにインデックス構造が展開されると、SQL Serverは、そのテーブルに対して書き込み操作が行われるたびにインデックス構造を更新します。これは、インデックスに準拠する列が影響を受ける場合に発生します。
- SQL Server内には、特定のインデックス構造の統計が最後に更新された時期(ある場合)を知るために使用できるメタデータがあります。統計が不十分または古くなっていると、特定のクエリのパフォーマンスに影響を与える可能性があります。
- SQL Server内にはメタデータがあり、読み取り操作によって消費されたインデックス構造、またはSQLServer自体による書き込み操作によって更新されたインデックス構造を知るために使用できます。この情報は、書き込み量が読み取り量を大幅に超えるインデックスがあるかどうかを知るのに役立ちます。これは、維持するのにそれほど有用ではないインデックス構造である可能性があります。*
*この特定のメタデータを保持するシステムビューは、SQL Serverインスタンスが再起動されるたびに消去されるため、その概念からの情報ではないことに注意することが非常に重要です。
これらの詳細の重要性のために、私は彼/彼女の環境のインデックス構造に関する情報を追跡し、可能な限り積極的に行動するためのストアドプロシージャを作成しました。
最初の考慮事項
- このストアドプロシージャを実行するアカウントに十分な権限があることを確認してください。おそらく、sysadminのものから始めて、SPが正しく機能するために必要な最小限の特権をユーザーが持っていることを確認するために、可能な限り細かく調整することができます。
- データベースオブジェクト(データベーステーブルとストアドプロシージャ)は、スクリプトの実行時に選択されたデータベース内に作成されるため、慎重に選択してください。
- スクリプトは、エラーをスローせずに複数回実行できるように作成されています。ストアドプロシージャには、SQL Server2016SP1以降で使用可能なCREATEORALTERPROCEDUREステートメントを使用しました。
- 別の命名規則を使用する場合は、作成したデータベースオブジェクトの名前を自由に変更してください。
- ストアドプロシージャによって返されたデータを永続化することを選択すると、ターゲットテーブルが最初に切り捨てられるため、最新の結果セットのみが保存されます。何らかの理由で(おそらく履歴情報を保持するために)これを異なる動作にする場合は、必要な調整を行うことができます。
ストアドプロシージャの使用方法
- T-SQLコード(この記事内で利用可能)をコピーして貼り付けます。
- SPは2つのパラメーターを想定しています。
- @ persistData:DBAが出力をターゲットテーブルに保存する場合は「Y」、DBAが出力を直接表示する場合は「N」。
- @db:'all'はすべてのデータベース(システムとユーザー)の情報を取得し、'user'はユーザーデータベースをターゲットにし、'system'はシステムデータベース(tempdbを除く)のみをターゲットにし、最後に特定のデータベース。
提示されたフィールドとその意味
- dbName: インデックスオブジェクトが存在するデータベースの名前。
- schemaName: インデックスオブジェクトが存在するスキーマの名前。
- tableName: インデックスオブジェクトが存在するテーブルの名前。
- indexName: インデックス構造の名前。
- タイプ: インデックスのタイプ(例:クラスター化、非クラスター化)。
- alllocation_unit_type: 参照するデータのタイプを指定します(行内データ、LOBデータなど)。
- 断片化: インデックス構造が現在持っている断片化の量(%)。
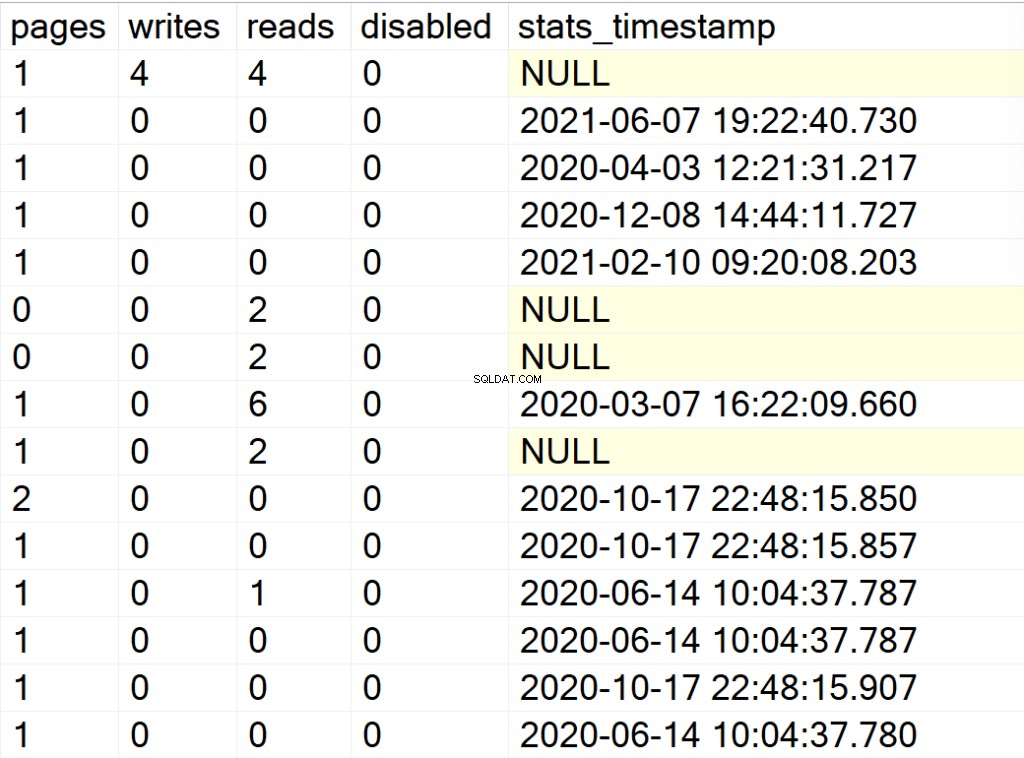
- ページ: インデックス構造を形成する8KBページの数。
- 書き込み: SQLServerインスタンスが最後に再起動されてからインデックス構造が経験した書き込みの数。
- 読み取り: SQLServerインスタンスが最後に再起動されてからインデックス構造が経験した読み取りの数。
- 無効: インデックス構造が現在無効になっている場合は1、構造が有効になっている場合は0。
- stats_timestamp: 特定のインデックス構造の統計が最後に更新されたときのタイムスタンプ値(まったく更新されていない場合はNULL)。
- data_collection_timestamp: 「Y」が@persistDataパラメータに渡された場合にのみ表示され、SPがいつ実行され、情報がDBA_Indexesテーブルに正常に保存されたかを知るために使用されます。
実行テスト
ストアドプロシージャのいくつかの実行を示して、そこから何が期待できるかを理解できるようにします。
*スクリプトの完全なT-SQLコードはこの記事の最後にあります。次のセクションに進む前に、必ず実行してください。
*結果セットは幅が広すぎて1つのスクリーンショットにうまく収まらないため、完全な情報を提示するために必要なすべてのスクリーンショットを共有します。
/*すべてのシステムおよびユーザーデータベースのすべてのインデックス情報を表示します*/
EXEC GetIndexData @persistData = 'N',@db = 'all'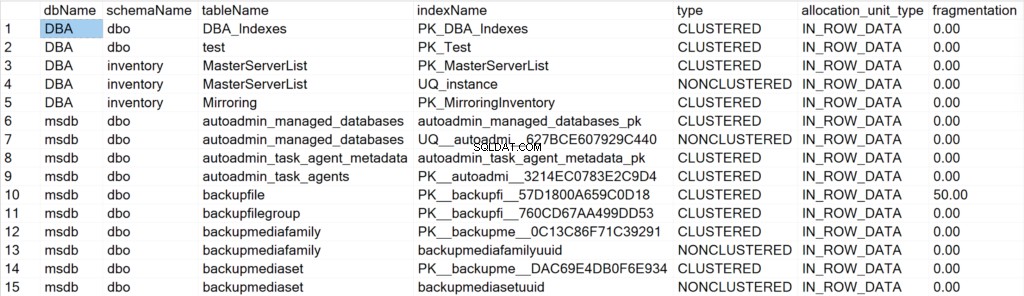
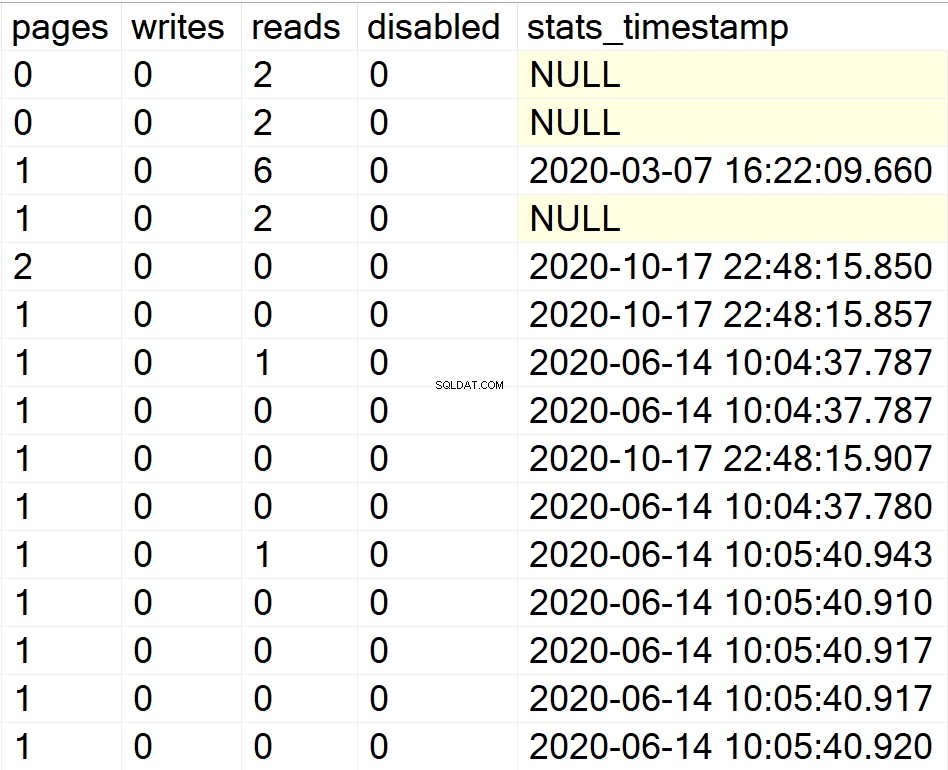
/*すべてのシステムデータベースのすべてのインデックス情報を表示します*/
EXEC GetIndexData @persistData = 'N',@db = 'system'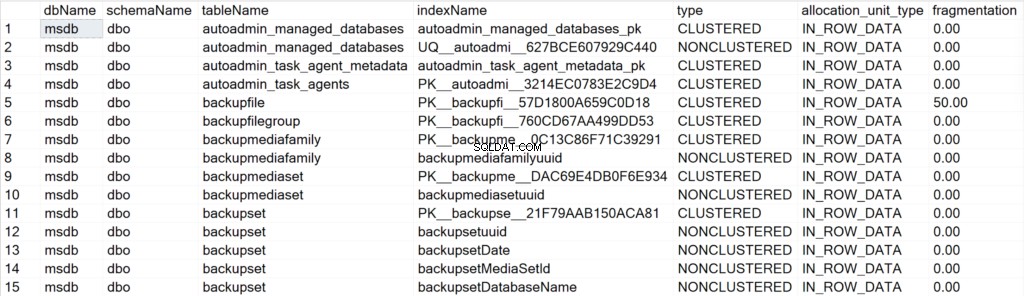
/*すべてのユーザーデータベースのすべてのインデックス情報を表示します*/
EXEC GetIndexData @persistData = 'N',@db = 'user'
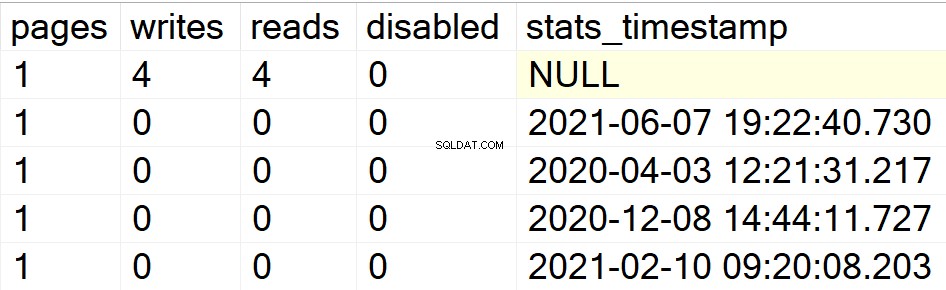
/*特定のユーザーデータベースのすべてのインデックス情報を表示します*/
以前の例では、データベースDBAのみが、インデックスを含む唯一のユーザーデータベースとして表示されていました。したがって、同じインスタンスに配置している別のデータベースにインデックス構造を作成して、SPがその機能を実行するかどうかを確認できるようにします。
EXEC GetIndexData @persistData = 'N',@db = 'db2'
これまでに示したすべての例は、@ dbパラメーターのオプションのさまざまな組み合わせについて、データを永続化したくない場合に得られる出力を示しています。無効なオプションを指定した場合、またはターゲットデータベースが存在しない場合、出力は空になります。しかし、DBAがデータベーステーブルにデータを保持したい場合はどうでしょうか。調べてみましょう。
* @ dbパラメータの残りのオプションが上記でほとんど紹介されており、結果は同じですがデータベーステーブルに保持されているため、1つのケースでSPを実行します。
EXEC GetIndexData @persistData = 'Y',@db = 'user'
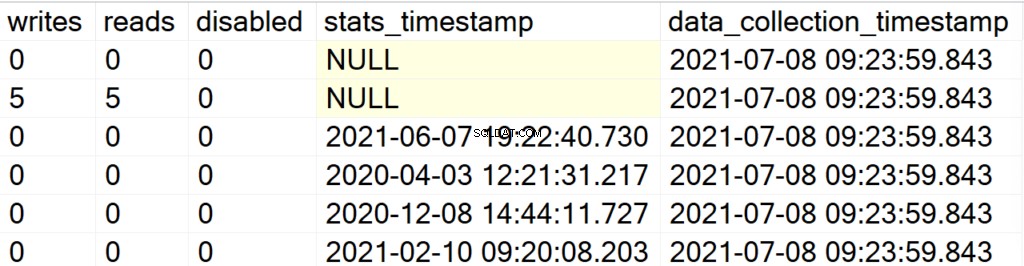
これで、ストアドプロシージャを実行した後、出力は得られません。結果セットを照会するには、DBA_Indexesテーブルに対してSELECTステートメントを発行する必要があります。ここでの主な魅力は、事後分析のために取得した結果セットをクエリできることと、表示しているデータがどれくらい最近/古いかを知らせるdata_collection_timestampフィールドを追加できることです。
サイドクエリ
ここで、DBAにより多くの価値を提供するために、テーブルに保持されているデータから有用な情報を取得するのに役立つクエリをいくつか用意しました。
*全体的に非常に断片化されたインデックスを見つけるためのクエリ。
*フィッティングを検討する%の数を選択してください。
* 1500ページは、Microsoftの推奨に基づいて、私が読んだ記事に基づいています。
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*環境内で無効になっているインデックスを見つけるためのクエリ。
SELECT * FROM DBA_Indexes WHERE disabled = 1;*少なくともSQLServerインスタンスが最後に再起動されてからではなく、クエリであまり使用されていないインデックス(ほとんどが非クラスター化)を見つけるためのクエリ。
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*更新されていないか古い統計を見つけるためのクエリ。
*環境内で何が古いかを判断するため、それに応じて日数を調整してください。
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;ストアドプロシージャの完全なコードは次のとおりです。
*スクリプトの最初に、各パラメーターに値が渡されない場合にストアドプロシージャが想定するデフォルト値が表示されます。
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GO結論
- このSPは、サポート下のすべてのSQL Serverインスタンスに展開し、サポートされているインスタンスのスタック全体にアラートメカニズムを実装できます。
- この情報を比較的頻繁に照会するエージェントジョブを実装する場合は、ゲームのトップに留まり、サポートされている環境内のインデックス構造を管理できます。
- サンドボックス環境でこのメカニズムを適切にテストし、本番環境への展開を計画している場合は、アクティビティの少ない期間を選択してください。
インデックスの断片化の問題は、注意が必要でストレスの多いものになる可能性があります。それらを見つけて修正するには、ここからダウンロードできるdbForgeIndexManagerなどのさまざまなツールを使用できます。